




 本文深入探讨Python中的多线程编程,包括线程与进程的基本概念、thread与threading模块的使用、线程锁机制、多线程实例及队列模块的应用。通过具体示例,解析多线程在Python中的实现细节与注意事项。
本文深入探讨Python中的多线程编程,包括线程与进程的基本概念、thread与threading模块的使用、线程锁机制、多线程实例及队列模块的应用。通过具体示例,解析多线程在Python中的实现细节与注意事项。
这里我只是简单的记录下我的学习记录而已,没有多专业,但是我保证执行都是正确的
背景:python 3.7 IDE:pycharm
1、介绍
首先进程是整个计算机的,官方的可以直接搜,我理解我是计算机的核,比如单核的是一个线程运算,多核可以运行多个进程,操作系统会以进程为单位,分配系统资源(CPU时间片、内存等资源),进程是资源分配的最小单位
线程比进程低一级,就是进程下的分布而已,有时被称为轻量级进程(Lightweight ,是操作系统调度(CPU调度)执行的最小单位
python的执行是由python虚拟机来控制的,虚拟机有一个全局解释器锁(GIL),用于控制整个系统只有一个进程在运行。
这里我们所谓的多进程就是在一个进程运行中的空隙时间分出来给另一个,但是原则上还是只有一个进程在使用,python中有两个模块,一个thread一个threading,前者会在没有清理的情况下退出所有线程,所以推荐用后者(不推荐使用thread模块了)
2.使用线程
我们首先通过一个例子来明白一下执行的过程:
from time import sleep, ctime
def test0():
print('start test 0 at:', ctime())
sleep(4)
print('test 0 done at:', ctime())
def test1():
print('start test 1 at:', ctime())
sleep(2)
print('test 1 done at:', ctime())
def main():
print('starting at:', ctime())
test0()
test1()
print('all DONE at:', ctime())
if __name__ == '__main__':
main()
结果如下:
('starting at:', 'Mon Jun 3 22:22:32 2019')
('start loop 0 at:', 'Mon Jun 3 22:22:32 2019')
('loop 0 done at:', 'Mon Jun 3 22:22:36 2019')
('start loop 1 at:', 'Mon Jun 3 22:22:36 2019')
('loop 1 done at:', 'Mon Jun 3 22:22:38 2019')
('all DONE at:', 'Mon Jun 3 22:22:38 2019')
Process finished with exit code 0
我们的test1程序执行的是停4秒,test2停2秒,理论上的时间就是最短6秒,必须按照顺序一个个线程执行,实际的话甚至很多时候会大于6秒
这里sleep模拟的就是函数运算过程,换成一些复杂的运算,再标记时间就可以看出运行的时间差距
3、thread模块
虽然不推荐用,但是了解一下也是可以的,据说专家级别这个就更好用哦
核心函数: start_new_thread(),顾名思义,派生一个新的线程,模块必须包含两个参数,一个是函数,一个是它的参数,如果不需要就给个空元组,我们改进刚才的函数,做一些调整来对比:
from time import sleep, ctime
import thread
def test0():
print(‘start test 0 at:’, ctime())
sleep(4)
print(‘test 0 done at:’, ctime())
def test1():
print(‘start test 1 at:’, ctime())
sleep(2)
print(‘test 1 done at:’, ctime())
def main():
print(‘starting at:’, ctime())
thread.start_new_thread(test0, ())
thread.start_new_thread(test1, ())
sleep(6)
print(‘all DONE at:’, ctime())
if name == ‘main’:
main()
结果如下:
('starting at:', 'Mon Jun 3 22:50:46 2019')
('start test 0 at:', 'Mon Jun 3 22:50:46 2019'()'start test 1 at:'
, 'Mon Jun 3 22:50:46 2019')
('test 1 done at:', 'Mon Jun 3 22:50:48 2019')
('test 0 done at:', 'Mon Jun 3 22:50:50 2019') #在这里就已经执行完了的
('all DONE at:', 'Mon Jun 3 22:50:52 2019')
Process finished with exit code 0
我们看到其实只用了四秒,然后我们的test1居然还更快完成了,这里有个重要的东西就是主函数的sleep(6),如果没有这个,函数会直接在执行完两个线程后退出,因为没有写执行完后的代码,所以只能这样观察了,当然这只是暂时的,肯定能改善啊,接下来做进一步改变:
from time import sleep, ctime
import thread
tests = [4, 2]
def test(data, seconds, lock):
print('start tests', data, 'at:', ctime())
sleep(seconds)
print('tests', data, 'done at:', ctime())
lock.release()
def main():
print('starting at:', ctime())
locks = []
datas = range(len(tests))
for i in datas:
lock = thread.allocate_lock()
lock.acquire()
locks.append(lock)
for i in datas:
thread.start_new_thread(test, (i, tests[i], locks[i]))
for i in datas:
while locks[i].locked():
pass
print('all DONE at:', ctime())
if __name__ == '__main__':
main()
结果如下:
('starting at:', 'Mon Jun 3 23:05:48 2019')
('start tests', (0'start tests', , 'at:'1, , 'Mon Jun 3 23:05:48'at:' 2019', )'Mon Ju
n 3 23:05:48 2019')
('tests', 1, 'done at:', 'Mon Jun 3 23:05:50 2019')
('tests', 0, 'done at:', 'Mon Jun 3 23:05:52 2019')
('all DONE at:', 'Mon Jun 3 23:05:52 2019')
Process finished with exit code 0
例子中麻烦了一点,把参数都放在了列表里面,其实就是test1、test2和2秒,4秒的,模拟下多数据情况,分别是三个for循环,第一个是用allocate_lock函数去获取锁对象,然后用acquire获取,取得锁的过程就是把锁锁上的意思,就被放入列表中了;第二个for循环就是调用线程,分别创建函数,传递需要的参数,比如test1创建了,然后得到了锁,开始执行,然后执行完就被释放了,开始下一个,第三个就是等待所有锁都执行完了就over了,没有锁了,就完成了
这是原理,说下缺点,就是最后的必须一直等,他们不开锁我就没法开始,如果前面的卡死了,就直接等不到了,所以我们有了threading更高级的模块
4、threading模块
下面给出threading模块的常用对象:

这其中最重要的就是Thread类了,是主要的执行对象,它有很多thread模块没有的函数,下面给出其属性和方法:
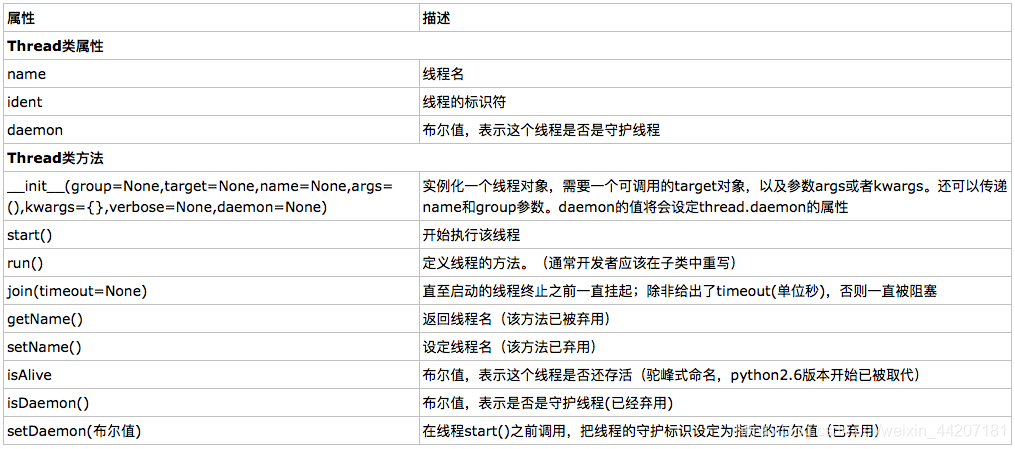
我们来写一个基础的实例:
import threading
from time import ctime, sleep
loops = [4, 2]
def loop(nloop, nesc):
print('start loop', nloop, 'at:', ctime())
sleep(nesc)
print('loop', nloop, 'done at:', ctime())
def main():
print('starting at:', ctime())
threads = []
nloops = range(len(loops))
for i in nloops:
t = threading.Thread(target=loop, args=(i, loops[i]))
threads.append(t)
for i in nloops:
threads[i].start()
for i in nloops:
threads[i].join()
print('all DONE at:', ctime())
结果如下:
('starting at:', 'Tue Jun 4 20:22:42 2019')
('start loop', 0, 'at:', 'Tue Jun 4 20:22:42 2019')
('start loop', 1, 'at:', 'Tue Jun 4 20:22:42 2019')
('loop', 1, 'done at:', 'Tue Jun 4 20:22:45 2019')
('loop', 0, 'done at:', 'Tue Jun 4 20:22:46 2019')
('all DONE at:', 'Tue Jun 4 20:22:46 2019')
Process finished with exit code 0
这里我们看到,也是四秒执行完,下面介绍下区别,首先函数都是一样的,差别在于调用方式,我们用的是Thread类,它和thread.start_new_thread()的区别在于新线程不会立刻执行,只是分配, 然后分别调用他们的start启动函数,这样他们就一起启动了,剩下的是加入一个join函数,它的作用是等待线程结束或者设置的timeout时间到了结束。整个过程为分配>获取>释放>检查锁状态
补充下join方法介绍,它不需要调用的,一旦线程启动它就一直在执行了,直到给定的函数完成退出,在你需要线程完成的时候就要调用它,挂起就不用调用了
通过前面我们直到thread要传入一个函数和参数才生效,这里我们为了更贴切的模拟面对象编辑,用一个类来演示多线程:
import threading
from time import ctime, sleep
loops = [4, 2]
class ThreadFunc(object):
def __init__(self, func, args, name=''):
self.name = name
self.func = func
self.args = args
def __call__(self):
self.func(*self.args)
def loop(nloop, nsec):
print('start loop', nloop, 'at:', ctime())
sleep(nsec)
print('loop', nloop, 'done at:', ctime())
def main():
print('starting at:', ctime())
threads = []
nloops = range(len(loops))
for i in nloops:
t = threading.Thread(target=ThreadFunc(loop, (i, loops[i]), loop.__name__))
threads.append(t)
for i in nloops:
threads[i].start()
for i in nloops:
threads[i].join()
print('all DONE at:', ctime())
if __name__ == '__main__':
main()
结果更前面是一样的,区别在于用了一个类,而不是只有一个函数了,这个类现在又三个参数,一个函数,一个函数的参数,一个名字,在调用是,类直接调用类的方法完成函数构造,就不用再再后面传递进去参数了,所以可以直接调用了
下面介绍Thread的派生子类,创建子类实例来运行
import threading
from time import sleep, ctime
loops = [4, 2]
class MyThread(threading.Thread):
def __init__(self, func, args, name=''):
threading.Thread.__init__(self)
self.func = func
self.args = args
self.name = name
def run(self):
self.func(*self.args)
def loop(nloop, nsec):
print('start loop', nloop, 'at:', ctime())
sleep(nsec)
print('loop', nloop, 'done at:', ctime())
def main():
print('starting at', ctime())
threads = []
nloops = range(len(loops))
for i in nloops:
t = MyThread(loop, (i, loops[i]), loop.__name__)
threads.append(t)
for i in nloops:
threads[i].start()
for i in nloops:
threads[i].join()
print('all DONE at:', ctime())
if __name__ == '__main__':
main()
这片代码和前面一个没多大改变,主要是构造了一个MyThread的类,这个类继承基类,之前的__call__函数就必须改为run了
我们现在对MyThread类进行修改,增加一些调试信息输出,储存为myThread模块:
import threading
from time import ctime, sleep
class MyThread(threading.Thread):
def __init__(self, func, args, name=''):
threading.Thread.__init__(self)
self.func = func
self.args = args
self.name = name
def getResult(self):
return self.res
def run(self):
print('staring', self.name, 'at:', ctime())
self.res = self.func(*self.args)
print(self.name, 'finished at:', ctime())
这里盗了个图来解释一下多进程,有点复杂:
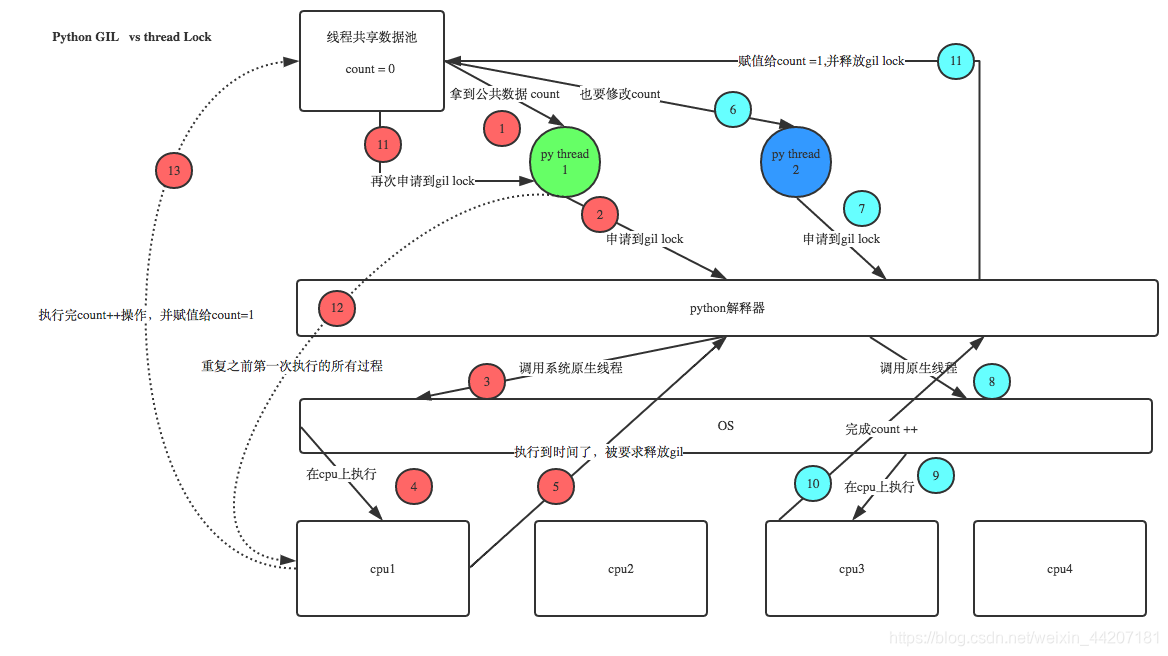
线程锁是用户级别的锁机制,跟解释器的GIL没有任何关系,也不会互相有任何。接下来,大家要注意GIL的描述,它说的是“同一时刻只会有一个线程在cpu上执行”,这并不代表着这个占用cpu的线程之行完后再去执行另一个线程(如果是这样的话,那就不存在多线程的说法了),那么线程很可能会在执行任务中,被打断,让出cpu(python的线程机制是调用的c的线程接口,即原生线程的调用,因此,调度方案是由操作系统决定的)。
即然是这样的,回到用python创建的线程中。上图中,红色的线程的任务是做“加1”操作,由于这个“加一”的操作并不是“原子操作”,所以,在执行时,很可能被打断。如果这时打断红色的线程是蓝色的线程,它同样是利用count(共享资源),那么由于红色的进程没有完成其任务,所以,蓝色的进程读到的count的跟红色的进程读到的值一样(即count=0)。这时,蓝色的线程正常执行,完成“加1”任务(count=1),之后,红色的进程再重新恢复执行,但当下,其拿到的“count=0”,然后完成“加1”任务,即这时“count=1”。
回过头了,我们起初想要的结果是“count=2”,而不是“count=1”。在这个过程中,我们是遵守GIL规则的,但是还是很可能会出现上述现象,这就是我说的,线程锁是用户级别的锁,跟GIL没有关系,我要考虑的业务逻辑是否需要做“原子操作”的问题,如果需要,就需要线程锁机制。
5、单线程和多线程执行对比:
这里我们用到了斐波那契、阶乘和累加函数来对比:
from myThread import MyThread
from time import ctime, sleep
def fib(x):
sleep(0.005)
if x < 2:
return 1
return fib(x-2) + fib(x-1)
def fac(x):
sleep(0.1)
if x < 2:
return 1
return x * fac(x-1)
def sum(x):
sleep(0.1)
if x < 2:
return 1
return x + sum(x - 1)
funcs = [fib, fac, sum]
n = 12
def main():
nfuncs = range(len(funcs))
print('***SINAGLE THREAD')
for i in nfuncs:
print('starting', funcs[i].__name__, 'at:', ctime())
print(funcs[i](n))
print(funcs[i].__name__, 'finished at:', ctime())
print('\n***MULTIPLE THREADS')
threads = []
for i in nfuncs:
t = MyThread(funcs[i], (n,), funcs[i].__name__)
threads.append(t)
for i in nfuncs:
threads[i].start()
for i in nfuncs:
threads[i].join()
print(threads[i].getResult())
print('all Done')
if __name__ == '__main__':
main()
结果如下(每次都不一样,跟电脑有关,但是都能体现出差别):
***SINAGLE THREAD
('starting', 'fib', 'at:', 'Tue Jun 4 22:56:00 2019')
233
('fib', 'finished at:', 'Tue Jun 4 22:56:07 2019')
('starting', 'fac', 'at:', 'Tue Jun 4 22:56:07 2019')
479001600
('fac', 'finished at:', 'Tue Jun 4 22:56:08 2019')
('starting', 'sum', 'at:', 'Tue Jun 4 22:56:08 2019')
78
('sum', 'finished at:', 'Tue Jun 4 22:56:10 2019')
***MULTIPLE THREADS
('staritng', 'fib', 'at:', 'Tue Jun 4 22:56:10 2019')
('staritng', 'fac', 'at:', 'Tue Jun 4 22:56:10 2019')
('staritng', 'sum', 'at:', 'Tue Jun 4 22:56:10 2019')
('sum', 'finished at:', 'Tue Jun 4 22:56:11 2019')
('fac', 'finished at:', 'Tue Jun 4 22:56:11 2019')
('fib', 'finished at:', 'Tue Jun 4 22:56:17 2019')
233
479001600
78
all Done
这里的sleep函数就是为了减慢函数执行而已,不然不好对比结果
6、多线程实例
到了最好的实例环节,通过实例可以更好理解多线程。这里是一个获取Amazon图书排名的函数:
from atexit import register
from re import compile
from threading import Thread
from time import ctime
import urllib2
REGEX = compile('#([\d,]+) in Books')
AMZN = 'https://www.amazon.com/dp/'
isbns = {
'0132269937': 'Core Python Programming',
'0132356139': 'Python Web Development with Django',
'0137143419': 'Python Fundamentals LiveLessons'
}
def getRanking(isbn):
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
req = urllib2.Request('%s%s' % (AMZN, isbn), headers=headers)
page = urllib2.urlopen(req)
data = page.read()
page.close()
return REGEX.findall(data)[0]
def _showRanking(isbn):
print('- %r ranked %s' % (isbns[isbn], getRanking(isbn)))
def _main():
print('At', ctime(), 'on Amazon...')
for isbn in isbns:
_showRanking(isbn)
@register
def _atexit():
print('all DONE at:', ctime())
if __name__ == '__main__':
_main()
这段代码基本没多大难度,也就是urllib2那段需要注意下,很多时候都是要先构造请求的,不然很有可能就是503界面,然后提取内容用正则表达式去匹配出结果,得到排名,后面就是打印了
这儿还有一个atexit.register()函数,这里用了装饰器的方式,这个函数会在解释器中注册一个退出函数,在函数退出的时候调用,执行结果如下:
('At', 'Wed Jun 5 10:49:53 2019', 'on Amazon...')
- 'Core Python Programming' ranked 134,638
- 'Python Fundamentals LiveLessons' ranked 5,341,165
- 'Python Web Development with Django' ranked 1,427,588
('all DONE at:', 'Wed Jun 5 10:50:14 2019')
Process finished with exit code 0 #试了很多次,差不多就是是21秒左右的水平
接下来我们用多线程来写这个函数,不要改变太多:
重写main函数中的_showRanking(isbn)函数
def _main():
print('At', ctime(), 'on Amazon...')
for isbn in isbns:
#_showRanking(isbn)
Thread(target=_showRanking, args=(isbn, )).start()
结果是(其实提升一般,但是电脑决定了总体比较慢,但是有提升):
('At', 'Wed Jun 5 14:30:48 2019', 'on Amazon...')
- 'Python Web Development with Django' ranked 1,435,481
- 'Core Python Programming' ranked 208,229
- 'Python Fundamentals LiveLessons' ranked 5,342,613
('all DONE at:', 'Wed Jun 5 14:31:03 2019')
Process finished with exit code 0
7、锁示例
锁有两个状态:锁定和未锁定,支持两个函数获得锁和释放锁
线程争夺时,当得到第一个锁的线程就会进入执行区,其他的线程会被阻塞,知道这个锁释放,让我们看个例子看看锁的作用:
from atexit import register
from random import randrange
from threading import Thread, currentThread
from time import ctime, sleep
class CleanOutputSet(set):
def __str__(self):
return ', '.join(x for x in self)
loops = (randrange(2, 5) for x in range(randrange(3, 7)))
remaining = CleanOutputSet()
def loop(nesc):
myname = currentThread().name
remaining.add(myname)
print('[%s] Started %s' % (ctime(), myname))
sleep(nesc)
remaining.remove(myname)
print ('[%s] Completed %s (%d secs)' % (ctime(), myname, nesc))
print (' (remaining: %s' % (remaining or 'NONE'))
def main():
for pause in loops:
Thread(target=loop, args=(pause,)).start()
@register
def _atexit():
print('all DONE at:', ctime())
if __name__ == '__main__':
main()
结果如下:
[Wed Jun 5 15:57:13 2019] Started Thread-1
[Wed Jun 5 15:57:13 2019] Started Thread-2
[Wed Jun 5 15:57:13 2019] Started Thread-3
[Wed Jun 5 15:57:13 2019] Started Thread-4
[Wed Jun 5 15:57:16 2019] Completed Thread-2 (3 secs)
(remaining: Thread-4, Thread-3, Thread-1
[Wed Jun 5 15:57:17 2019] Completed Thread-1 (4 secs)
(remaining: Thread-4, Thread-3
[Wed Jun 5 15:57:17 2019] Completed Thread-4 (4 secs)
(remaining: Thread-3
[Wed Jun 5 15:57:17 2019] Completed Thread-3 (4 secs)
(remaining: NONE
('all DONE at:', 'Wed Jun 5 15:57:17 2019')
Process finished with exit code 0
我们得到的输出是,先建立四个进程,这四个进程被分配随机的2到4的睡眠时间,在loop里面有一个列表,加入线程名称,用到了类的__str__方法,这个方法在调用时可以打印其中的内容,这样我们就把剩下的进程打印出来,观察情况,可以看到执行的时候并不是1234的执行,而是混乱的,时间是最长的那一个进程的时间。
还有一些特别的情况,就是结果中出现线程同时进行的情况,这是不稳定的,就是显示的列表中会同时少去两个进程名字,这是因为进程同时进入了临界区,同时执行了,这是不可控的,为了控制它,我们引入了Lock和RLcok锁对象:
from atexit import register
from random import randrange
from threading import Thread, currentThread, Lock
from time import ctime, sleep
lock = Lock()
class CleanOutputSet(set):
def __str__(self):
return ', '.join(x for x in self)
loops = (randrange(2, 5) for x in range(randrange(3, 7)))
remaining = CleanOutputSet()
def loop(nesc):
myname = currentThread().name
lock.acquire()
remaining.add(myname)
print('[%s] Started %s' % (ctime(), myname))
lock.release()
sleep(nesc)
lock.acquire()
remaining.remove(myname)
print ('[%s] Completed %s (%d secs)' % (ctime(), myname, nesc))
print ('(remaining: %s' % (remaining or 'NONE'))
lock.release()
def main():
for pause in loops:
Thread(target=loop, args=(pause,)).start()
@register
def _atexit():
print('all DONE at:', ctime())
if __name__ == '__main__':
main()
增加了一个Lock对象,实例化为lock,首先程序执行时,我们先获得四个进程配置,从打印结果可以看出,四个程序打印是同时的,因为他们的执行几乎不需要时间,就算是得到锁释放锁也是基本等于一起了,在sleep的时候没有锁存在,同时执行,所以执行时间最后是最长的那一个,但是打印结果就是分开的,一次只能打印一个
使用with语句可以进一步精简结构:
def loop(nesc):
myname = current_thread().name
with lock:
remaining.add(myname)
print('[%s] Started %s' % (ctime(), myname))
sleep(nesc)
with lock:
remaining.remove(myname)
print ('[%s] Completed %s (%d secs)' % (ctime(), myname, nesc))
print ('(remaining: %s' % (remaining or 'NONE'))
8、信息量
信息量是一个计数器,显示的是资源消耗,消耗越多它越少,当一个线程启动时它减少,当资源返还时增多。下面通过一个自动售卖机来演示,有5个位置,满了就不能加产品了,卖完了就不能买了,信息量就是用来跟踪的,先看代码:
from atexit import register
from random import randrange
from threading import BoundedSemaphore, Lock, Thread
from time import ctime, sleep
lock = Lock()
max = 5
candytray = BoundedSemaphore(max)
def refill():
lock.acquire()
print ('Refilling candy...')
try:
candytray.release()
except ValueError:
print('full, skipping')
else:
print('Ok')
lock.release()
def buy():
lock.acquire()
print('Buying candy...')
if candytray.acquire(False):
print('Ok')
else:
print('empty, skipping')
lock.release()
def producer(loops):
for i in range(loops):
refill()
sleep(randrange(3))
def consumer(loops):
for i in range(loops):
buy()
sleep(randrange(3))
def _main():
print('starting at:', ctime())
nloops = randrange(2, 6)
print('THE CANDY MACHINE (full with %d bars)!' % max)
Thread(target=consumer, args=(randrange(nloops, nloops+max+2),)).start()
Thread(target=producer, args=(nloops,)).start()
@register
def _atexite():
print('all DONE at:', ctime())
if __name__ == '__main__':
_main()
这里面首先引入了一个叫B又能得到semaphore的方法,这个是一个计数器工厂函数,返回一个新的有界信号量对象。一个有界信号量会确保它当前的值不超过它的初始值。如果超过,则引发ValueError。在大部分情况下,信号量用于守护有限容量的资源。如果信号量被释放太多次,它是一种有bug的迹象。如果没有给出,value默认为1,调用 acquire() 会使这个计数器 -1,release() 则是+1.计数器的值永远不会小于 0,当计数器到 0 时,再调用 acquire() 就会阻塞,直到其他线程来调用release()
首先我们定义的refill和buy就是两个对立的,一个执行就+1,一个-1,我们这里是在设置顾客购买是设置了顾客数量nloops+max+2多了两个,所以只是时间问题,终究会被买完的,所以会停止,不然就一直循环了
('starting at:', 'Wed Jun 5 19:17:12 2019')
THE CANDY MACHINE (full with 5 bars)!
Buying candy...
Ok
Refilling candy...
Ok
Buying candy...
Ok
Refilling candy...
Ok
Buying candy...
Ok
Refilling candy...
Ok
Buying candy...
Ok
Buying candy...
Ok
Refilling candy...
Ok
Buying candy...
Ok
Buying candy...
Ok
Buying candy...
Ok
Buying candy...
Ok
Buying candy...
empty, skipping
('all DONE at:', 'Wed Jun 5 19:17:22 2019')
Process finished with exit code 0
9、queue模块
queue是一个提供线程间通信的模块,从而让线程间共享数据,它可用于在生产者(producer)和消费者(consumer)之间线程安全(thread-safe)地传递消息或其它数据,因此多个线程可以共用同一个Queue实例。Queue的大小(元素的个数)可用来限制内存的使用。
from random import randint
from time import sleep,ctime
from Queue import Queue
from myThread import MyThread
def writeQ(queue):
print('producing object for Q...')
queue.put('xxx', 1)
print('size now', queue.qsize())
def readQ(queue):
val = queue.get(1)
print('consumed object from Q... size now', queue.qsize())
def writer(queue, loops):
for i in range(loops):
writeQ(queue)
sleep(randint(1, 3))
def reader(queue, loops):
for i in range(loops):
readQ(queue)
sleep(randint(2, 5))
funcs = [writer, reader]
nfuncs = range(len(funcs))
def main():
nloops = randint(2, 5)
q = Queue(32)
threads = []
for i in nfuncs:
t = MyThread(funcs[i], (q, nloops), funcs[i].__name__)
threads.append(t)
for i in nfuncs:
threads[i].start()
for i in nfuncs:
threads[i].join()
print('all DONE ')
if __name__ == '__main__':
main()
本模块使用了Queue.Queue对象,和前面给的MyThread线程类,writeQ和readQ函数分别作用于将一个对象放入队列中和从队列中读取一个对象,write是为了放入一个对象,reader为读取一个对象,都是为了执行writeQ和readQ函数
('staritng', 'writer', 'at:', 'Wed Jun 5 20:58:08 2019')
producing object for Q...
('staritng', ('reader''size now', , 'at:'1, )'Wed Jun 5 20
:58:08 2019')
('consumed object from Q... size now', 0)
producing object for Q...
('size now', 1)
('consumed object from Q... size now', 0)
producing object for Q...
('size now', 1)
producing object for Q...
('size now', 2)
('writer', 'finished at:', 'Wed Jun 5 20:58:15 2019')
('consumed object from Q... size now', 1)
('consumed object from Q... size now', 0)
('reader', 'finished at:', 'Wed Jun 5 20:58:24 2019')
all DONE
Process finished with exit code 0
这里补充一些queue的属性:
queue.qsize() 返回队列的大小
queue.empty() 如果队列为空,返回True,反之False
queue.full() 如果队列满了,返回True,反之False
queue.full 与 maxsize 大小对应
queue.get([block[, timeout]])获取队列,timeout等待时间
queue.get_nowait() 相当queue.get(False)
queue.put(item) 写入队列,timeout等待时间
queue.put_nowait(item) 相当queue.put(item, False)
queue.task_done() 在完成一项工作之后,queue.task_done()函数向任务已经完成的队列发送一个信号
queue.join() 实际上意味着等到队列为空,再执行别的操作

















 1110
1110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









