






文章目录
前言
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
一、Flink
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
- 计算框架:类似MapReduce框架,分析数据
- 分布式计算框架,分析处理数据时可以启动多个task并行计算
- 建在数据流dataStream之上的状态计算框架
- 静态数据:Bounded Data Stream,有界数据流
- 动态数据:Unbounded Data Stream,无界数据流,流式数据
- 状态计算,即记录处理的数据的状态信息
Flink 1.12版本,里程碑版本,流批一体化编程模式,并且Flink Table API和SQL成熟稳定,可以用于实际生产环境。
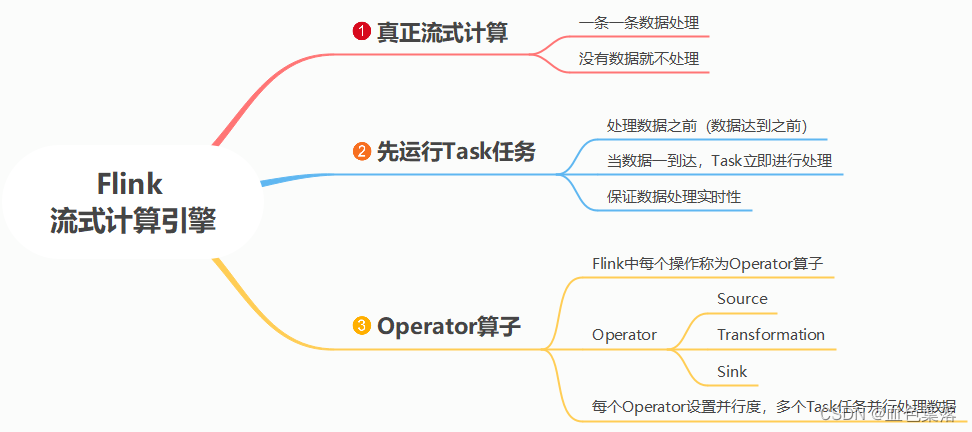
1.flink处理数据流程
Flink 流式计算程序,来一条数据处理一条数据,每次处理一条数据,真正流计算
-
第一步、从数据源获取数据时,将数据封装到数据流DataStream,实际项目,主要从Kafka 消息队列中消费数据
-
第二步、数据处理时,调用DataStream方法DataStream#transformation,类似RDD中转换算子,比如map、flatMap、filter等等
-
第三步、将分析数据输出到外部存储DataStream#sink,类似RDD中触发/输出算子,比如foreach…
flink的任务运行在资源槽中,在flink数据转换的过程中,一对一的转换操作可以在同一个槽中运行,相同的task任务运行在不同的槽中,即任务的并行度,最大并行度不超过槽的个数。
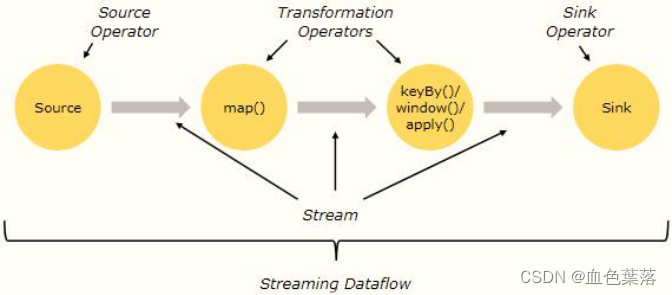
在数据处理过程中有两个概念:
- 算子 Operator :无论是从数据源Source加载数据,还是调用方法转换Transformation处理数据,到最后数据终端Sink输出,都称为Operator,分为:Source Operator、Transformation Operator和Sink Operator。
- 流 Stream:数据从一个Operator流向另一个Operator;
2.flink应用场景
-
事件驱动Event-driven Applications
- 事件驱动型应用是一类具有状态的应用,会根据事件流中的事件触发计算、更新状态或进行外部系统操作。事件驱动型应用常见于实时计算业务中,比如:实时推荐,金融反欺诈,实时规则预警等。
-
数据分析型应用Data Analytics Applications
- 数据体量大,并且对实时性要求较高,如实时销售大屏
-
数据管道型应用 (ETL)Data Pipeline Applications
- ETL数据抽取、转换、加载的操作,要求在分秒级别完成
3.flink架构
-
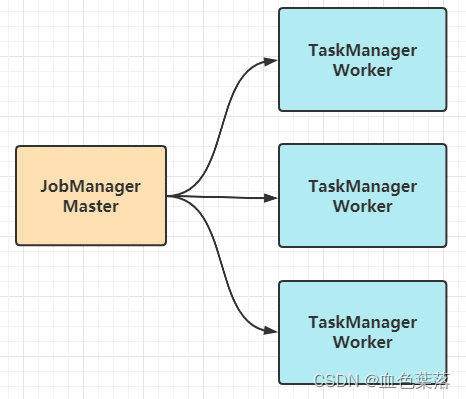
1)、JobManager:主节点Master,为每个Flink Job分配资源,管理和监控Job运行。
- 主要负责调度 Flink Job 并协调 Task 做 checkpoint;
- 从 Client 处接收到 Job 和JAR 包等资源后,会生成优化后的执行计划,并以 Task 为单元调度到各个 TaskManager去执行;
-
2)、TaskManager:从节点Workers,调度每个Job中Task任务执行,及负责Task监控和容错等。
- 在启动的时候设置:
Slot 槽位数(资源槽),每个 slot 能启动 Task,其中Task 为线程。
- 在启动的时候设置:
4.flink运行模式
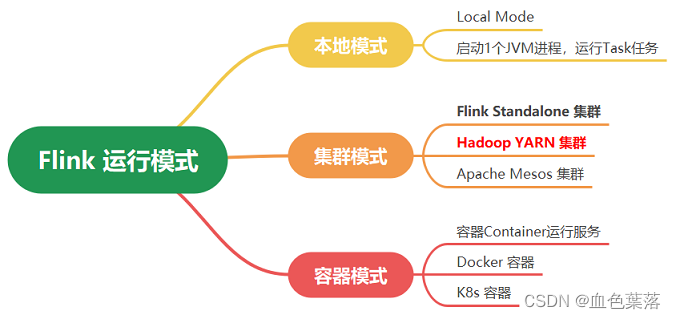
第一、Local 模式
在Windows系统上IDEA集成开发环境编写Flink 代码程序,直接运行测试即为本地测试
-
适用于本地开发和测试环境,占用的资源较少,部署简单
-
本地模式LocalMode:JobManager和TaskManager运行在同一个JVM进程中
第二、Standalone 模式
将JobManager和TaskManagers直接运行机器上,称为Standalone集群,Flink框架自己集群
- 可以在测试环境功能验证完毕到版本发布的时候使用,进行性能验证
第三、Flink On Yarn 模式
将JobManager和TaskManagers运行在NodeManage的Container容器中,称为Flink on YARN。
- Flink使用YARN进行调度
第四、K8s 模式
将JobManager和TaskManagers运行在K8s容器Container中。
- 由于Flink使用的无状态模式,只需要kubernetes提供计算资源即可。会是Flink以后运行的主流方式,可以起到节约硬件资源和便于管理的效果。
5.flink不同模式运行流程
- local本地模式
- Flink程序(比如jar包)由
JobClient进行提交; - JobClient将作业提交给
JobManager; - JobManager负责协调资源分配和作业执行。资源分配完成后,任务将提交给相应的
TaskManager; - TaskManager启动一个线程以开始执行。TaskManager会向JobManager报告状态更改,如开始执行,正在进行或已完成;
- 作业执行完成后,结果将发送回客户端(JobClient)
flink自带的web ui界面:http://node1:8081
通过命令运行程序:
/export/server/flink-local/bin/flink run
–class flink.StreamWordCount
/export/server/flink-local/StreamWordCount.jar
–host node1 --port 9999
指定处理数据文件和输出数据目录,分别通过–input 和 --output 传递参数值
- Standalone集群运行流程
- Client客户端提交任务给JobManager;
- JobManager负责申请任务运行所需要的资源并管理任务和资源;
- JobManager分发任务给TaskManager执行;
- TaskManager定期向JobManager汇报状态;
在standalone集群中存在主节点单点故障,搭建高可用需要借助zk配置standby主节点,当activate jobmanager挂机时,standby上位
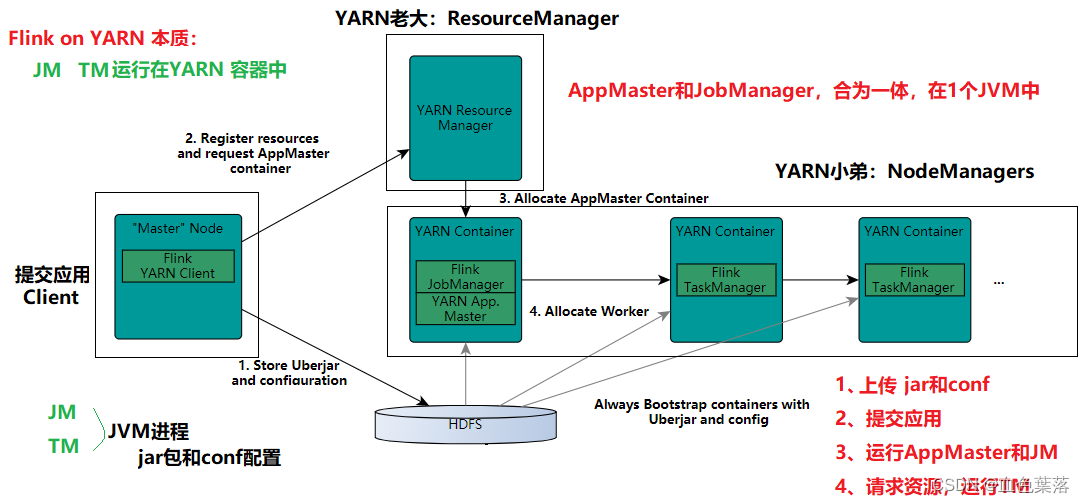
- flink on yarn,其本质是flink任务运行在Contanier容器中
- JobManager 进程和 TaskManager 进程都由 Yarn NodeManager 监控;
- 如果 JobManager 进程异常退出,则 Yarn ResourceManager 会重新调度 JobManager到其他机器;
- 如果 TaskManager 进程异常退出,JobManager 会收到消息并重新向 Yarn ResourceManager 申请资源,重新启动 TaskManager
-
客户端Client上传jar包和配置文件到HDFS集群上;
- 当启动一个Flink Yarn会话时,客户端首先会检查本次请求的资源是否足够;资源足够再上传。
- YARN Client上传完成jar包和配置文件以后,再向RM提交任务;
-
Client向YARN ResourceManager提交应用并申请资源;
- ResourceManager在NodeManager上启动容器,运行AppMaster,相当于JobManager进程。
-
ResourceManager分配Container资源并启动ApplicationMaster,然后AppMaster加载Flink的Jar包和配置构建环境,启动JobManager;
- JobManager和ApplicationMaster运行在同一个Container上;
- 一旦JobManager被成功启动,AppMaster就知道JobManager的地址(AM它自己所在的机器);
- 它就会为TaskManager生成一个新的Flink配置文件,此配置文件也被上传到HDFS上;
- 此外,AppMaster容器也提供了Flink的web服务接口;
- YARN所分配的所有端口都是临时端口,这允许用户并行执行多个Flink
-
ApplicationMaster向ResourceManager申请工作资源,NodeManager加载Flink的Jar包和配置
构建环境并启动TaskManager(多个)。 -
TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务;
6.flink on yarn执行应用模式
-
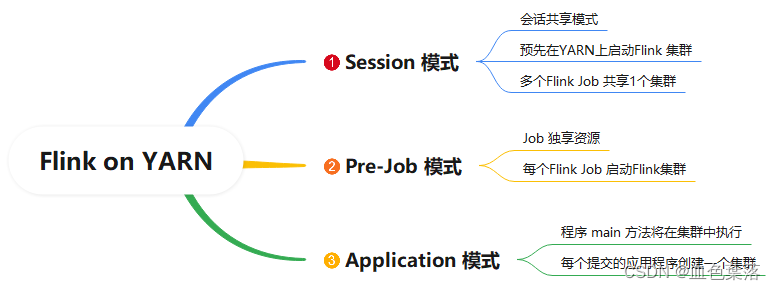
Session 模式,所有job共享集群资源
-
第一、Hadoop YARN 运行Flink 集群,开辟资源,使用:
yarn-session.sh- 在NodeManager上,启动容器Container运行
JobManager和TaskManagers
- 在NodeManager上,启动容器Container运行
-
第二、提交Flink Job执行,使用:
flink run
/export/server/flink-yarn/bin/flink run
-t yarn-session
-Dyarn.application.id=application_1652193583809_0001
/export/server/flink-yarn/examples/batch/WordCount.jar
–input hdfs://node1:8020/wordcount/input/words.txt -
Pre-job模式,采用Job分离模式,每个Flink Job运行,都会申请资源,运行属于自己的Flink 集群。
export HADOOP_CLASSPATH=hadoop classpath
/export/server/flink-yarn/bin/flink run
-t yarn-per-job -m yarn-cluster
-yjm 1024 -ytm 1024 -ys 1
/export/server/flink-yarn/examples/batch/WordCount.jar
–input hdfs://node1:8020/wordcount/input -
Application模式,
1、Session 模式:
所有作业Job共享1个集群资源,隔离性差,JM 负载瓶颈,每个Job中main 方法在客户端执行。
2、Per-Job 模式:
每个作业单独启动1个集群,隔离性好,JM 负载均衡,Job作业main 方法在客户端执行。
以上两种模式,main方法都是在客户端执行,需要获取 flink 运行时所需的依赖项,并生成 JobGraph,提交到集群的操作都会在实时平台所在的机器上执行,那么将会给服务器造成很大的压力。此外,提交任务的时候会把本地flink的所有jar包先上传到hdfs上相应的临时目录,带来大量的网络的开销,所以如果任务特别多的情况下,平台的吞吐量将会直线下降。
Application 模式下,用户程序的 main 方法将在
集群中运行,用户将程序逻辑和依赖打包进一个可执行的 jar 包里,集群的入口程序 (ApplicationClusterEntryPoint) 负责调用其中的 main 方法来生成 JobGraph。
export HADOOP_CLASSPATH=hadoop classpath
/export/server/flink-yarn/bin/flink run-application
-t yarn-application
-Djobmanager.memory.process.size=1024m
-Dtaskmanager.memory.process.size=1024m
-Dtaskmanager.numberOfTaskSlots=1
/export/server/flink-yarn/examples/batch/WordCount.jar
–input hdfs://node1:8020/wordcount/input
7.flink 实例
public static void main(String[] args) throws Exception {
// 1.执行环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2.数据源-source
DataStreamSource<String> inputDataStream = env.socketTextStream("node1", 9999);
// 3.数据转换-transformation
SingleOutputStreamOperator<Tuple2<String, Integer>> resultDataStream = inputDataStream
// 3-1. 分割单词
.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> out) throws Exception {
for (String word : line.trim().split("\\s+")) {
out.collect(word);
}
}
})
// 3-2. 转换二元组
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
return new Tuple2<>(word, 1);
}
})
// 3-3. 分组和组内求和
.keyBy(0).sum(1);
// 4.数据接收器-sink
resultDataStream.print();
// 5.触发执行-execute
env.execute();
}
- jar包运行参数设置
// TODO: 构建参数解析工具类实例对象
ParameterTool parameterTool = ParameterTool.fromArgs(args);
if(parameterTool.getNumberOfParameters() != 2){
System.out.println("Usage: WordCount --host <hostname> --port <port> .........");
System.exit(-1);
}
final String host = parameterTool.get("host") ; // 直接传递参数,获取值
final int port = parameterTool.getInt("port", 9999) ; // 如果没有参数,使用默认值
总结
flink简单概念
时光如水,人生逆旅矣。

















 7121
7121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









