



 在WindowsPowerShell中尝试启动MongoDB时遇到错误2,原因是安装路径被更改但注册表键值没有同步。解决方法是通过注册表编辑器修改HKEY_LOCAL_MACHINE下的ImagePath设置。
在WindowsPowerShell中尝试启动MongoDB时遇到错误2,原因是安装路径被更改但注册表键值没有同步。解决方法是通过注册表编辑器修改HKEY_LOCAL_MACHINE下的ImagePath设置。
MongoDB报错:net start MongoDB,发生系统错误 2,系统找不到指定的文件
在Windows PowerShell中使用net start MongoDB指令报错
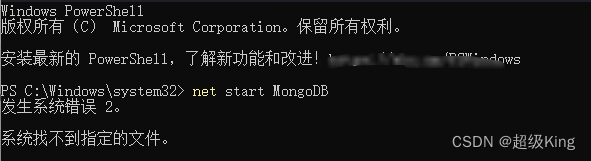
以上错误产生原因,可能是更改了Mongodb安装路径文件名导致,即使修改了环境变量中的配置,依然会报这个错
以上错误解决办法
1、使用指令Win + R 打开控制面板
Win+R
输入regedit 回车
regedit
2、根据这个HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\MongoDB路径,找到文件
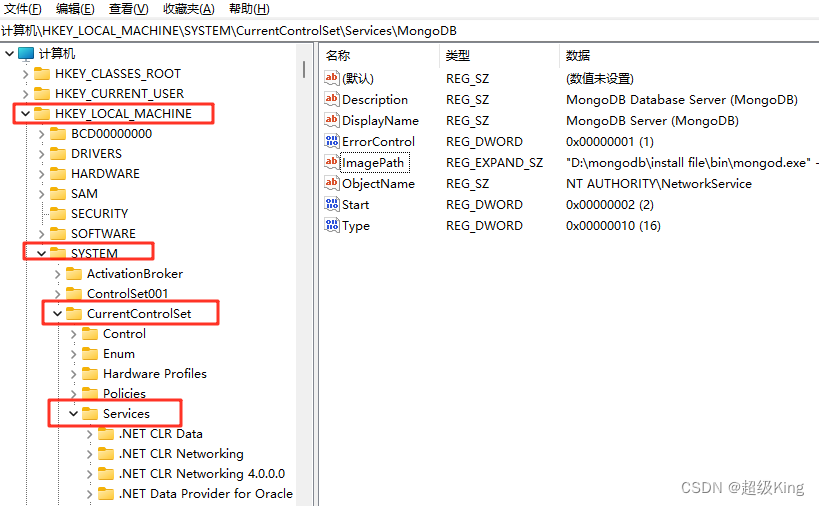
在MonogDB文件中找到ImagePath双击弹出
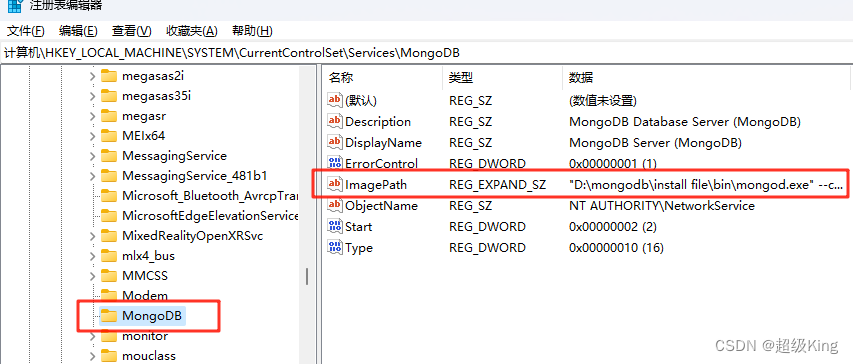
这是弹出的ImagePath

这是Mongodb安装文件路径,由于我更改了安装文件路径名,但是ImagePath中的路径名并没有自动更改,还是原来的文件名,修改ImagePath数值数据中的路径名和MongoDB安装路径名即可。






















 到【灌水乐园】发言
到【灌水乐园】发言









