



 本文详细介绍在CentOS 7系统上安装Spark 2.1.1的步骤。首先要安装Spark依赖的Scala并配置环境变量,接着下载和解压缩Spark,然后进行Spark相关配置,包括环境变量和conf目录下文件的配置,最后启动Spark Shell命令行窗口。
本文详细介绍在CentOS 7系统上安装Spark 2.1.1的步骤。首先要安装Spark依赖的Scala并配置环境变量,接着下载和解压缩Spark,然后进行Spark相关配置,包括环境变量和conf目录下文件的配置,最后启动Spark Shell命令行窗口。
Linux安装Spark集CentOS7+Spark2.1.1
1 安装Spark依赖的Scala
Scala的下载和解压缩可以参考下面博文的对应章节,步骤和方法一模一样:http://blog.youkuaiyun.com/pucao_cug/article/details/72353701
1.2 为Scala配置环境变量
编辑/etc/profile这个文件,在文件中增加一行配置:
export SCALA_HOME=/opt/scala/scala-2.12.2
在该文件的PATH变量中增加下面的内容:添加完成后,我的/etc/profile的配置如下:
export JAVA_HOME=/opt/java/jdk1.8.0_121
export SCALA_HOME=/opt/scala/scala-2.12.2
export CLASS_PATH=.:
J
A
V
A
H
O
M
E
/
l
i
b
:
{JAVA_HOME}/lib:
JAVAHOME/lib:CLASS_PATH
export PATH=.?{JAVA_HOME}/bin:
S
C
A
L
A
H
O
M
E
/
b
i
n
:
{SCALA_HOME}/bin:
SCALAHOME/bin:PATH
环境变量配置完成后,执行下面的命令:
source /etc/profile
1.3 验证Scala
执行命令:
scala -version
如图:

2 下载和解压缩Spark
下载和解压缩Spark可以参考该博文的下载和解压缩章节,步骤和方法一模一样:
http://blog.youkuaiyun.com/pucao_cug/article/details/72353701
3 Spark相关的配置
说明:因为我们搭建的是基于hadoop集群的Spark集群,所以每个hadoop节点上我都安装了Spark,都需要按照下面的步骤做配置,启动的话只需要在Spark集群的Master机器上启动即可,我这里是在hserver1上启动。
3.1 配置环境变量
编辑/etc/profile文件,增加
export SPARK_HOME=/opt/spark/spark-2.1.1-bin-hadoop2.7
在该文件的PATH变量中增加下面的内容:
${SPARK_HOME}/bin
修改完成后,我的/etc/profile文件内容是:
export JAVA_HOME=/opt/java/jdk1.8.0_121
export ZK_HOME=/opt/zookeeper/zookeeper-3.4.10
export SCALA_HOME=/opt/scala/scala-2.12.2
export SPARK_HOME=/opt/spark/spark-2.1.1-bin-hadoop2.7
export CLASS_PATH=.:
J
A
V
A
H
O
M
E
/
l
i
b
:
{JAVA_HOME}/lib:
JAVAHOME/lib:CLASS_PATH
export PATH=.:
J
A
V
A
H
O
M
E
/
b
i
n
:
{JAVA_HOME}/bin:
JAVAHOME/bin:{SPARK_HOME}/bin:
Z
K
H
O
M
E
/
b
i
n
:
{ZK_HOME}/bin:
ZKHOME/bin:{SCALA_HOME}/bin:$PATH
如图:
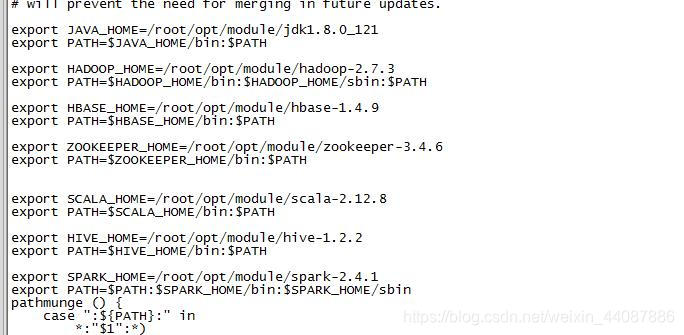
编辑完成后,执行命令:
source /etc/profile
3.2 配置conf目录下的文件
对/opt/spark/spark-2.1.1-bin-hadoop2.7/conf目录下的文件进行配置。
3.2.1 新建spark-env.h文件
执行命令,进入到/opt/module/spark-2.4.1/conf目录内:
cd /opt/module/spark-2.4.1/conf
以spark为我们创建好的模板创建一个spark-env.h文件,命令是:
cp spark-env.sh.template spark-env.sh
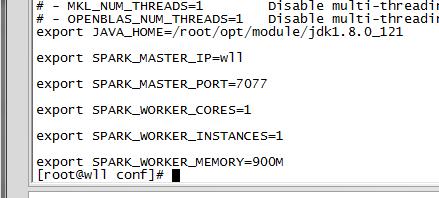
编辑spark-env.h文件,在里面加入配置(具体路径以自己的为准):
export SCALA_HOME=/opt/scala/scala-2.12.2
export JAVA_HOME=/opt/java/jdk1.8.0_121
export SPARK_HOME=/opt/spark/spark-2.1.1-bin-hadoop2.7
export SPARK_MASTER_IP=hserver1
export SPARK_EXECUTOR_MEMORY=1G
如图:
3.2.2 新建slaves文件
执行命令,进入到/opt/module/spark-2.4.1/conf目录内:
cd /opt/module/spark-2.4.1/conf
以spark为我们创建好的模板创建一个slaves文件,命令是:
cp slaves.template slaves
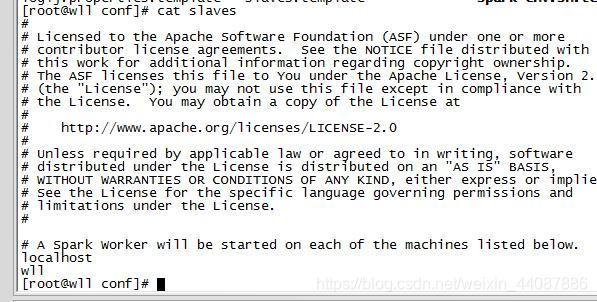
编辑slaves文件,里面的内容为:
localhost
如图:
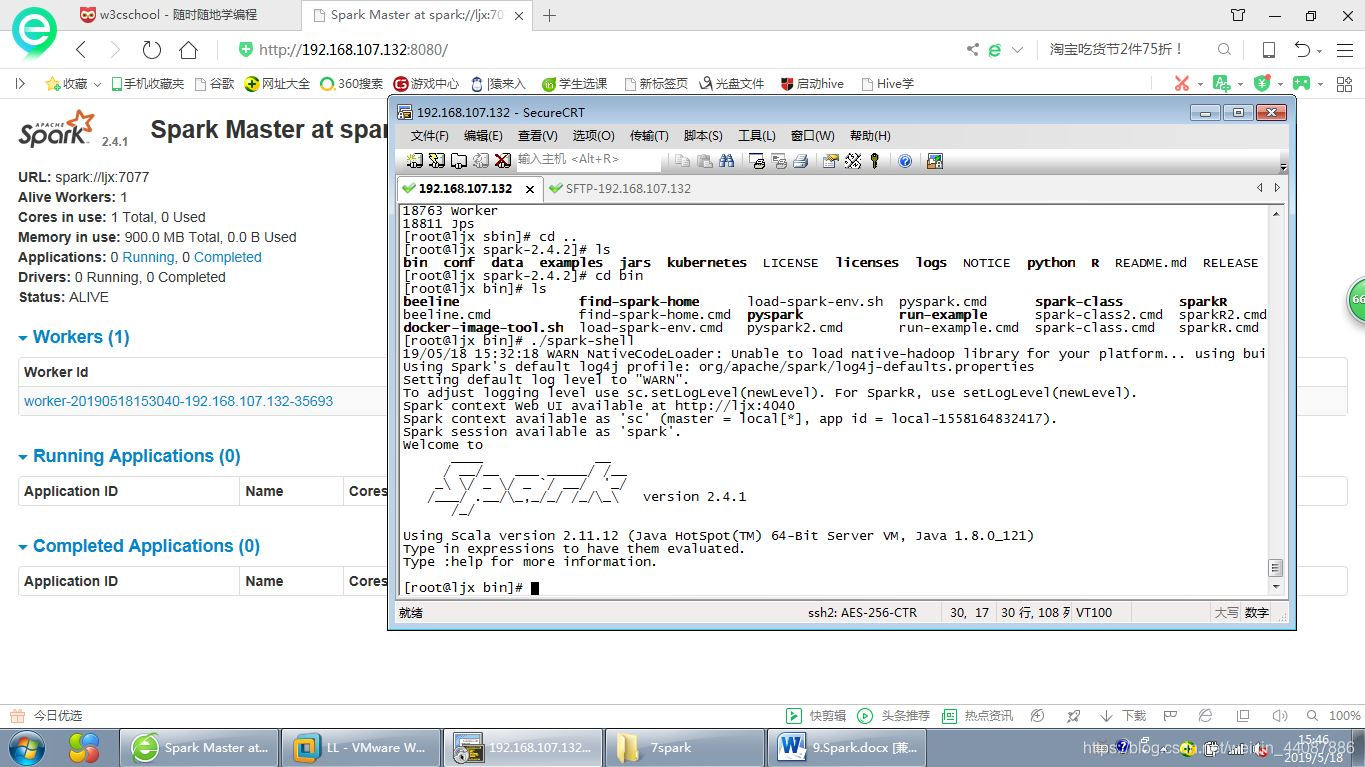
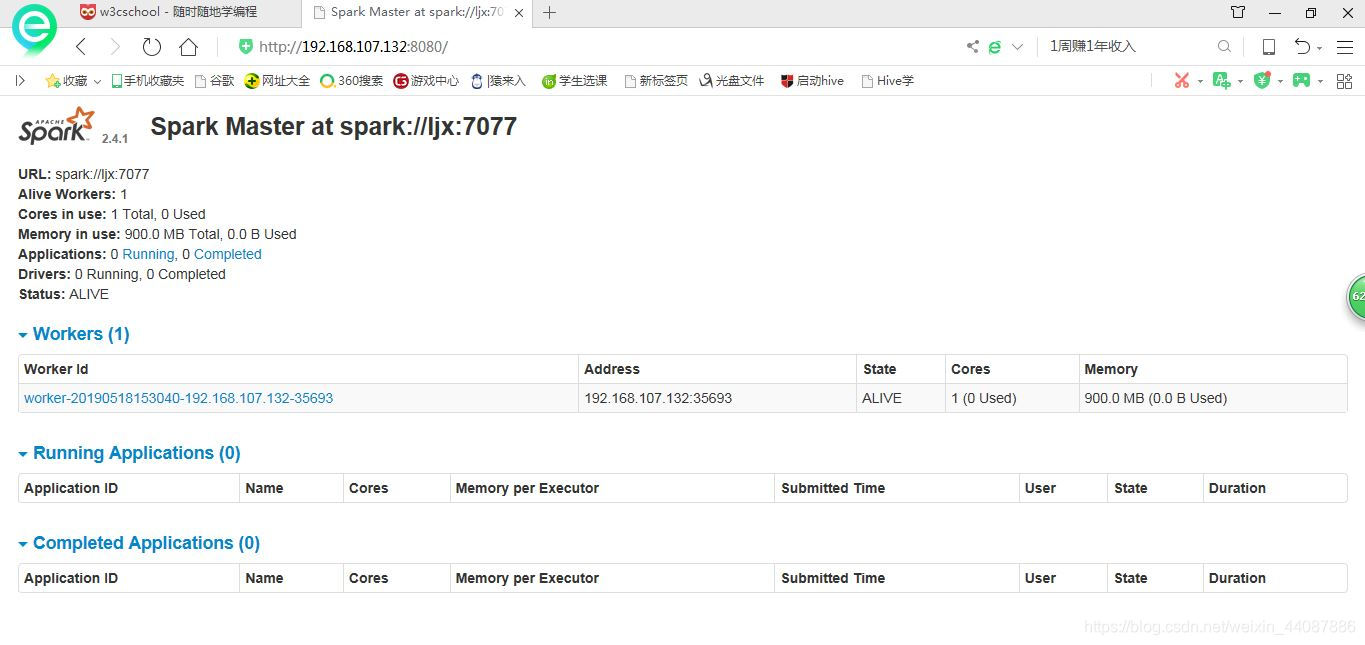
4 启动Spark Shell命令行窗口
进入到主目录,也就是执行下面的命令:
cd /opt/spark/spark-2.1.1-bin-hadoop2.7
执行命令,启动脚本:
./bin/spark-shell
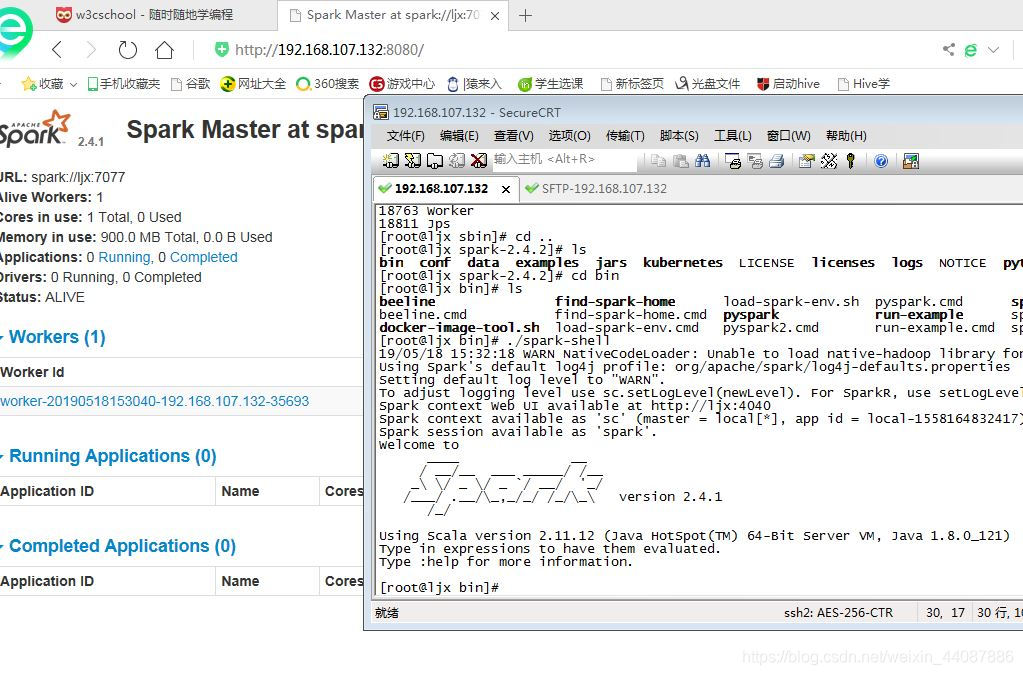

















 1436
1436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









