




labuladong算法学习 笔记(公众号:labuladong)
此篇笔记包含以下内容
一、图 - 高级的多叉树
二、判断有向图是否存在环
三、拓扑排序
四、二分图
五、Union-Find 并查集算法
六、最小生成树 – Kruskal 算法
七、最小生成树 – Prim算法
八、Dijkstra 算法模板
九、名流问题
图 - 高级的多叉树
1. 图的实现

邻接表很直观,我把每个节点x的邻居都存到一个列表里,然后把x和这个列表关联起来,这样就可以通过一个节点x找到它的所有相邻节点。编程时我用的是 list *lis = new list[n];
邻接矩阵则是一个二维布尔数组,我们权且成为matrix,如果节点x和y是相连的,那么就把matrix[x][y]设为true。如果想找节点x的邻居,去扫一圈matrix[x][…]就行了。
邻接表的主要优势是节约存储空间;邻接矩阵的主要优势是可以迅速判断两个节点是否相邻。

2. 图的遍历
/* 多叉树遍历框架 */
void traverse(TreeNode root) {
if (root == null) return;
for (TreeNode child : root.children)
traverse(child);
}
/* 图遍历框架 */
Graph graph;
boolean[] visited;
void traverse(Graph graph, int s) {
if (visited[s]) return;
// 经过节点 s
visited[s] = true;
for (TreeNode neighbor : graph.neighbors(s))
traverse(neighbor);
// 离开节点 s
}
遍历框架需要一个visited数组进行剪枝。
// 前者会正确打印所有节点的进入和离开信息
// 而后者唯独会少打印整棵树根节点的进入和离开信息
// 回溯算法用的后者,学到这再说
void traverse(TreeNode root) {
if (root == null) return;
System.out.println("enter: " + root.val);
for (TreeNode child : root.children) {
traverse(child);
}
System.out.println("leave: " + root.val);
}
void traverse(TreeNode root) {
if (root == null) return;
for (TreeNode child : root.children) {
System.out.println("enter: " + child.val);
traverse(child);
System.out.println("leave: " + child.val);
}
}
3. 例题:力扣 797. 所有可能的路径

注:像这道题,已经明确图中无环,所以不用辅助数组,就一个DFS 。
class Solution {
public:
vector<vector<int>> res;
int n;
vector<vector<int>> allPathsSourceTarget(vector<vector<int>>& graph) {
n = graph.size();
vector<int> con;
DFS(graph,0,con);
return res;
}
void DFS(vector<vector<int>>& graph,int p,vector<int>& con){
con.push_back(p);
if(p==n-1){
res.push_back(con);
}
for(int t : graph[p]){
DFS(graph,t,con);
}
con.pop_back();
}
};
判断有向图是否存在环
例题:力扣 207. 课程表
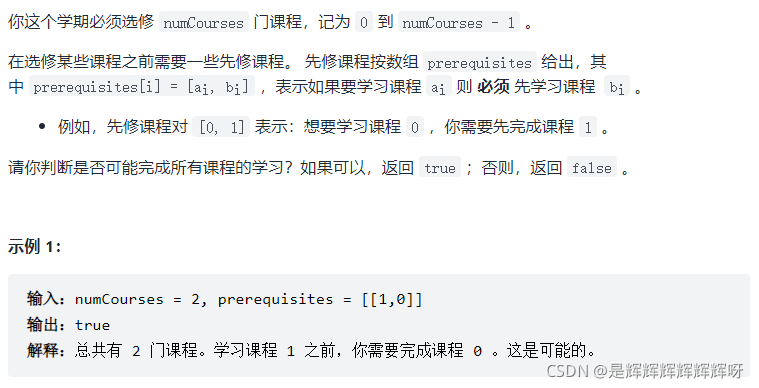
注:把依赖关系转为有向图,只要不存在环就可以修完所有课程。那这道题可以用DFS并借助另一个标记数组判断是否出现环。不同于visited数组,visited数组是判断已经访问过这个节点了,后续不用再看了,相当于剪枝了。而这个标记数组是记录回溯路径的。
class Solution {
public:
int *visited;
int *path;
bool hasCircle = false;
bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {
visited = new int[numCourses];
path = new int[numCourses];
memset(visited,0,sizeof(int)*numCourses);
memset(path,0,sizeof(int)*numCourses);
list<int> graph[numCourses];
buildGraph(prerequisites,graph);
for(int i=0;i<numCourses;i++){
traverse(i,graph);
}
return !hasCircle;
}
void buildGraph( vector<vector<int>>& prerequisites,list<int> graph[] ){
for(vector<int> vec : prerequisites){
graph[vec[1]].push_back(vec[0]);
}
}
void traverse(int p,list<int> graph[]){
if(path[p]==1){
hasCircle = true;
return ;
}
// if里面加hasCircle也是剪枝的作用,不做无用功,有一个环就可以停止了
// 也可以加在下面的for里面
if(visited[p]==1 || hasCircle){
return ;
}
visited[p] = 1;
path[p] = 1;
for(int i : graph[p]){
traverse(i,graph);
}
path[p] = 0;
}
};
编程时的问题:raverse中的两个if一开始写反了,后来意识到错误,应该先判断环。visited[]只是剪枝用的。
引发问题:如果让记录这个环怎么办??① 每访问一个结点就将其入全局栈,如果发现下一个要访问的元素在栈里面,就一直出栈直到该结点。② 直接利用递归函数就在栈里面,维护一个全局变量,访问到了正在访问的元素就把这个全局变量置为该元素的序号,然后一路回退,边回退边输出结点,直到访问到该全局变量标记的结点。(摘自东哥微信公众号文章 - bor的解答)
拓扑排序
1. 定义
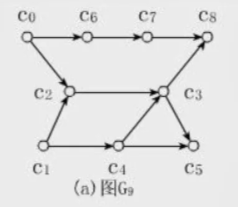
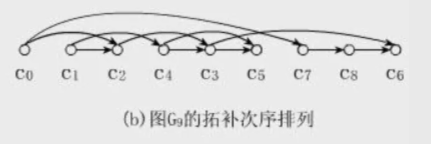
直观地说就是,让你把一幅图「拉平」,而且这个「拉平」的图里面,所有箭头方向都是一致的,比如上图所有箭头都是朝右的。
很显然,如果一幅有向图中存在环,是无法进行拓扑排序的,因为肯定做不到所有箭头方向一致;反过来,如果一幅图是「有向无环图」,那么一定可以进行拓扑排序。
2. 例题:力扣 210. 课程表II

注:这道题首先要确保没有环,然后再存储合理选修顺序。
解:将后序遍历的结果进行反转,就是拓扑排序的结果。
答:为什么后序遍历的反转结果就是拓扑排序呢?
// 二叉树遍历框架
void traverse(TreeNode root) {
// 前序遍历代码位置
traverse(root.left)
// 中序遍历代码位置
traverse(root.right)
// 后序遍历代码位置
}
二叉树的后序遍历是什么时候?遍历完左右子树之后才会执行后序遍历位置的代码。换句话说,当左右子树的节点都被装到结果列表里面了,根节点才会被装进去。
后序遍历的这一特点很重要,之所以拓扑排序的基础是后序遍历,是因为一个任务必须在等到所有的依赖任务都完成之后才能开始开始执行。
总之:要记住拓扑排序就是后序遍历反转之后的结果,且拓扑排序只能针对有向无环图,进行拓扑排序之前要进行环检测。这两个过程可同步进行。
class Solution {
public:
vector<int> res;
int *visited;
int *path;
bool hasCircle = false;
vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites) {
visited = new int[numCourses];
path = new int[numCourses];
memset(visited,0,sizeof(int)*numCourses);
memset(path,0,sizeof(int)*numCourses);
list<int> graph[numCourses];
buildGraph(prerequisites,graph);
for(int i=0;i<numCourses;i++){
traverse(i,graph);
}
if(hasCircle){
res.clear();
}else{
reverse(res.begin(),res.end());
}
return res;
}
void buildGraph( vector<vector<int>>& prerequisites,list<int> graph[] ){
for(vector<int> vec : prerequisites){
graph[vec[1]].push_back(vec[0]);
}
}
void traverse(int p,list<int> graph[]){
if(path[p]==1){
hasCircle = true;
return ;
}
if(visited[p]==1 || hasCircle){
return ;
}
visited[p] = 1;
path[p] = 1;
for(int i : graph[p]){
traverse(i,graph);
}
res.push_back(p);
path[p] = 0;
}
};
二分图
1. 定义
百度百科定义:二分图的顶点集可分割为两个互不相交的子集,图中每条边依附的两个顶点都分属于这两个子集,且两个子集内的顶点不相邻。

二分图就是图的双色问题,用两种颜色将图中的所有顶点着色,且使得任意一条边的两个端点的颜色都不相同,如若可以做到,即是二分图。
2. 二分图的判定思路
说白了就是遍历一遍图,一边遍历一遍染色,看看能不能用两种颜色给所有节点染色,且相邻节点的颜色都不相同。
/* 二叉树遍历框架 */
void traverse(TreeNode root) {
if (root == null) return;
traverse(root.left);
traverse(root.right);
}
/* 多叉树遍历框架 */
void traverse(Node root) {
if (root == null) return;
for (Node child : root.children)
traverse(child);
}
/* 图遍历框架 */
boolean[] visited;
void traverse(Graph graph, int v) {
// 防止走回头路进入死循环
if (visited[v]) return;
// 前序遍历位置,标记节点 v 已访问
visited[v] = true;
for (TreeNode neighbor : graph.neighbors(v))
traverse(graph, neighbor);
}
二分图代码逻辑:
/* 图遍历框架 */
void traverse(Graph graph, boolean[] visited, int v) {
visited[v] = true;
// 遍历节点 v 的所有相邻节点 neighbor
for (int neighbor : graph.neighbors(v)) {
if (!visited[neighbor]) {
// 相邻节点 neighbor 没有被访问过
// 那么应该给节点 neighbor 涂上和节点 v 不同的颜色
traverse(graph, visited, neighbor);
} else {
// 相邻节点 neighbor 已经被访问过
// 那么应该比较节点 neighbor 和节点 v 的颜色
// 若相同,则此图不是二分图
}
}
}
3. 例题:力扣 785. 判断二分图


class Solution {
public:
bool *visited;
bool *color;
bool ok = true;
bool isBipartite(vector<vector<int>>& graph) {
int n = graph.size();
visited = new bool[graph.size()];
memset(visited,0,sizeof(bool)*n);
color = new bool[graph.size()];
memset(color,0,sizeof(bool)*n);
for(int i=0;i<graph.size();i++){
if(!visited[i]){
traverse(graph,i);
}
}
return ok;
}
void traverse(vector<vector<int>>& graph,int p){
if(!ok){
return ;
}
visited[p] = true;
for(int v:graph[p]){
if(!visited[v]){
color[v] = !color[p];
traverse(graph,v);
}else{
if(color[p]==color[v]){
ok = false;
return ;
}
}
}
}
};
4. 例题:力扣 886. 可能的二分法
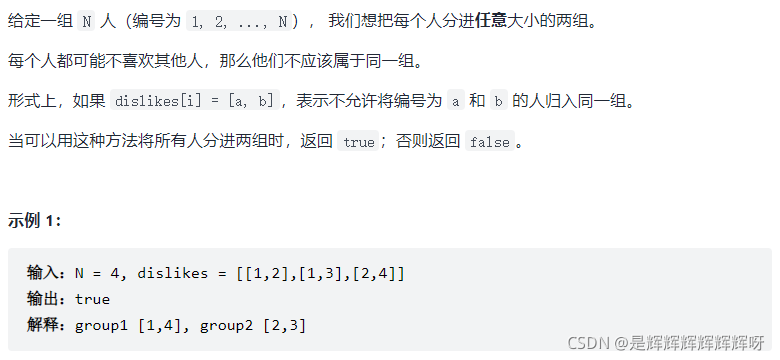
注:首先要构造一个图,不喜欢的两人间建边,最后让这条边相邻的两个结点呈现不同颜色即可。
class Solution {
public:
bool ok = true;
bool *col;
bool *vis;
list<int> *graph;
bool possibleBipartition(int n, vector<vector<int>>& dislikes) {
col = new bool[n+1];
memset(col,0,sizeof(bool)*(n+1));
vis = new bool[n+1];
memset(vis,0,sizeof(bool)*(n+1));
graph = new list<int>[n+1];
buildGraph(dislikes);
for(int i=1;i<=n;i++){
if(!vis[i]){
traverse(i);
}
}
return ok;
}
void buildGraph(vector<vector<int>>& dis){
for(vector<int> t : dis){
graph[t[0]].push_back(t[1]);
graph[t[1]].push_back(t[0]);
}
}
void traverse(int p){
if(!ok){
return ;
}
vis[p] = true;
for(int i : graph[p]){
if(!vis[i]){
col[i] = !col[p];
traverse(i);
}else{
if(col[i] == col[p]){
ok = false;
return ;
}
}
}
}
};
Union-Find 并查集算法
1. 平衡性优化:我们一开始就是简单粗暴的把p所在的树接到q所在的树的根节点下面,那么这里就可能出现「头重脚轻」的不平衡状况,比如下面这种局面:

长此以往,树可能生长得很不平衡。我们其实是希望,小一些的树接到大一些的树下面,这样就能避免头重脚轻,更平衡一些。解决方法是额外使用一个size数组,记录每棵树包含的节点数,我们不妨称为「重量」。
2. 路径压缩:(已学过)东哥解释戳这里
调用find函数每次向树根遍历的同时,顺手将树高缩短了,最终所有树高都不会超过 3。
3. 时间复杂度
Union-Find 算法的复杂度可以这样分析:构造函数初始化数据结构需要 O(N) 的时间和空间复杂度;连通两个节点union、判断两个节点的连通性connected、计算连通分量count所需的时间复杂度均为 O(1)。
4. C++ 实现
class UnionFind{
public:
int count;
int *parent;
int *size;
UnionFind(int n){
count = n;
parent = new int[n];
size = new int[n];
for(int i=0;i<n;i++){
parent[i] = i;
}
fill(size,size+n,1);
}
int find(int x){
while(x != parent[x]){
parent[x] = parent[parent[x]];
x = parent[x];
}
return x;
}
void Union(int x,int y){
int rootX = find(x);
int rootY = find(y);
if(rootX==rootY){
return ;
}
if(size[rootX]>size[rootY]){
parent[rootY] = rootX;
size[rootX] += size[rootY];
}else{
parent[rootX] = rootY;
size[rootY] += size[rootX];
}
count--;
}
bool connected(int x,int y){
int rootX = find(x);
int rootY = find(y);
return rootX == rootY;
}
int getCount(){
return count;
}
};
最小生成树 – Kruskal 算法
1. Kruskal 算法:从权重最小的边开始贪心选择
2. 使用到了 Union-Find 并查集:对于添加的这条边,如果该边的两个节点本来就在同一连通分量里,那么添加这条边会产生环;反之,如果该边的两个节点不在同一连通分量里,则添加这条边不会产生环。
3. 例题:力扣 1584. 连接所有点的最小费用
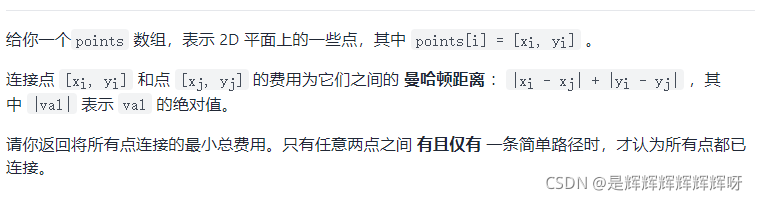

C++ 实现
class edge{
public:
int x;
int y;
int dis;
edge(int x,int y,int dis){
this->x = x;
this->y = y;
this->dis = dis;
}
bool operator<(edge ed){
return this->dis < ed.dis;
}
};
class UnionFind{
public:
int count;
int *parent;
int *size;
UnionFind(int n){
count = n;
parent = new int[n];
size = new int[n];
for(int i=0;i<n;i++){
parent[i] = i;
}
fill(size,size+n,1);
}
int find(int x){
while(x != parent[x]){
parent[x] = parent[parent[x]];
x = parent[x];
}
return x;
}
void Union(int x,int y){
int rootX = find(x);
int rootY = find(y);
if(rootX==rootY){
return ;
}
if(size[rootX]>size[rootY]){
parent[rootY] = rootX;
size[rootX] += size[rootY];
}else{
parent[rootX] = rootY;
size[rootY] += size[rootX];
}
count--;
}
bool connected(int x,int y){
int rootX = find(x);
int rootY = find(y);
return rootX == rootY;
}
int getCount(){
return count;
}
};
class Solution {
public:
int res = 0;
vector<edge> vec;
int minCostConnectPoints(vector<vector<int>>& points) {
int n = points.size();
for(int i=0;i<n;i++){
for(int j=i+1;j<n;j++){
int dis = abs(points[i][0]-points[j][0]) + abs(points[i][1]-points[j][1]);
edge temp(i,j,dis);
vec.push_back(temp);
}
}
sort(vec.begin(),vec.end());
UnionFind uf(n);
for(edge ed : vec){
int u = ed.x;
int v = ed.y;
int dis = ed.dis;
if(uf.connected(u,v)){
continue;
}
uf.Union(u,v);
res += dis;
}
return uf.getCount()==1?res:0;
}
};
4. Kruskal 算法的复杂度:假设一幅图的节点个数为V,边的条数为E,首先需要O(E)的空间装所有边,而且 Union-Find 算法也需要O(V)的空间,所以 Kruskal 算法总的空间复杂度就是O(V + E)。时间复杂度主要耗费在排序,需要O(ElogE)的时间,Union-Find 算法所有操作的复杂度都是O(1),套一个 for 循环也不过是O(E),所以总的时间复杂度为O(ElogE)。
最小生成树 – Prim算法
首先,Prim 算法也使用贪心思想来让生成树的权重尽可能小,也就是「切分定理」。
其次,Prim 算法使用 BFS 算法思想 和 visited 布尔数组避免成环,来保证选出来的边最终形成的一定是一棵树。
Prim 算法不需要事先对所有边排序,而是利用优先级队列动态实现排序的效果,所以我觉得 Prim 算法类似于 Kruskal 的动态过程。
切分定理展示:「切分」这个术语其实很好理解,就是将一幅图分为两个不重叠且非空的节点集合。

Prim 算法的逻辑就是这样,每次切分都能找到最小生成树的一条边,然后又可以进行新一轮切分,直到找到最小生成树的所有边为止。
// C++模板
class Edge {
public:
int s;
int to;
int w;
Edge(int s, int to, int w) {
this->s = s;
this->to = to;
this->w = w;
}
bool operator < (const Edge e) const {
return this->w > e.w;
}
};
class Prim {
private:
int n;
int weightSum;
vector<vector<Edge>> graph;
priority_queue<Edge> pq;
int* inMst;
void cut(int s) {
for (Edge edge : graph[s]) {
int to = edge.to;
if (inMst[to]) {
continue;
}
pq.push(edge);
}
}
public:
Prim(vector<vector<Edge>> graph) {
n = graph.size();
weightSum = 0;
this->graph = graph;
inMst = new int[n];
fill_n(inMst, n, 0);
inMst[0] = 1;
cut(0);
while (!pq.empty()) {
Edge edge = pq.top();
pq.pop();
int to = edge.to;
if (inMst[to]) {
continue;
}
weightSum += edge.w;
inMst[to] = 1;
cut(to);
}
}
int getWeightSum() {
return weightSum;
}
bool isBst() {
for (int i = 0; i < n; i++) {
if (!inMst[i]) {
return false;
}
}
return true;
}
};
Dijkstra 算法模板
Dijkstra 算法(一般音译成迪杰斯特拉算法),是解决最短路径问题的一种方法。
详细内容在另一篇博客 --> 点击直达
名流问题
力扣题目“上锁”了,忘了就直接看 东哥讲解 吧



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











