




 本文详细介绍了Python的基本概念,包括字符串比较、编码、格式化、列表、元组、输入输出操作、位运算符及进制转换等内容,是Python初学者的实用指南。
本文详细介绍了Python的基本概念,包括字符串比较、编码、格式化、列表、元组、输入输出操作、位运算符及进制转换等内容,是Python初学者的实用指南。
目录
字符串比较大小
1、字符串纯数字
比较原理:python中两个字符串对比大小的时候是按照ASCII码来比较的。先比较两个的第0个位置的字符,如果相等,则比较第1位,以此类推:
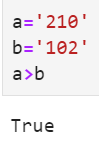
注意:只能比较等长度的字符串
 因为3 < 5
因为3 < 5
2、字符串字母
str1 = "abc";
str2 = "xyz";
str1>str2
true3、字符串数字+字母,按首字母进行比大小
s='a123'
t='b23'
if s>t:
print("s>t")
else:
print("s<t")
D:\study\python\test\venv\Scripts\python.exe D:/study/python/test/dd.py
s<t字符串和编码
a = 'ABC'# 解释器创建了字符串'ABC'和变量a,并把a指向'ABC':
b = a# 解释器创建了变量b,并把b指向a指向的字符串'ABC':
a = 'XYZ'# 解释器创建了字符串'XYZ',并把a的指向改为'XYZ',但b并没有更改:
print(b)UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:

浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:

所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
>>> ord('A')
65
>>> ord('中')
20013
>>> chr(66)
'B'
>>> chr(25991)
'文'由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b'ABC'要注意区分'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> '中文'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b'ABC'.decode('ascii')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'如果bytes中只有一小部分无效的字节,可以传入errors='ignore'忽略错误的字节:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8', errors='ignore')
'中'要计算str包含多少个字符,可以用len()函数:
>>> len('ABC')
3
>>> len('中文')
2
len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数:
>>> len(b'ABC')
3
>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6
>>> len('中文'.encode('utf-8'))
6由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码:
格式化
>>> print('%3d' % 5)# 表示输出3位整型数, 不够3位右对齐。
5
>>> print('%5d' % 5)
5
>>> print('%05d' % 5)# 是否补0
00005
>>> print('%.2f ' % 3.1415926)
3.14 list
>>> classmates = ['Michael', 'Bob', 'Tracy']
>>> classmates
['Michael', 'Bob', 'Tracy']
>>> len(classmates)
3
>>> classmates[0]
'Michael'
>>> classmates[1]
'Bob'
>>> classmates[2]
'Tracy'
>>> classmates[-1]# 直接获取最后一个元素,倒数第二、三以此类推
'Tracy'
>>> classmates.append('Adam')# list是一个可变的有序表,所以,可以往list中追加元素到末尾:
>>> classmates
['Michael', 'Bob', 'Tracy', 'Adam']
>>> classmates.insert(1, 'Jack')# 把元素插入到指定的位置,比如索引号为1的位置
>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy', 'Adam']
>>> classmates.pop()# 要删除list末尾的元素,用pop()方法:
'Adam'
>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy']
>>> classmates.pop(1)# 删除指定位置的元素,用pop(i)方法,其中i是索引位置:
'Jack'
>>> classmates
['Michael', 'Bob', 'Tracy']list元素也可以是另一个list,比如:
>>> s = ['python', 'java', ['asp', 'php'], 'scheme']
>>> len(s)
4
要注意s只有4个元素,其中s[2]又是一个list,如果拆开写就更容易理解了:
>>> p = ['asp', 'php']
>>> s = ['python', 'java', p, 'scheme'] 要拿到'php'可以写p[1]或者s[2][1]
tuple
一种有序列表叫元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改。它也没有append(),insert()这样的方法。其他获取元素的方法和list是一样的。
只有1个元素的tuple定义时必须加一个逗号,,来消除歧义:
>>> t = (1,)
>>> t
(1,)来看一个“可变的”tuple:
>>> t = ('a', 'b', ['A', 'B'])
>>> t[2][0] = 'X'
>>> t[2][1] = 'Y'
>>> t
('a', 'b', ['X', 'Y'])
这个tuple定义的时候有3个元素,分别是'a','b'和一个list。不是说tuple一旦定义后就不可变了吗?怎么后来又变了?
别急,我们先看看定义的时候tuple包含的3个元素:

当我们把list的元素'A'和'B'修改为'X'和'Y'后,tuple变为:

表面上看,tuple的元素确实变了,但其实变的不是tuple的元素,而是list的元素。tuple一开始指向的list并没有改成别的list,所以,tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向'a',就不能改成指向'b',指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的!
I/O
在文件上传的时候遇到个问题,就是 'w+' 和 'wb' 在文件上传的时候是否回车。
根据项目的实景情况模拟一下区别。
区别
- 'w+' 是文本写入。
- w 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
- wb 'wb'是字节写入。以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
看代码。首先在window 操作系统下。
1.字节
# utf-8
# 模拟上传的文件内容
readFile = b'hello\r\nwolrd'
temp = open('t', 'wb')
temp.write(readFile)
temp.close()结果
hello
wolrd2.字符串
readFile = 'hello\r\nwolrd'
temp = open('t', 'w+')
temp.write(readFile)
temp.close()结果
hello
wolrd可以看到在用文本写入的情况下,多了一个空行。
同样的代码在Linux上就没有出现,所以这个问题只有在windows上有。




Python位运算符
and、or
x y
1 and 0 0
0 and 5 0
1 and 2 2
and:x=0则0,x!=0则y
1 or 5 1
0 or 6 6
3 or 0 3
or:x=0则y,x!=0则xhttps://www.runoob.com/python/python-operators.html
#!/usr/bin/python
# -*- coding: UTF-8 -*-
a = 60 # 60 = 0011 1100
b = 13 # 13 = 0000 1101
c = 0
c = a & b; # 12 = 0000 1100
c = a | b; # 61 = 0011 1101
c = a ^ b; # 49 = 0011 0001
c = ~a; # -61 = 1100 0011
c = a << 2; # 240 = 1111 0000
c = a >> 2; # 15 = 0000 1111python 进制
Python 将二进制值转换为整数(十进制)
def BinToDec(value):
try:
return int(value, 2)
except ValueError:
return "Invalid binary Value"
input1 = "11110000"
print(input1, "as decimal: ", BinToDec(input1))
11110000 as decimal: 240python实现进制转换(二、八、十六进制;十进制)
(一)十进制整数转为二、八、十六进制
1、format实现转换
>>> format(2,"b") # (10进制的)2转二进制
'10'
>>> format(9,"o") # (10进制的)9转八进制
'11'
>>> format(17,"x") # (10进制的)17转十六进制
'11'format(integer, 'x') 将integer转换为16进制,不带0x。integer为整型,'x'可换为'o','b','d'相对应八、二、十进制。
2、内置函数bin、oct、hex实现转换2、8、16进制的字串
>>> bin(3) # (10进制的)3转二进制
'0b11'
>>> oct(9) # (10进制的)9转8进制
'0o11'
>>> hex(17) # (10进制的)17转16进制
'0x11'内置函数bin、oct、hex实现转换,会带进制前缀'0b'、'0o'、'0x'(二)二、八、十六进制转为十进制
>>> int("11",2) # (2进制的)"11"转十进制
3
>>> int("11",8) # (8进制的)"11"转十进制
9
>>> int("11",16) # (16进制的)"11"转十进制
17int(string, number) 将任意进制的s(string类型)转换为十进制。s与number的进制类型需匹配,如s是16进制,则number=16,否侧会出错。若s为16进制,0x可带可不带,其他进制同。
python 以二进制格式输入数字
try:
num = int(input("Input binary value: "), 2)
print("num (decimal format):", num)
print("num (binary format):", bin(num))
except ValueError:
print("Please input only binary value...")

















 864
864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









