



 本文介绍如何使用Scrapy模拟浏览器登录来抓取动态HTML内容。以腾讯招聘网页为例,当直接用request获取数据不完整时,通过创建Scrapy项目,编写自定义中间键(使用PhantomJS或Chrome),并在settings.py中配置中间键,最终成功运行爬虫,获取完整的HTML数据。
本文介绍如何使用Scrapy模拟浏览器登录来抓取动态HTML内容。以腾讯招聘网页为例,当直接用request获取数据不完整时,通过创建Scrapy项目,编写自定义中间键(使用PhantomJS或Chrome),并在settings.py中配置中间键,最终成功运行爬虫,获取完整的HTML数据。
有些网页,使用request返回的数据不完整,这时候需要使用模拟浏览器
以腾讯招聘为例,在浏览器里显示
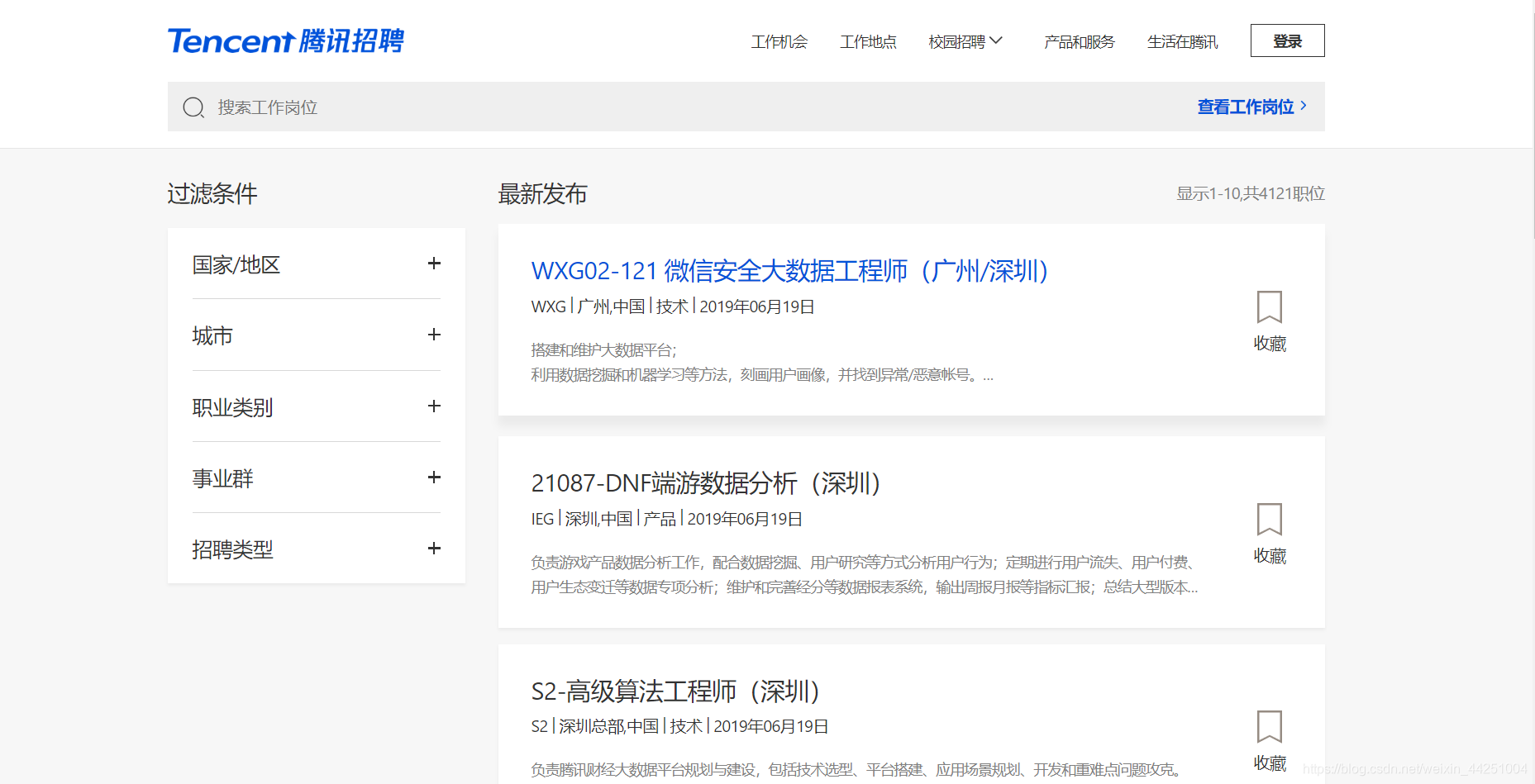
但是如果我们抓取返回的数据的话,他返回的就变动了
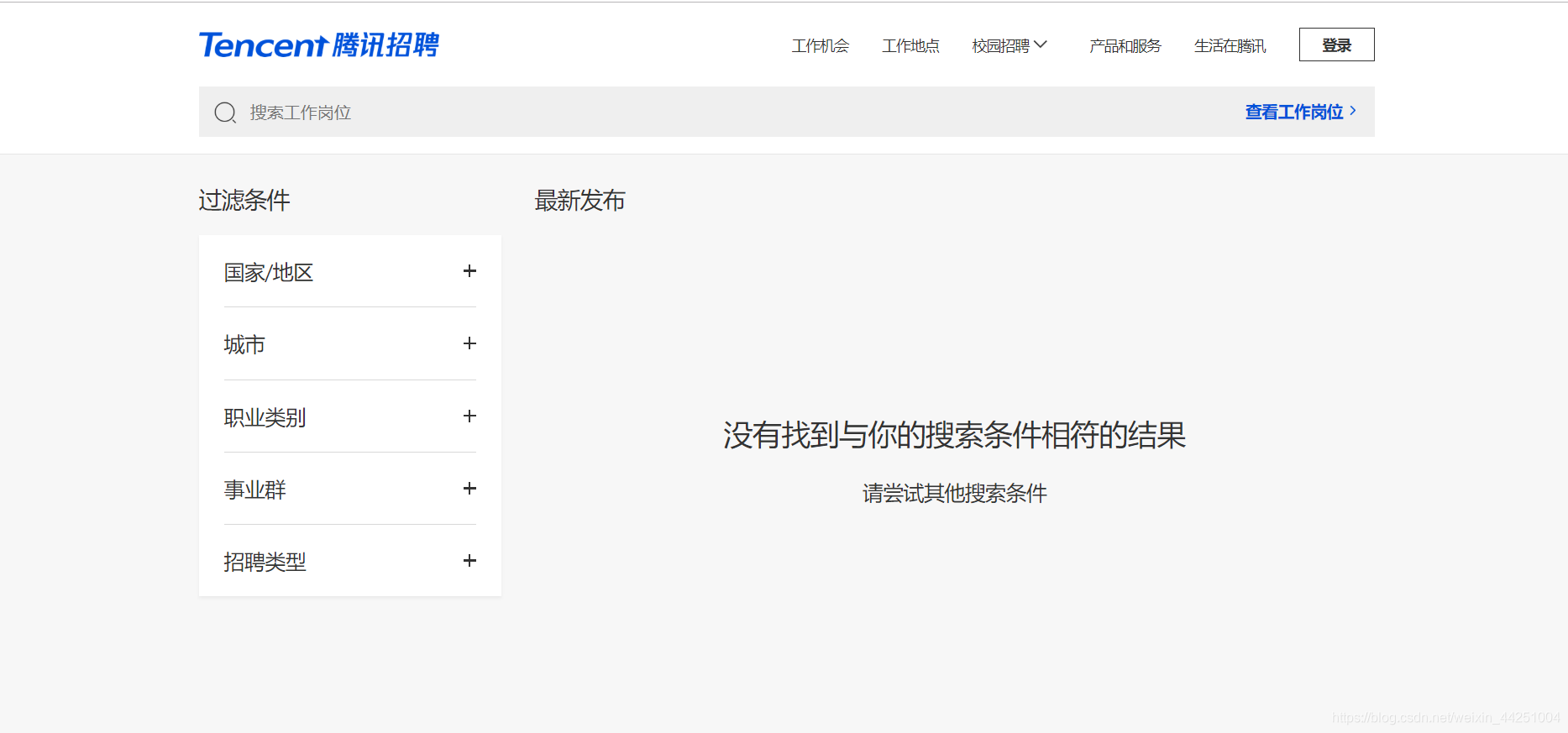
所以我们需要模拟浏览器使用一下
1、先创建scrapy项目
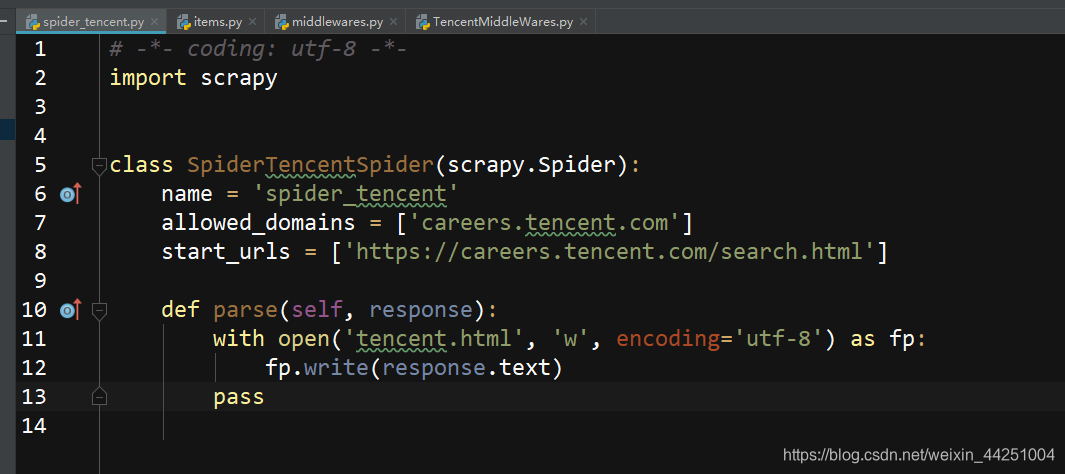
2、创建爬虫文件
,spider_tencent.py,这里是把抓取下来的文件保存为一个html文件
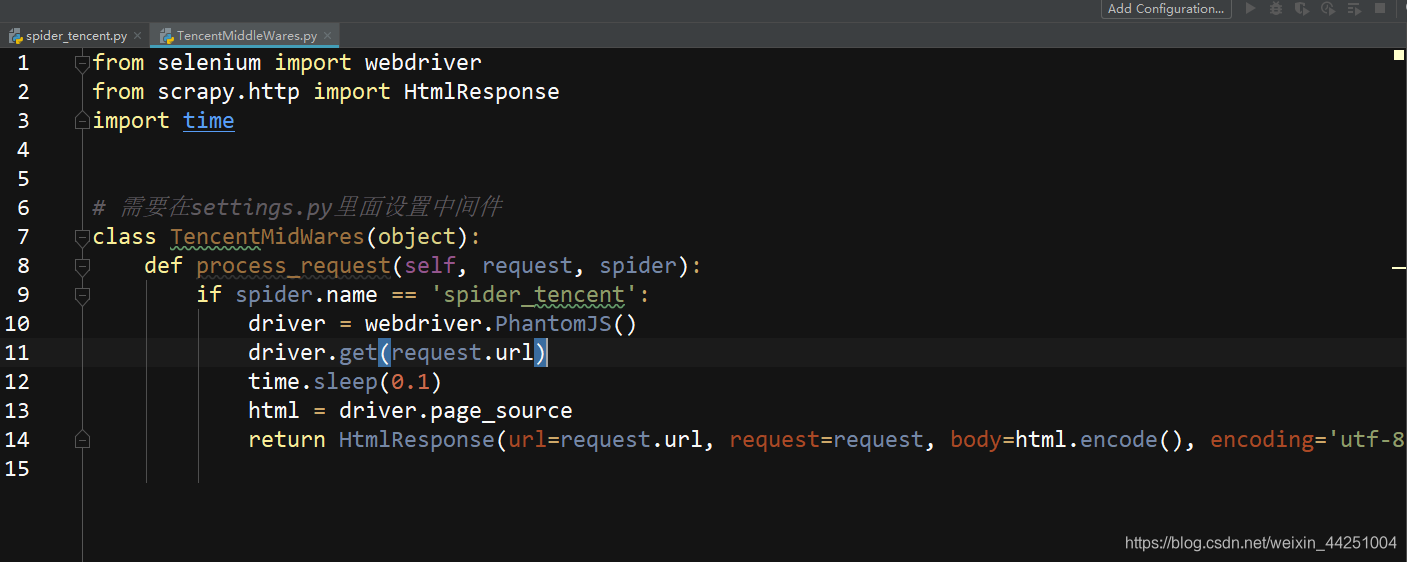
3、编写中间键
TencentMiddleWares.py
其实创建项目的时候,自带了一个中间键的文件,但是在这里,不使用它,而是自己写一个
webdriver.PhantomJS和webdriver.Chrome都需要添加到环境里
4、然后修改settings.py文件
在DOWNLOADER_MIDDLEWARES里面,选择刚刚创建的那个中间键,为了减少操作上失误,这里直接把它的路径给拷了过来

5、最后运行爬虫
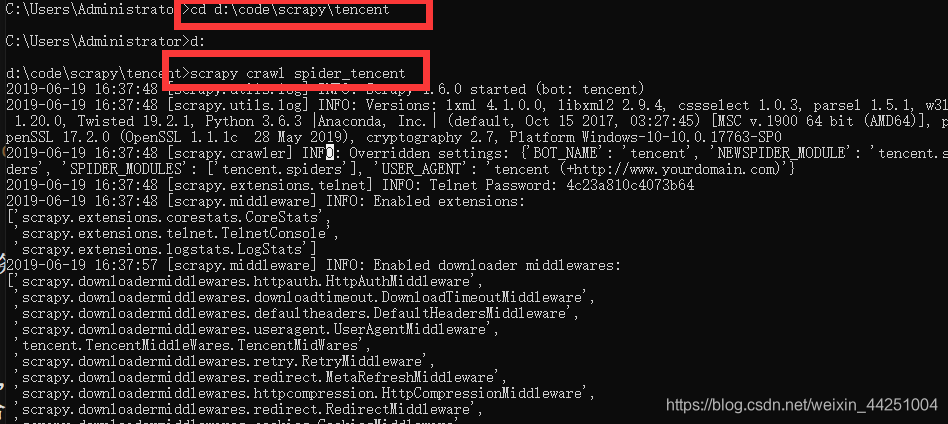
先把目录切换到这个项目下,然后scrapy crawl 爬虫名
最后,查看html文件,已经抓取到了


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









