 SQL练习题解析
SQL练习题解析





 本文精选了部分SQL练习题,包括查询课程成绩对比、查询特定教师授课学生信息等内容,通过实例讲解了SQL联结方法和子查询技巧。
本文精选了部分SQL练习题,包括查询课程成绩对比、查询特定教师授课学生信息等内容,通过实例讲解了SQL联结方法和子查询技巧。
本文没有完全收录网上SQL练习经典50题,只放了一些个人觉得有价值的题目,建议使用的时候反查题目。数据库,表,数据及字段来源:https://blog.youkuaiyun.com/weixin_44167164/article/details/85090602
经典练习-SQL-经典题目(1)
https://blog.youkuaiyun.com/weixin_44167164/article/details/86519335
题目
1、
题干1:查询”01”课程比”02”课程成绩高的学生的信息及课程分数
题干2:查询"01"课程比"02"课程成绩低的学生的信息及课程分数
表:student、score
字段:student.*,score.s_s_score
条件:01课程成绩>02课程成绩
等价代换:
01课程成绩=(student联结score中score.c_id=’01’)这个联结表中的s_s_score
02课程成绩=(student联结score中score.c_id=’02’)这个联结表中的s_s_score
借题干1、2,着重说一下3种常见的联结方法:
(1)多张表一块写,没有分步:
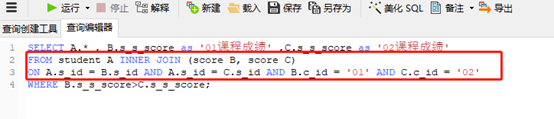

注:on+多个and ,和where 某些情况可以互换使用的。看采取什么方式的嵌套,方便使用on+多个and, 还是where。
(2)每张表分开写,分步骤:类似1+2+3,先算1+2,然后结果再+3
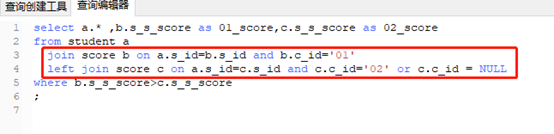
(3)分步骤,从里往外写,类似于1+(2+3)
x join (xxx join xxx on xxx) on xxx
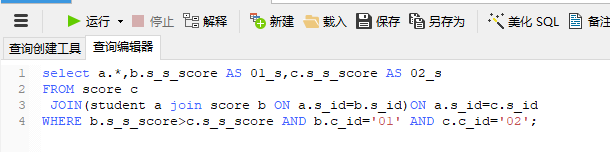
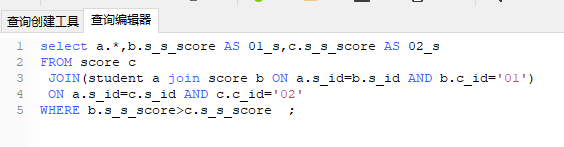
题干3:查询“001”课程比“002”课程成绩高的所有学生的学号
表:score
字段:s_id
条件:01课程成绩>02课程成绩
等价代换:
01课程成绩=(select s_s_score from score where c_id=’01’)视图中的s_s_score
02课程成绩=(select s_s_score from score where c_id=’01’)视图中的s_s_score
Select s_id
From(select s_s_score from score where c_id=’01’)a,
(select s_s_score from score where c_id=’02’)b
where a.sid = b.sid and a.score>b.score;
为什么要写a.sid = b.sid,表示查询是在一个表中进行,两个表没有进行交叉联结。
2、
题干1:查询学过"张三"老师授课的同学的信息
联结:
select st.*
from student st
join score s on s.s_id =st.s_id
join course c on c.c_id=s.c_id
join teacher t on c.t_id=t.t_id
where t.t_name='张三';或者(where t.t_name like '张%三');
子查询:
select * from student where s_id
in(select s_id from score where c_id
in(select c_id from course where t_id
in(select t_id from teacher where t_name='张三')));
题干2:查询没学过"张三"老师授课的同学的信息
着重说下题干2。题干2和题干1结果应该刚好相反,按照最简单的逻辑,用题干1的子查询直接取反(not in)就可以了。注意是给最外层的、最后的子查询集合取反。而不是每一层子查询都取反。
select * from student
where s_id
not in(select s_id from score where c_id
in(select c_id from course where t_id
in(select t_id from teacher where t_name='张三' )));
还有一种在联结上面取反,是给最后的联结集合取反,而不是联结条件取反或者每个联结取反。注意区别。
SELECT student.*
FROM student
where student.s_id not in
(select st.s_id from student st
join score s on s.s_id =st.s_id
join course c on c.c_id=s.c_id
join teacher t on c.t_id=t.t_id where t.t_name='张三');
另外说下一种错误:当时想的是把联结做成一个视图lianjie,利用视图lianjie和student表做笛卡尔积,条件取反即可。
CREATE VIEW lianjie AS(
select st.s_id
from student st
join score s on s.s_id =st.s_id
join course c on c.c_id=s.c_id
join teacher t on c.t_id=t.t_id where t.t_name='张三');
SELECT student.*
FROM lianjie,student
where student.s_id NOT in lianjie.s_id;
逻辑是正确的,但是语法出错。
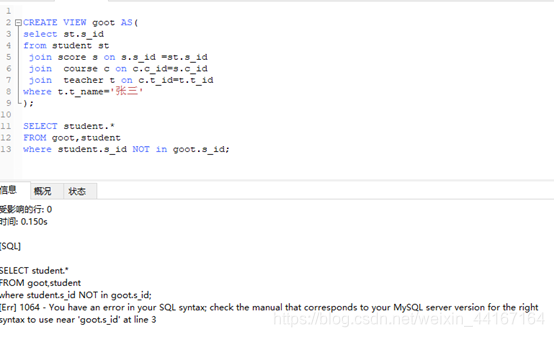
原因是,in后面只能取subquery(子集)、和非单值。其他一律语法报错。

















 1797
1797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









