



 本文详细介绍了SaltStack中的Grains和Pillar系统。Grains负责收集Minion的静态信息,如操作系统、CPU等,用于条件匹配和资产管理。Pillar则是用于给特定Minion提供安全的动态数据,适用于存储敏感信息和处理变量差异。文章通过实例展示了如何自定义Grains模块、使用Pillar定义和应用数据,以及两者在存储位置、数据类型、更新方式和应用上的区别。
本文详细介绍了SaltStack中的Grains和Pillar系统。Grains负责收集Minion的静态信息,如操作系统、CPU等,用于条件匹配和资产管理。Pillar则是用于给特定Minion提供安全的动态数据,适用于存储敏感信息和处理变量差异。文章通过实例展示了如何自定义Grains模块、使用Pillar定义和应用数据,以及两者在存储位置、数据类型、更新方式和应用上的区别。
一.grains简介
-
grains是Saltstack最重要的组件之一,grains的作用是收集被控主机的基本信息,这些信息通常都是一些静态的数据,包括CPU、内核、操作系统、虚拟化等,在服务器端可以根据这些信息进行灵活定制,管理员可以利用这新信息对不同业务进行个性化配置。
-
Grains是SaltStack当中的一个数据系统,当Minion启动时Grains会把Minion的数据收集起来,比如操作系统版本、CPU 位数等。由于采用的是静态收集,只有当Minion发生重启时数据才会发生变化,在Grains的实际运用中常用于对多台Minion做操作时进行一些条件匹配,比如有上百台Minion服务器,只需要对操作系统为CentOS的做一些操作等
二.grains模块的应用
1.罗列出所有Minion的所有信息,命令执行后可以看到出现了很多信息,我们可以用这些信息来作为一些过滤条件
[root@server1 salt]# salt '*' grains.items

通过grains来做信息过滤,使用-G选项:
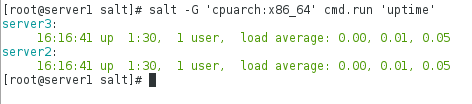
[root@server1 salt]# salt -G 'cpuarch:x86_64' cmd.run 'uptime' 在所有64位CPU服务器上执行uptime
执行后反馈效果图:
2.当grains.items里的模块不满足当前情况,还可以自定义Grains,比如在server2(minion)添加一个apache模块
[root@server2 ~]# cd /etc/salt/
[root@server2 salt]# vim minion
120 grains:
121 roles:
122 - apache 是以键值对的形式存在的,可以获取该模块对应的变量的值
[root@server2 salt]# systemctl restart salt-minion
//server3:
[root@server3 ~]# cd /etc/salt/
[root@server3 salt]# vim minion
120 grains:
121 roles:
122 - apache 是以键值对的形式存在的,可以获取该模块对应的变量的值
[root@server2 salt]# systemctl restart salt-minion
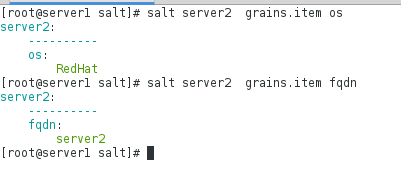
在server1上进行相应的测试,可以看到了server2上已经有该模块的变量了server3上也有:



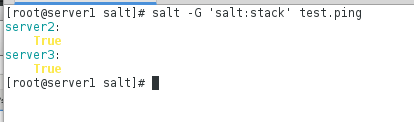
注:这个时候在Master端执行salt -G ‘roles:apache’ test.ping会发现刚才编辑过Minion配置文件的服务器也能被匹配出来,而其他没有做相应操作的服务器则不会显示,生产环境中我们可以对装有http的服务器批量进行重启等
salt -G 'roles:apache' cmd.run 'systemctl restart httpd'
3.如果不想在minion上的/etc/salt/minion添加模块,那么也可以在master上创建/etc/salt/_grains目录并且编辑文件添加模块
[root@server1 salt]# mkdir /etc/salt/_grains
[root@server1 salt]# cd /etc/salt/_grains/
[root@server1 _grains]# ls
[root@server1 _grains]# vim my_grains.py
#!/usr/bin/env python
def my_grains():
grains = {'foo': 'bar', 'hello': 'world'} 模块定义的两种方式
grains['salt'] = 'stack'
return grains
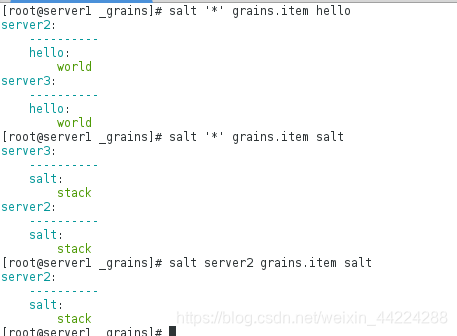
[root@server1 _grains]# salt '*' saltutil.sync_grains
因为grains是静态收集信息,这个时候不重启minion的话Grains是不会生效的,所以这个时候使用-G是看不到信息的,可以在Master执行一个模块刷新
master上模块刷新效果如下:

测试可以查看到添加的信息了:
检查添加了模块的服务器是否添加进来:
4.测试:在/srv/salt里面有top.sls文件在里面可以使用grains匹配的模块对已经添加的minion服务器进行相应的服务推送
[root@server1 salt]# ls
apache _grains nginx top.sls
[root@server1 salt]# pwd
/srv/salt
[root@server1 salt]# vim top.sls
base:
'roles:apache': 在server2的minon的配置文件种添加的自定义的模块
- match: grain 匹配grain
- apache.service
'roles:nginx': 在server3的minon的配置文件种添加的自定义的模块
- match: grain
- nginx.service
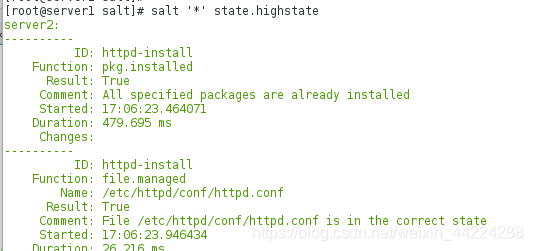
可以看到使用自定义的grains模块推送成功
三.Pillar简介
-
Pillar是Salt非常重要的一个组件,它用于给特定的minion定义任何你需要的数据,这些数据可以被Salt的其他组件使用。
-
给minion指定它想要的数据,给哪个minion指定,哪个minion能看到,,其他minion看不到,安全性得到了保障,在master端设置的
pillar应用场景:
1、敏感数据
比如给某一个配置文件设置个密码,这个密码只希望某个minion能看到
2、使用pillar处理变量的差异性
3、做配置管理时用pillar定义一些变量参数
4、定位主机
四.pillar的应用
1.在master的配置文件中打开pillar模块
[root@server1 salt]# vim /etc/salt/master
843 pillar_roots:
844 base:
845 - /srv/pillar 打开定义的pillar的路径
[root@server1 salt]# systemctl restart salt-master
[root@server1 salt]# mkdir /srv/pillar
[root@server1 salt]# systemctl restart salt-master
2.定义pillar的路径下做简单的测试
[root@server1 salt]# cd /srv/pillar
[root@server1 pillar]# vim vars.sls
{% if grains['fqdn'] == 'server2' %}
webserver: httpd
state: master
{% elif grains['fqdn'] == 'server3' %}
webserver: nginx
state: backup
{% endif %}
[root@server1 pillar]# vim top.sls
base:
'*':
- vars
base里面的路径的另一种方式:
[root@server1 pillar]# pwd
/srv/pillar
[root@server1 pillar]# mkdir web
[root@server1 pillar]# mv vars.sls web/
[root@server1 pillar]# ls
top.sls web
base:
'*':
- web.vars
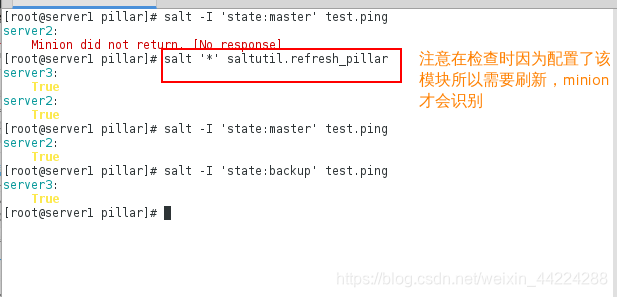
查看如下:

检查定义的上述模块的minion服务器能否ping通:
五.grains和Pillar的区别
1.存储位置
- grains:minion端
- pillar:master端
2.数据类型
- grains:静态数据
- pillar:动态数据
3.数据采集更新方式
-
grains:minion启动时收集,也可以使用saltutil.sync_grains进行刷新
-
pillar:在master端定义,指定给对应minion,
可以使用saltutil.sync_pillar刷新。
4.应用
- grains:存储minion基本数据。比如用于匹配minion,自身数据可以用来做资产管理等。
- pillar:存储master指定的数据,只有指定的minion可以看到,用于敏感。

















 690
690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









