




目录
一、基本介绍
本文主要介绍利用现有开源的图像文字识别(OCR)库,开发一个简单的程序,用于识别图像中的文字信息。当前,开源的OCR库有很多,比如国外的Tesseract、EasyOCR,国内百度、阿里、腾讯等均提供了相应的开源工具包。百度的PaddleOCR在中文识别上准确率很高,百度开发的paddleocr库也为人工智能开发提供了各类算法模型,在人工智能开发领域运用比较广泛。本文基于PaddleOCR,在python中利用百度已经训练好的OCR模型库,完成对图像中文字识别,并将开发程序打包,使其可移植到其他电脑终端使用。
二、程序实现
1)环境配置
(1)新建工程
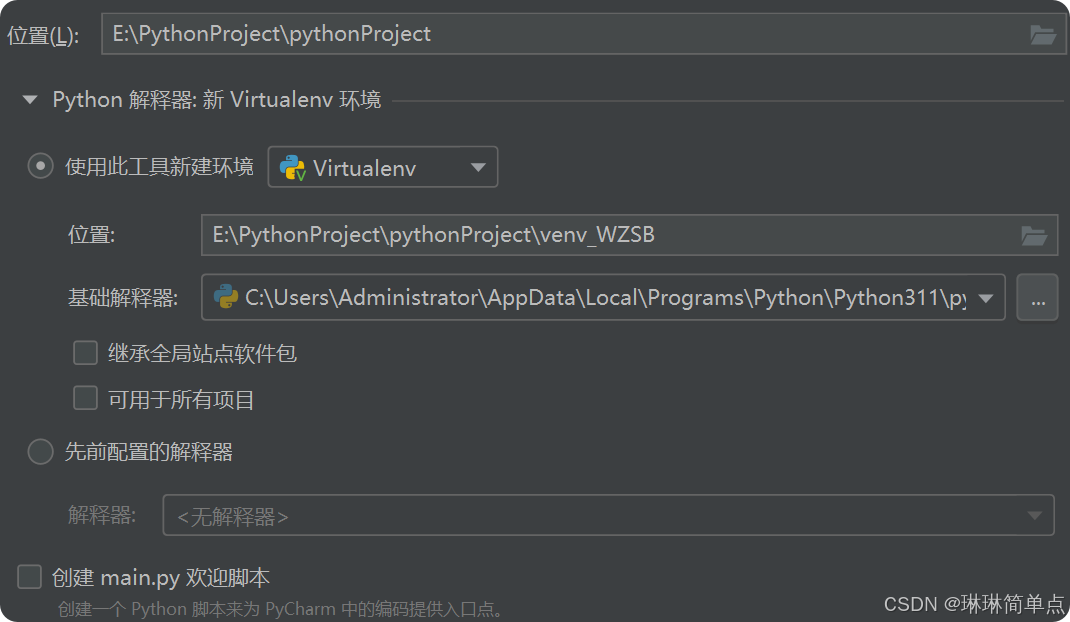
python程序开发使用的IDE工具是pyChram2023.1.21版,直接新建一个纯python项目,并新构建一个虚拟环境,基本设置如下,工程路径可自定义。
(2)安装依赖包
使用PaddleOCR需要安装两个依赖包,分别是paddlepaddle和paddleocr。这两个依赖包均安装在上一步建立的虚拟环境下(venv_WZSB)。需要注意的是,paddleocr目前只支持到python3.8到python3.11版本,若使用的python版本不在此区间,需要安装一个在此区间的版本,并将当前python解释器设置为此可用的版本,否则paddleocr将安装失败。
![]()
![]()
2)代码实现
使用python编写一个简易的窗口程序,用于加载显示需要识别的图片,并将识别的结果显示在窗口中。
(1)设置模型存放路径
首先在代码中设置paddleocr训练模型的存放路径,代码如下。由于我们使用百度工程师已经训练好的模型,所以我们不用再编写具体的文字识别模型,直接使用即可。下面的代码分别表明了检测、识别
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











