







阅读笔记
sql中各种 count
结论
- innodb
count(*) ≈ count(1) > count(主键id) > count(普通索引列) > count(未加索引列)
-
myisam
有专门字段记录全表的行数,直接读这个字段就好了(innodb则需要一行行去算) -
如果确实需要获取行数,且可以接受不那么精确的行数(只需要判断大概的量级) 的话,那可以用explain里的rows,这可以满足大部分的监控场景,实现简单
-
如果要求行数准确 ,可以建个新表,里面专门放表行数的信息
-
如果对实时性要求比较高 的话,可以将更新行数的sql放入到对应事务里,这样既能满足事务隔离性,还能快速读取到行数信息
-
如果对实时性要求不高 ,接受一小时或者一天的更新频率,那既可以自己写脚本遍历全表后更新行数信息。也可以将通过监听binlog将数据导入hive,需要数据时直接通过hive计算得出
不同存储引擎计算方式
- count()方法的目的是计算当前sql语句查询得到的非NULL的行数
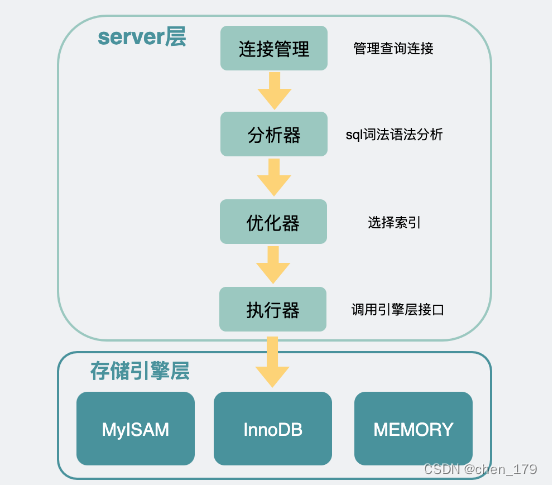
- 虽然在server层都叫count()方法,但在不同的存储引擎下,它们的实现方式是有区别的
-
- 比如同样是读全表数据
select count(*) from table (where *** );
当数据表小的时候,这是没问题的,但当数据量大的时候,比如未发送的短信到了百万量级 的时候,你就会发现,上面的sql查询时间会变得很长,最后timeout报错,查不出结果了 。
-
- 使用 myisam引擎 的数据表里有个记录当前表里有几行数据的字段,直接读这个字段返回就好了,因此速度快得飞起
-
- 使用innodb引擎 的数据表,则会选择体积最小的索引树 ,然后通过遍历叶子节点的个数挨个加起来,这样也能得到全表数据
区别
为什么innodb不能像myisam那样实现count()方法
-
最大的区别在于myisam不支持事务,而innodb支持事务
而事务,有四层隔离级别,其中默认隔离级别就是可重复读隔离级别(RR) -
- innodb引擎通过MVCC实现了可重复隔离级别 ,事务开启后,多次执行同样的select快照读 ,要能读到同样的数据。
-
- 对于两个事务A和B,一开始表假设就2条 数据,那事务A一开始确实是读到2条数据。事务B在这期间插入了1条数据,按道理数据库其实有3条数据了,但由于可重复读的隔离级别,事务A依然还是只能读到2条数据。
-
- 因此由于事务隔离级别的存在,不同的事务在同一时间下,看到的表内数据行数是不一致的 ,因此innodb,没办法,也没必要像myisam那样单纯的加个count字段信息在数据表上。
count() 类型
count方法的大原则是server层会从innodb存储引擎里读来一行行数据,并且只累计非null的值 。但这个过程,根据count()方法括号内的传参,有略有不同。
- count(*)
server层拿到innodb返回的行数据,不对里面的行数据做任何解析和判断 ,默认取出的值肯定都不是null,直接行数+1 - count(1)
server层拿到innodb返回的行数据,每行放个1进去,默认不可能为null,直接行数+1. -
- InnoDB 引擎遍历整张表,但不取值。server 层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加
- count(字段)
count(字段)是不统计,字段值为null的值 -
- count(主键 id) 来说,InnoDB 引擎会遍历整张表,把每一行的 id 值都取出来,返回给 server 层。server 层拿到 id 后,判断是不可能为空的,就按行累加
-
-
count(字段),server要字段,就返回字段,如果字段为空,就不做统计,字段的值过大,都会造成效率低下
由于指明了要count某个字段,innodb在取数据的时候,会把这个字段解析出来 返回给server层,所以会比count(1)和count(*)多了个解析字段出来的流程
-

责任链模式
- 责任链模式是一种行为设计模式, 允许你将请求沿着处理者链进行发送。收到请求后, 每个处理者均可对请求进行处理, 或将其传递给链上的下个处理者。
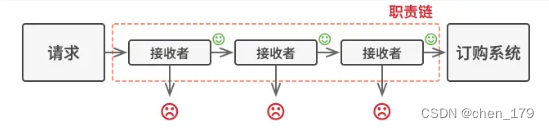
常见场景
- 多条件的流程判断(如导入文件校验条件较多,且需逐层校验成功的;或类似闯关游戏,必须达到一定分数/条件才能开始下一关)
导入功能可能【模板方法】更适合
-
- 模板方法可以提供大部分相同的【模板】,根据不同的导入场景做小部分调整,实现各自独立的业务,大体上导入功能差不多
-
- 一次性实现一个算法的不变部分,并将可变的行为留给子类来实现
-
- 各子类中公共的行为被提取出来并集中到一个公共父类中,从而避免代码重复

- 各子类中公共的行为被提取出来并集中到一个公共父类中,从而避免代码重复
- ERP 系统流程审批:总经理、人事经理、项目经理
- Java 过滤器的底层实现 Filter
例子(闯关游戏)
-
假设现在有一个闯关游戏,进入下一关的条件是上一关的分数要高于 xx:
-
游戏一共 3 个关卡
进入第二关需要第一关的游戏得分大于等于 80
进入第三关需要第二关的游戏得分大于等于 90
简易版(多层 if 逐层判断是否满足条件)
//第一关
public class FirstPassHandler {
public int handler(){
System.out.println("第一关-->FirstPassHandler");
return 80;
}
}
//第二关
public class SecondPassHandler {
public int handler(){
System.out.println("第二关-->SecondPassHandler");
return 90;
}
}
//第三关
public class ThirdPassHandler {
public int handler(){
System.out.println("第三关-->ThirdPassHandler,这是最后一关啦");
return 95;
}
}
//客户端
public class HandlerClient {
public static void main(String[] args) {
FirstPassHandler firstPassHandler = new FirstPassHandler();//第一关
SecondPassHandler secondPassHandler = new SecondPassHandler();//第二关
ThirdPassHandler thirdPassHandler = new ThirdPassHandler();//第三关
int firstScore = firstPassHandler.handler();
//第一关的分数大于等于80则进入第二关
if(firstScore >= 80){
int secondScore = secondPassHandler.handler();
//第二关的分数大于等于90则进入第二关
if(secondScore >= 90){
thirdPassHandler.handler();
}
}
}
}
- 实际上的 handle() 根据业务来传参及计算分数
- 缺点
当关数越多/条件越多时代码会变得很长,无限月读(if 嵌套)
if(第1关通过){
// 第2关 游戏
if(第2关通过){
// 第3关 游戏
if(第3关通过){
// 第4关 游戏
if(第4关通过){
// 第5关 游戏
if(第5关通过){
// 第6关 游戏
if(第6关通过){
//...
}
}
}
}
}
}
升级(责任链链表拼接每一关)
- 可以通过链表将每一关连接起来,形成责任链的方式,第一关通过后是第二关,第二关通过后是第三关… (减少客户端代码过多的 if 嵌套)
public class FirstPassHandler {
/**
* 第一关的下一关是 第二关
*/
private SecondPassHandler secondPassHandler;
public void setSecondPassHandler(SecondPassHandler secondPassHandler) {
this.secondPassHandler = secondPassHandler;
}
//本关卡游戏得分
private int play(){
return 80;
}
public int handler(){
System.out.println("第一关-->FirstPassHandler");
if(play() >= 80){
//分数>=80 并且存在下一关才进入下一关
if(this.secondPassHandler != null){
return this.secondPassHandler.handler();
}
}
return 80;
}
}
public class SecondPassHandler {
/**
* 第二关的下一关是 第三关
*/
private ThirdPassHandler thirdPassHandler;
public void setThirdPassHandler(ThirdPassHandler thirdPassHandler) {
this.thirdPassHandler = thirdPassHandler;
}
//本关卡游戏得分
private int play(){
return 90;
}
public int handler(){
System.out.println("第二关-->SecondPassHandler");
if(play() >= 90){
//分数>=90 并且存在下一关才进入下一关
if(this.thirdPassHandler != null){
return this.thirdPassHandler.handler();
}
}
return 90;
}
}
public class ThirdPassHandler {
//本关卡游戏得分
private int play(){
return 95;
}
/**
* 这是最后一关,因此没有下一关
*/
public int handler(){
System.out.println("第三关-->ThirdPassHandler,这是最后一关啦");
return play();
}
}
public class HandlerClient {
public static void main(String[] args) {
FirstPassHandler firstPassHandler = new FirstPassHandler();//第一关
SecondPassHandler secondPassHandler = new SecondPassHandler();//第二关
ThirdPassHandler thirdPassHandler = new ThirdPassHandler();//第三关
firstPassHandler.setSecondPassHandler(secondPassHandler);//第一关的下一关是第二关
secondPassHandler.setThirdPassHandler(thirdPassHandler);//第二关的下一关是第三关
//说明:因为第三关是最后一关,因此没有下一关
//开始调用第一关 每一个关卡是否进入下一关卡 在每个关卡中判断
firstPassHandler.handler();
}
}
- 缺点
从代码中可以看到,每一关的处理逻辑中都有一个 set**PassHandler() 方法,只是参数类型不一样,但是作用其实是一样的,只是用来判断是否有下一关
每个关卡中都有下一关的成员变量并且是不一样的,形成链很不方便,代码扩展性不行
进化(责任链改造—抽象)
- 每个关卡中都有下一关的成员变量并且是不一样的,那么我们可以在关卡上抽象出一个父类或者接口,然后每个具体的关卡去继承或者实现,将参数合并成一个,不再需要在各自的 set**PassHandler 中传递不同的参数
- 责任链设计模式的基本组成
-
- 抽象处理者(Handler)角色: 定义一个处理请求的接口,包含抽象处理方法和一个后继连接
-
- 具体处理者(Concrete Handler)角色: 实现抽象处理者的处理方法,判断能否处理本次请求,如果可以处理请求则处理,否则将该请求转给它的后继者
-
- 客户类(Client)角色: 创建处理链,并向链头的具体处理者对象提交请求,它不关心处理细节和请求的传递过程
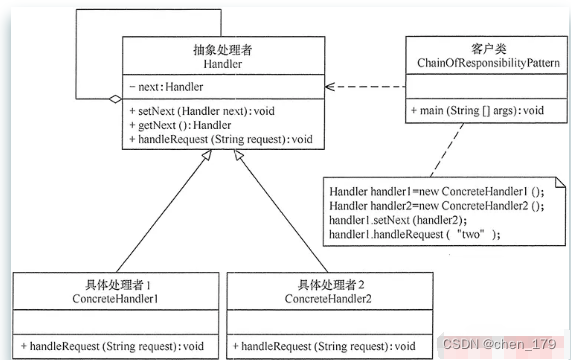
- 客户类(Client)角色: 创建处理链,并向链头的具体处理者对象提交请求,它不关心处理细节和请求的传递过程
public abstract class AbstractHandler {
/**
* 下一关用当前抽象类来接收
*/
protected AbstractHandler next;
public void setNext(AbstractHandler next) {
this.next = next;
}
public abstract int handler();
}
public class FirstPassHandler extends AbstractHandler{
private int play(){
return 80;
}
@Override
public int handler(){
System.out.println("第一关-->FirstPassHandler");
int score = play();
if(score >= 80){
//分数>=80 并且存在下一关才进入下一关
if(this.next != null){
return this.next.handler();
}
}
return score;
}
}
public class SecondPassHandler extends AbstractHandler{
private int play(){
return 90;
}
public int handler(){
System.out.println("第二关-->SecondPassHandler");
int score = play();
if(score >= 90){
//分数>=90 并且存在下一关才进入下一关
if(this.next != null){
return this.next.handler();
}
}
return score;
}
}
public class ThirdPassHandler extends AbstractHandler{
private int play(){
return 95;
}
public int handler(){
System.out.println("第三关-->ThirdPassHandler");
int score = play();
if(score >= 95){
//分数>=95 并且存在下一关才进入下一关
if(this.next != null){
return this.next.handler();
}
}
return score;
}
}
public class HandlerClient {
public static void main(String[] args) {
FirstPassHandler firstPassHandler = new FirstPassHandler();//第一关
SecondPassHandler secondPassHandler = new SecondPassHandler();//第二关
ThirdPassHandler thirdPassHandler = new ThirdPassHandler();//第三关
// 和上面没有更改的客户端代码相比,只有这里的set方法发生变化,其他都是一样的
firstPassHandler.setNext(secondPassHandler);//第一关的下一关是第二关
secondPassHandler.setNext(thirdPassHandler);//第二关的下一关是第三关
//说明:因为第三关是最后一关,因此没有下一关
//从第一个关卡开始
firstPassHandler.handler();
}
}
- 从代码中可以看到,此次进化引入了一个 抽象处理者,让每一关的具体处理者都继承该类,后续在设置下一关对象的时候就不必各自编写各自的set**PassHandler() 方法,而是直接使用相同的处理方法,只需要编写各自的 handler() 得分方法,进一步简化了代码
终极进化(责任链工厂改造)
public enum GatewayEnum {
// handlerId, 拦截者名称,全限定类名,preHandlerId,nextHandlerId
API_HANDLER(new GatewayEntity(1, "api接口限流", "cn.dgut.design.chain_of_responsibility.GateWay.impl.ApiLimitGatewayHandler", null, 2)),
BLACKLIST_HANDLER(new GatewayEntity(2, "黑名单拦截", "cn.dgut.design.chain_of_responsibility.GateWay.impl.BlacklistGatewayHandler", 1, 3)),
SESSION_HANDLER(new GatewayEntity(3, "用户会话拦截", "cn.dgut.design.chain_of_responsibility.GateWay.impl.SessionGatewayHandler", 2, null)),
;
GatewayEntity gatewayEntity;
public GatewayEntity getGatewayEntity() {
return gatewayEntity;
}
GatewayEnum(GatewayEntity gatewayEntity) {
this.gatewayEntity = gatewayEntity;
}
}
public class GatewayEntity {
private String name;
private String conference;
private Integer handlerId;
private Integer preHandlerId;
private Integer nextHandlerId;
}
public interface GatewayDao {
/**
* 根据 handlerId 获取配置项
* @param handlerId
* @return
*/
GatewayEntity getGatewayEntity(Integer handlerId);
/**
* 获取第一个处理者
* @return
*/
GatewayEntity getFirstGatewayEntity();
}
public class GatewayImpl implements GatewayDao {
/**
* 初始化,将枚举中配置的handler初始化到map中,方便获取
*/
private static Map<Integer, GatewayEntity> gatewayEntityMap = new HashMap<>();
static {
GatewayEnum[] values = GatewayEnum.values();
for (GatewayEnum value : values) {
GatewayEntity gatewayEntity = value.getGatewayEntity();
gatewayEntityMap.put(gatewayEntity.getHandlerId(), gatewayEntity);
}
}
@Override
public GatewayEntity getGatewayEntity(Integer handlerId) {
return gatewayEntityMap.get(handlerId);
}
@Override
public GatewayEntity getFirstGatewayEntity() {
for (Map.Entry<Integer, GatewayEntity> entry : gatewayEntityMap.entrySet()) {
GatewayEntity value = entry.getValue();
// 没有上一个handler的就是第一个
if (value.getPreHandlerId() == null) {
return value;
}
}
return null;
}
}
public class GatewayHandlerEnumFactory {
private static GatewayDao gatewayDao = new GatewayImpl();
// 提供静态方法,获取第一个handler
public static GatewayHandler getFirstGatewayHandler() {
GatewayEntity firstGatewayEntity = gatewayDao.getFirstGatewayEntity();
GatewayHandler firstGatewayHandler = newGatewayHandler(firstGatewayEntity);
if (firstGatewayHandler == null) {
return null;
}
GatewayEntity tempGatewayEntity = firstGatewayEntity;
Integer nextHandlerId = null;
GatewayHandler tempGatewayHandler = firstGatewayHandler;
// 迭代遍历所有handler,以及将它们链接起来
while ((nextHandlerId = tempGatewayEntity.getNextHandlerId()) != null) {
GatewayEntity gatewayEntity = gatewayDao.getGatewayEntity(nextHandlerId);
GatewayHandler gatewayHandler = newGatewayHandler(gatewayEntity);
tempGatewayHandler.setNext(gatewayHandler);
tempGatewayHandler = gatewayHandler;
tempGatewayEntity = gatewayEntity;
}
// 返回第一个handler
return firstGatewayHandler;
}
/**
* 反射实体化具体的处理者
* @param firstGatewayEntity
* @return
*/
private static GatewayHandler newGatewayHandler(GatewayEntity firstGatewayEntity) {
// 获取全限定类名
String className = firstGatewayEntity.getConference();
try {
// 根据全限定类名,加载并初始化该类,即会初始化该类的静态段
Class<?> clazz = Class.forName(className);
return (GatewayHandler) clazz.newInstance();
} catch (ClassNotFoundException | IllegalAccessException | InstantiationException e) {
e.printStackTrace();
}
return null;
}
}
public class GetewayClient {
public static void main(String[] args) {
GetewayHandler firstGetewayHandler = GetewayHandlerEnumFactory.getFirstGetewayHandler();
firstGetewayHandler.service();
}
}
- 待深究
模版方法
- 模板模式一般只针对一套算法,注重对同一个算法的不同细节进行抽象提供不同的实现
适用于某些业务整体业务流程固定,只有内部一些小细节有不同的场景 - 例
现有不同入门、铂金、黄金等不同等级的会员,每个等级的会员升级都会触发各自的升级礼
等级信息查询 -> 更新等级信息 -> 赠送升级礼物(比如根据不同等级赠送不同积分) -> 通知用户升级信息
那么,赠送不同等级升级礼物就可以抽象出来,每个等级各自独立“执行等级礼品赠送逻辑” -
- JDBCTemplate、RedisTemplate、MongoTemplate
代码实现(简易版)
public abstract class MemberUp {
/**
* 模板方法:
* final 不让子类覆盖
*/
final void levelUp() {
queryMemberInfo();
updateMemberInfo();
if(customerWantCondiments()) {
reward();
}
notifyMember();
}
// 钩子方法,决定是否需要添加配料
// 钩子方法的一个主要作用就是为了在父类中统一控制子类的行为。通过在父类中定义钩子方法,可以为子类提供一个统一的接口,用来控制算法的某些方面。
// 在模板方法模式中,父类中的模板方法定义了算法的骨架,而钩子方法则允许子类在该算法的特定点进行定制。这样一来,子类可以根据需要选择是否重写钩子方法,从而影响模板方法的行为。
// 方便统一管理是否开启各自独立逻辑,若不需要,则直接在子类重写的抽象方法中实现即可
boolean customerWantCondiments() {
return true;
}
void queryMemberInfo() {
System.out.println("查询用户等级信息");
}
void updateMemberInfo() {
System.out.println("更新会员等级信息");
}
void notifyMember() {
System.out.println("通知用户等级变更");
}
/**
* 抽象类(具体由子类完成)
*/
abstract void reward();
}
public class LevelOne extends MemberUp {
@Override
void reward() {
System.out.println("入会会员,赠送升级礼20积分");
}
}
public class LevelTwo extends MemberUp {
@Override
void reward() {
System.out.println("铂金会员,赠送升级礼50积分");
}
}
public class LevelThree extends MemberUp {
@Override
void reward() {
System.out.println("黄金会员,赠送升级礼200积分");
}
}
public class test {
public static void main(String[] args) {
System.out.println("入门会员升级");
LevelOne one = new LevelOne();
one.levelUp();
System.out.println("-------");
System.out.println("铂金会员升级");
LevelTwo two= new LevelTwo ();
two.levelUp();
System.out.println("-------");
System.out.println("黄金会员升级");
LevelThree three= new LevelThree ();
three.levelUp();
System.out.println("-------");
}
}

策略模式
- 策略模式注重 多套算法 多种实现,在算法中间没有交集,因此算法和算法只间一般不会有冗余代码
简单来说就是提前把不同场景的代码逻辑准备好,封装进一个map里,运行的时候根据不同场景使用不同的key来决定运行什么样的逻辑处理对应的问题,个人觉得可以把他当做模板方法的变态升级版——从大家有一套共同的主流程,只有部分不同演变为【删除共同部分,各自保留自己独立的逻辑】 - 例
文件解析功能,假设有一个文件解析接口,兼容多种文件类型数据的解析与数据提取保存(txt类型,xlsx类型,csv类型…),当文件类型较少时,可以通过简单那的 if-else 处理,但当文件类型数量较多时,使用 if-else 会使代码变得冗余难以维护(违背了面向对象编程的开闭原则以及单一原则)
因此可以使用 策略模式 来优化(同一个功能针对不同业务场景使用不同的算法逻辑进行处理) -
- Spring MVC中各种处理handler
代码实现(简易版)
- 一个接口/抽象类,提供两个方法(匹配类型,待重写具体业务逻辑的方法)
- 不同策略的差异化实现
- 使用策略模式
原始代码
解析不同文件类型功能
if(type=="A"){
//按照A格式解析
}else if(type=="B"){
//按B格式解析
}else{
//按照默认格式解析
}
策略模式
public interface IFileStrategy {
/**
* 属于哪种文件解析类型
* @return
*/
FileTypeResolveEnum gainFileType();
/**
* 封装的公用算法(具体的解析方法)
* @param param
*/
void resolve(String param);
}
public enum FileTypeResolveEnum {
TXT_TYPE(1,"txt格式"),
EXCEL_TYPE(2,"xlsx格式"),
CSV_TYPE(3,"csv格式"),
;
public Integer key;
public String label;
FileTypeResolveEnum(Integer key, String label) {
this.key = key;
this.label = label;
}
}
@Component
public class AFileResolve implements IFileStrategy {
@Override
public FileTypeResolveEnum gainFileType() {
return FileTypeResolveEnum.TXT_TYPE;
}
@Override
public void resolve(String param) {
System.out.println("开始解析txt类型文件,文件名称:" + param);
}
}
@Component
public class BFileResolve implements IFileStrategy {
@Override
public FileTypeResolveEnum gainFileType() {
return FileTypeResolveEnum.EXCEL_TYPE;
}
@Override
public void resolve(String param) {
System.out.println("开始解析excel类型文件,文件名称:" + param);
}
}
@Component
public class CFileResolve implements IFileStrategy {
@Override
public FileTypeResolveEnum gainFileType() {
return FileTypeResolveEnum.CSV_TYPE;
}
@Override
public void resolve(String param) {
System.out.println("开始解析cav类型文件,文件名称:" + param);
}
}
/**
* 初始化
* 使用ApplicationContextAware接口,把对用的策略,初始化到map里面。然后对外提供resolveFile方法
*/
@Component
public class StrategyUseService implements ApplicationContextAware {
/**
* 策略初始化存放map,不同类型及策略,注意使用 ConcurrentHashMap
*/
private Map<FileTypeResolveEnum, IFileStrategy> iFileStrategyMap = new ConcurrentHashMap<>();
/**
* 根据不同类型,使用不同策略进行处理
* @param fileTypeResolveEnum 文件类型
* @param param 相关参数
*/
public void resolveFile(FileTypeResolveEnum fileTypeResolveEnum, String param) {
IFileStrategy iFileStrategy = iFileStrategyMap.get(fileTypeResolveEnum);
if (iFileStrategy != null) {
iFileStrategy.resolve(param);
}
}
/**
* 初始化策略信息
* @param applicationContext
* @throws BeansException
*/
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
// 获取bean-名称:bean-实例
Map<String, IFileStrategy> tempMap = applicationContext.getBeansOfType(IFileStrategy.class);
// 遍历每个实现类,将类型与实例进行绑定,后续根据类型即可使用对应的策略
tempMap.values().forEach(strategyService -> iFileStrategyMap.put(strategyService.gainFileType(), strategyService));
}
}
/**
* 省略 controller
*/
@Service
public class testService {
private StrategyUseService strategyUseService;
@Autowired
public BannerService(StrategyUseService strategyUseService) {
this.strategyUseService = strategyUseService;
}
public void test() {
strategyUseService.resolveFile(FileTypeResolveEnum.TXT_TYPE, "txt file");
strategyUseService.resolveFile(FileTypeResolveEnum.EXCEL_TYPE, "excel file");
strategyUseService.resolveFile(FileTypeResolveEnum.CSV_TYPE, "csv file");
}
}
观察者模式
- 观察者模式,也称 发布-订阅 模式,通常有一个【被观察者】去注册一个或多个【观察者】,且【观察者】之间的行为可以有差异
- 例
- 老王爱钓鱼,钓的鱼供给给店铺A,店铺B,店铺C;
ABC需要留意老王钓鱼结果(老王被ABC观察——被观察者),钓到了就可以把鱼拿来做各种美食,A拿来做红烧鱼;B拿来做清蒸鱼;C拿来做鱼生(观察者之间行为可以有差异) - 用户ABC都是店铺00的粉丝,订阅了店铺00的商品上新,当店铺有商品上新时就告知ABC有商品上新了(发布-订阅,此处观察者行为一样,简单接收一下上新通知)
- 老王爱钓鱼,钓的鱼供给给店铺A,店铺B,店铺C;
代码实现(简易版)
基于接口的实现
- 场景:假设现在小明,小黑,大伟都是店铺的粉丝,且订阅了商品上新,商品后台有商品新增就通知一下,小明小黑短信通知,大伟公众号通知
代码中的 MemberInfo,ExchangeProduct 根据实际需要来
代码中省略了一步从 订阅表 查询需要通知的用户
及对应通知类型的数据筛选操作,根据实际情况来
/**
* 被观察者
* @Author: chen
*/
public class ProductObservable {
private List<Observer> observers = new ArrayList<>();
private ExchangeProduct exchangeProduct;
/**
* 添加观察者
* @param observer
*/
public void addObserver(Observer observer) {
observers.add(observer);
}
/**
* 删除观察者
* @param observer
*/
public void removeObserver(Observer observer) {
observers.remove(observer);
}
/**
* 更新商品信息并通知观察者
* @param exchangeProduct
*/
public void updateProductInfo(ExchangeProduct exchangeProduct) {
this.exchangeProduct = exchangeProduct;
notifyObservers();
}
/**
* 通知观察者商品变动信息
*/
private void notifyObservers() {
System.out.println(observers.size());
for (Observer item : observers) {
item.updateProductInfoAndNotify(exchangeProduct);
}
}
}
/**
* 观察者接口
* @Author: chen
*/
public interface Observer {
/**
* 更新商品信息并通知用户
*/
void updateProductInfoAndNotify(ExchangeProduct exchangeProduct);
}
/**
* 短信类型观察者
* @Author: chen
*/
public class MemberSMSNotifier implements Observer{
private MemberInfo memberInfo;
public MemberSMSNotifier(MemberInfo memberInfo) {
this.memberInfo = memberInfo;
}
@Override
public void updateProductInfoAndNotify(ExchangeProduct exchangeProduct) {
// todo 业务处理,短信通知用户具体变更信息
System.out.println("短信通知:hello" + memberInfo.getNickName()
+ ", the product info has change, product info = " + exchangeProduct.getProductName());
}
}
/**
* 公众号类型观察者
* @Author: chen
*/
public class MemberMPNotifier implements Observer {
private MemberInfo memberInfo;
public MemberMPNotifier(MemberInfo memberInfo) {
this.memberInfo = memberInfo;
}
@Override
public void updateProductInfoAndNotify(ExchangeProduct exchangeProduct) {
// todo 业务处理,公众号通知用户具体变更信息
System.out.println("公众号通知:hello" + memberInfo.getNickName()
+ ", the product info has change, product info = " + exchangeProduct.getProductName());
}
}
// todo 简单接口
@GetMapping("/test/test")
public void test() {
ExchangeProduct exchangeProduct = new ExchangeProduct();
exchangeProduct.setProductName("吼吼吼");
// 创建被观察者
ProductObservable productObservable = new ProductObservable();
// todo 实际场景中这里需要根据订阅表信息,查询订阅的用户信息
// 再根据通知类型筛选过滤(短信通知 or 公众号通知)
// ps:不同类型条件用户的筛选,直接查询所有订阅用户信息,然后放在代码 stream() 处理一下就好了
// 没必要根据 通知类型 作为条件查询多次获得对应的通知用户人群
MemberInfo notifyUser1 = new MemberInfo();
MemberInfo notifyUser2 = new MemberInfo();
notifyUser1.setNickName("小明");
notifyUser2.setNickName("小黑");
MemberSMSNotifier notifier1 = new MemberSMSNotifier(notifyUser1);
MemberSMSNotifier notifier2 = new MemberSMSNotifier(notifyUser2);
MemberInfo notifyUser3 = new MemberInfo();
notifyUser3.setNickName("大伟");
MemberMPNotifier notifier3 = new MemberMPNotifier(notifyUser3);
// 注册观察者
productObservable.addObserver(notifier1);
productObservable.addObserver(notifier2);
productObservable.addObserver(notifier3);
// 更新商品信息
productObservable.updateProductInfo(exchangeProduct);
}

- 这里其实不用观察者模式也能实现,在查询出订阅用户及筛选通知类型后根据不同的方式 for 循环通知即可,但是当通知的类型越多,需要硬编码加入的代码也越多,使用观察者模式可以具有解耦性、灵活性、可复用性,被观察者对象无需知道具体的观察者,只需通知观察者即可。这样,在系统中添加新的观察者或者移除现有的观察者都比较容易,不会影响到被观察者。
当有新的通知类型时,只需要新增一个新的观察者类型即可,类型越多,优势效果越明显(如果是简单的业务个人感觉可以不要使用该种模式)
基于类的实现
- Java 标准库中的 Observable 类或 Subject 类(偷懒不上代码了)
在Java中,有两种主要的观察者模式的实现方式:基于接口的实现和基于类的实现。
对比
基于接口的实现(Observer 接口):
这种实现方式是通过让观察者类实现一个接口来达到观察者模式的效果。在这种实现方式中,被观察者(主题)类通常并不需要继承任何特定的类,而是在内部维护一个观察者列表,并提供注册、移除和通知观察者的方法。这种实现方式更加灵活,因为观察者只需要实现一个接口即可,不需要强制继承特定的类。
基于类的实现(Observable 类或 Subject 类):
这种实现方式是通过让被观察者继承一个特定的类来实现观察者模式。Java标准库提供了 java.util.Observable 类来实现被观察者,观察者则通过继承 java.util.Observer 接口来实现。在这种实现方式中,被观察者和观察者之间的关系更加紧密,因为它们都必须遵循Java标准库定义的接口或类。
异步编程
- CompletionService
批量任务的异步处理
CompletionService 主要用于批量任务的异步处理。你可以将多个任务提交给 CompletionService,然后通过 CompletionService 获取这些任务的结果,而不需要手动管理线程池和 Future 对象。
分离任务提交和结果获取
CompletionService 将任务提交和结果获取分离开来,使得代码更清晰、更易于维护。
结果按照完成顺序获取:
CompletionService 可以按照任务完成的顺序获取结果,这对于需要按照任务完成顺序处理结果的场景非常有用。
使用 Executor 实现: CompletionService 内部使用 Executor 来管理线程池,可以灵活地配置线程池参数。
- CompletableFuture(实现 Future 接口)
单个任务的异步处理:
CompletableFuture 主要用于单个任务的异步处理。你可以创建一个 CompletableFuture 对象,然后在其上应用各种操作,比如 map、thenApply、thenCompose 等,来构建一个异步任务链。
依赖链式结构
CompletableFuture 支持链式操作,使得任务之间可以方便地组合和串行化。
灵活性:
CompletableFuture 提供了非常灵活的方式来处理异步任务的结果,包括处理正常结果和异常结果、方便地处理异步任务的完成、异常和组合。
示例
long start = System.currentTimeMillis();
// 异步查询
CompletableFuture<Void> future1 = CompletableFuture.runAsync(()->{
// todo
Thread.sleep(10000);
});
// 异步查询
CompletableFuture<Void> future3 = CompletableFuture.runAsync(()->{
// todo
Thread.sleep(15000);
});
// 阻塞等待任务全部完成
CompletableFuture.allOf(future1, future3).join();
long end = System.currentTimeMillis();
// 理论上是取时间最长的一次耗时,也就是 15000ms = 15s
System.out.println("total cost = " + (end - start));

踩坑
以上代码表面上是可以直接用的,但是实际生产环境由于并发等问题可能导致,多个异步处理总耗时不一定每次都是≈耗时最长一次执行的时间,可能会变成是多个处理耗时累加
原因:CompletableFuture 默认使用 ForkJoinPool.commonPool() 线程池,它是一个全局共享的线程池(核心线程数=核心数 - 1),当任务较多时会出现 “异步失效”,“耗时过长” 情况
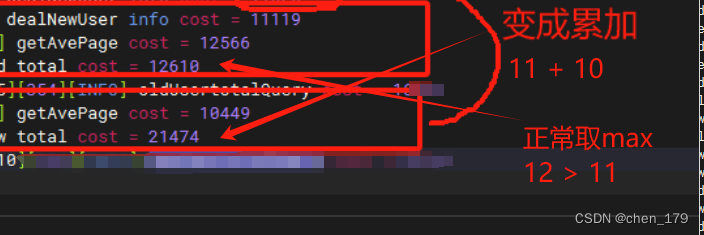
解决:使用自定义线程池(仅供参考)
// 自定义线程池,不使用默认的全局共享 ForkJoinPool.commonPool()
ExecutorService customThreadPool = Executors.newFixedThreadPool(2);
long start = System.currentTimeMillis();
// 异步查询
CompletableFuture<Void> future1 = CompletableFuture.runAsync(()->{
// todo
Thread.sleep(10000);
}, customThreadPool);
// 异步查询
CompletableFuture<Void> future3 = CompletableFuture.runAsync(()->{
// todo
Thread.sleep(15000);
}, customThreadPool);
// 阻塞等待任务全部完成
CompletableFuture.allOf(future1, future3).join();
long end = System.currentTimeMillis();
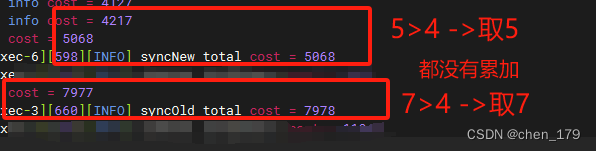
// 理论上是取时间最长的一次耗时,也就是 15000ms = 15s
System.out.println("newFixedThreadPool total cost = " + (end - start));
customThreadPool.shutdown();

CompletableFuture
CompletionService
- Future+Callable
密文模糊查询
某些涉及用户隐私的业务场景下,为了隐私安全通常会对用户的部分数据进行加密保存(如:手机号码,个人住址,身份证号码等,明文加密成密文保存数据库)
- 如果不需要模糊查询,那么可以直接在查询接口中将查询参数加密后去匹配
- 如果需要模糊查询,由于数据已被加密保存,不管是将参数明文、或将参数按相同加密方式加密后去数据库模糊匹配都无法查到,与完整数据明文加密后的结果不符
解决方案
-
提前解密
提前查询出目标表中所有数据,并提前将所要查询的数据/字段进行解密,将结果保存到内存/缓存中,遍历解密后得到的数据进行模糊匹配,筛选出符合条件的数据
优点:简单粗暴
缺点:模糊查询过程中在内存中进行,数据量较大时准备OOM吧 -
明文映射表
创建一张映射表,用来映射加密后的数据跟原文数据,模糊查询时先去明文映射表中查询匹配数据,通过得到的映射主键,再去目标数据表中查询数据
优点:简单粗暴
缺点:脱裤子**,为了安全才加密,又搞一个明文表… -
数据库层解密查询
使用数据库自带解密函数,先将目标表关键字段进行解密后再模糊查询
select * from sys_person where AES_DECRYPT(phone,'key') like '%0537'
优点:易实现
缺点:
无法使用索引;
程序的加解密算法不一定与数据库自身加解密算法一致,可能导致无法解密或者解密结果不符合预期,不好维护
- 分词密文匹配(参考淘宝)
目前较为主流的方法
原理是对原文数据进行拆分分组(4个字符至少),依次按组进行加密后保存到分词密文映射表中(有点类似明文映射表,只不过这里存的是密文)
模糊查询时对关键字进行加密后到密文映射表中查询,匹配到数据后根据主键去目标数据表中匹配数据返回
例子
- 手机号码15521213434
- 明文分组:1552,5521,5212 …
- 逐组加密:对1552进行加密保存,对5521进行加密保存…
- 模糊查询:输入参数1552,对参数进行加密,密文映射表中进行匹配,符合条件的记录返回目标表主键,查询目标表数据返回
优点:易实现
缺点:
明文加密后长度变长,存储成本查询性能成本变高;
明文越长,分词组合越多,需要的存储空间越大,查询性能降低;
分词越短,被破解可能性越大,安全性可能降低(按需设置)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









