




 本文探讨了偏差与方差在机器学习中的概念,通过靶心图示例解释两者区别。阐述了欠拟合和过拟合现象,并提供了调整方法:增加特征、调整模型复杂度和正则化。重点介绍了吴恩达的观点,即先降低偏差再减少方差,以提升模型性能。
本文探讨了偏差与方差在机器学习中的概念,通过靶心图示例解释两者区别。阐述了欠拟合和过拟合现象,并提供了调整方法:增加特征、调整模型复杂度和正则化。重点介绍了吴恩达的观点,即先降低偏差再减少方差,以提升模型性能。
首先,区一下偏差与方差。其实偏差与方差都是误差,是衡量模型预测好坏的评判标准,误差 = 方差 + 偏差。
先看一张经典的靶心图:
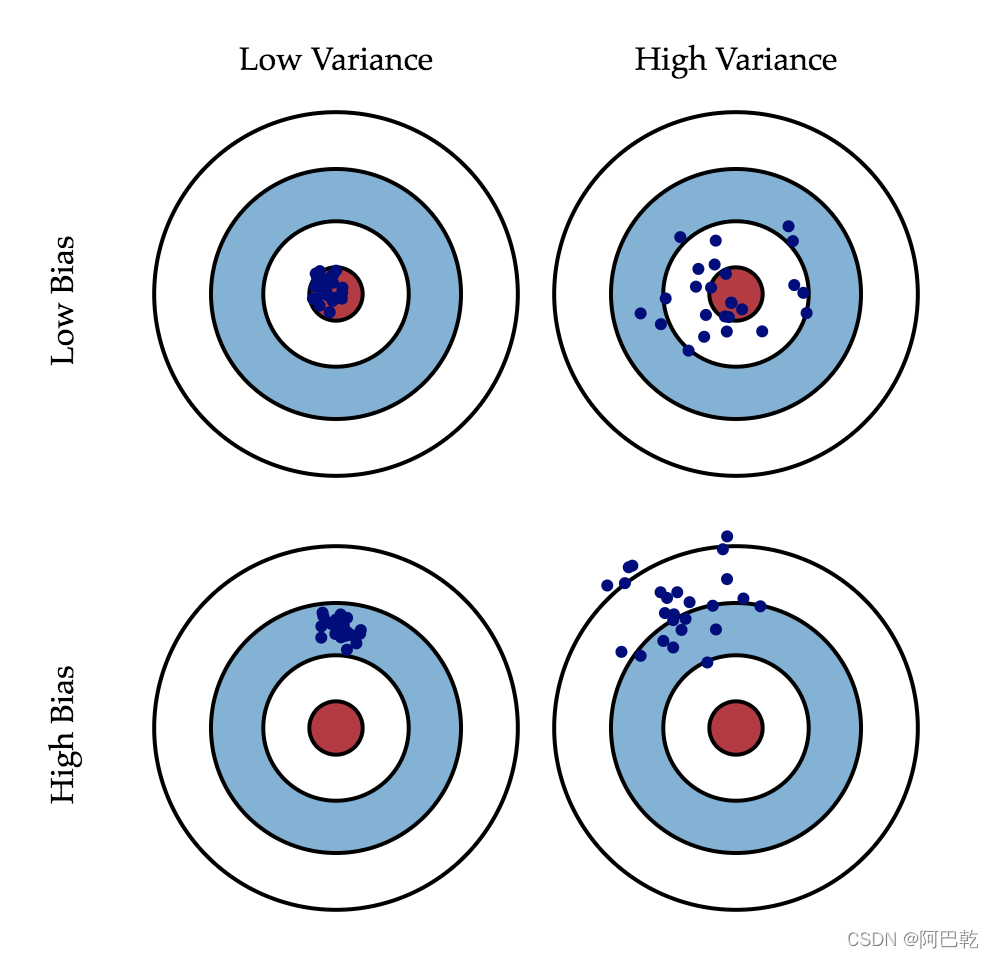
图中红色靶心为数据的实际值或真实值,蓝色点集为估计值或预测值。值得注意的是,所有蓝点的输入样本都是一样的,那么为什么会得出不同的预测值呢?因为这里代表的是:我们使用了不同的训练集(从所有样本中选出不同的训练集)进行训练,得出了不同的模型参数,即不同的训练模型,然后将同一个样本分别输入这些模型之中,得到了蓝色点集预测值。
因此引出偏差与方差的机器学习定义:
偏差:描述的是预测值(估计值)的期望与真实值之间的差距。偏差越大,越偏离真实数据集。
方差:描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,预测结果数据的分布越散。
那么,为什么高偏差是欠拟合,而高方差是过拟合呢?
若一个模型欠拟合,则它在训练集上损失值较大,在测试集上损失值也非常大,那就说明蓝色点集偏离红色靶心,预测值偏离真实数据集,即高偏差。
若一个模型过拟合,则它在训练集上损失值较小,但是在测试集上损失值较大,那就说明模型复杂度过高,不同的训练集样本可以训练出较大差异的模型,产生的预测值差异较大,则会产生高方差。
欠拟合(高偏差)解决办法:
- 增加特征
- 提高模型复杂度
- 减小正则化系数
过拟合(高方差)解决办法:
- 增加训练数据
- 降低模型复杂度
- 增加正则化参数
- 采用集成学习
对于完成一个机器学习系统,吴恩达有介绍,需要先确保一个系统是低偏差的,可以通过提高模型复杂度来降低偏差,比如增加神经系统的隐藏层。然后增大数据集,可以利用人工合成数据来扩充数据集,以此来降低方差,提高模型的性能。



















 382
382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











