




- 作者:Tero Karras, Timo Aila, Samuli Laine, Jaakko Lehtinen
- 单位:NVIDIA
- 发表期刊:ICLR 2018
一、前期知识储备:
1.1DCGAN:
1.1.1模型结构:
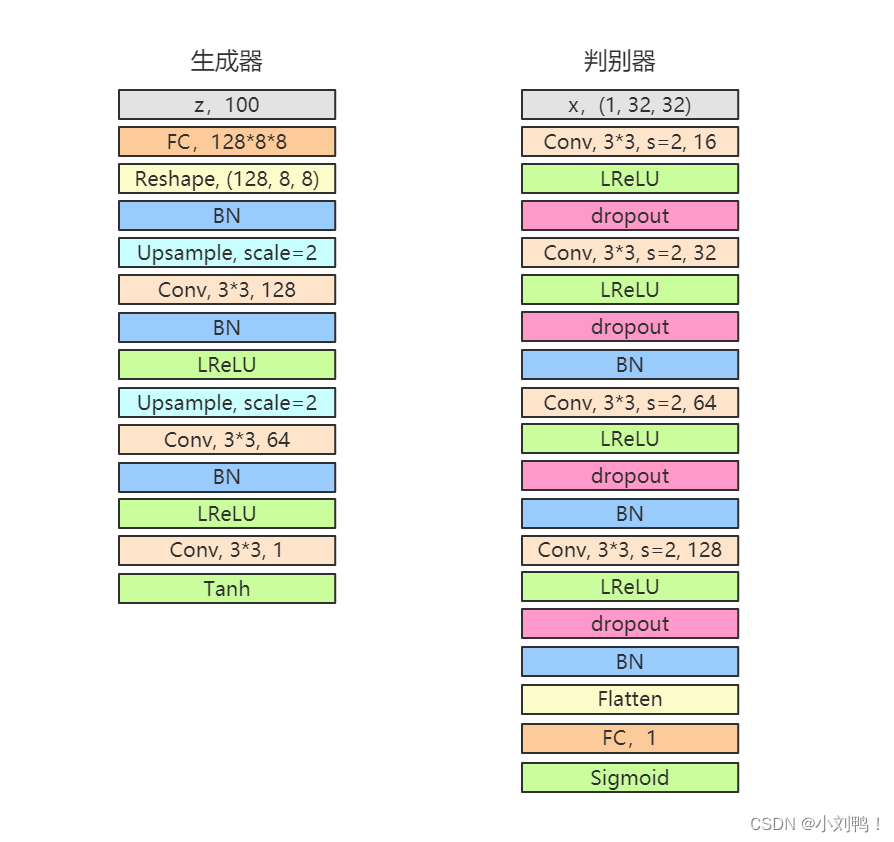
1.1.2项目地址:
git clone https://github.com/eriklindernoren/PyTorch-GAN.git
下载后运行代码会自动下载MNIST数据集
IDE推荐使用 PyCharm 进行开发
1.2 Improved GAN
1.2.1 Minibatch discrimination 小批量判别
- 1.该策略提出的出发点:
针对GAN网络的收敛性问题,GAN网络的目的是在高维非凸的参数空间中,找到一个价值函数的纳什均衡点使用梯度下降来优化GAN网络,只能得到较低的损失,不能找到真正的纳什均衡例如,一个网络修改x来最小化xy,另一个网络修改y来最小化-xy,使用梯度下降进行优化,结果进入一个稳定的轨道中,并不会收敛到(0,0)点作者引入了一些方法,希望提高网络的收敛性
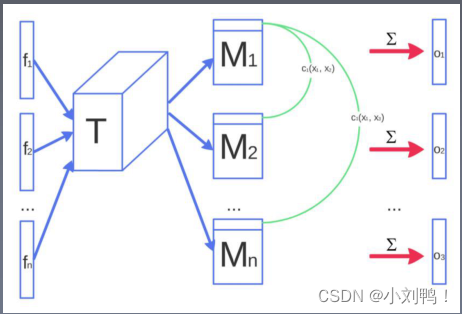
1.2.2 Minibatch discrimination
对于DCGAN没有一个机制保证生成器需要生成不一样的数据,当模式崩溃即将发生时,判别器中许多相似点的梯度会指向一个相近的方向。计算判别器中某一层特征中,同一个batch各样本特征间的差异,来作为下一层的额外输入。这种方法能够快速的生成视觉上能够感知出明显差异的样本。
- 不需要任何参数或超参数
- 在判别器中,对于每个channel的每个像素点分别计算batch内的标准差并取平均,得到一个代表整体标准差的标量
- 复制这个标准差把它扩展为一个feature map,concat到现有维度上
- 加到判别器的末尾处效果最好
- 其他的一些增加生成多样性的方法,可以比这个方法效果更好,或者与此方法正交
1.2.4 图像质量评价Inception Score:
- 1.问题提出的出发点:
人工评价比如之前的是用Amazon Mechanical Turk众包平台进行人工标注,将真实图片和生成图像掺杂在一起,标注者需要逐个指出给定图像是真实的还是生成的当给标注者提供标注反馈时,结果会发生
巨大变化;通过学习这些反馈,标注者能够更好地指出生成图像中的缺陷,从而更倾向于把图像标记为生成的。 - 2.本文提出的方法:
提出了一种自动评估样本的方法,这个方法评估的结果与人类的评估高度相关,使用Inception模型,以生成图片x为输入,以x的推断类标签概率p(y|x)为输出,单个样本的输出分布应该为低熵,即高预测置信度,好样本应该包含明确有意义的目标物体,所有样本的输出整体分布应该为高熵,也就是说,所有的x应该尽量分属于不同的类别,而不是属于同一类别,因此,Inception score定义为
exp ( E x K L ( p ( y ∣ x ) ∥ p ( y ) ) ) exp ( 1 N ∑ i = 1 N D K L ( p ( y ∣ x ( i ) ) ∥ p ^ ( y ) ) ) \begin{aligned} &\exp \left(E_x K L(p(y \mid x) \| p(y))\right) \\ &\exp \left(\frac{1}{N} \sum_{i=1}^N D_{K L}\left(p\left(y \mid \mathbf{x}^{(i)}\right) \| \hat{p}(y)\right)\right) \end{aligned} exp(ExKL(p(y∣x)∥p(y)))exp(N1i=1∑NDKL(p(y∣x(i))∥p^(y)))
二、论文摘要:
核心要点
- 使用渐进的方式来训练生成器和判别器:先从生成低分辨率图像开始,然后不断增加模型层数来
提升生成图像的细节 - 这个方法能加速模型训练并大幅提升训练稳定性,生成前所未有的的高质量图像(1024*1024)
- 提出了一种简单的方法来增加生成图像的多样性
- 介绍了几种限制生成器和判别器之间不健康竞争的技巧
- 提出了一种评价GAN生成效果的新方法,包括对生成质量和多样性的衡量
- 构建了一个CELEBA数据集的高清版本
三、研究背景
3.1生成式模型的类别:
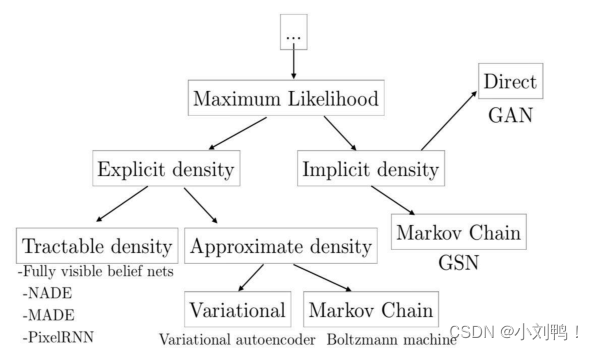
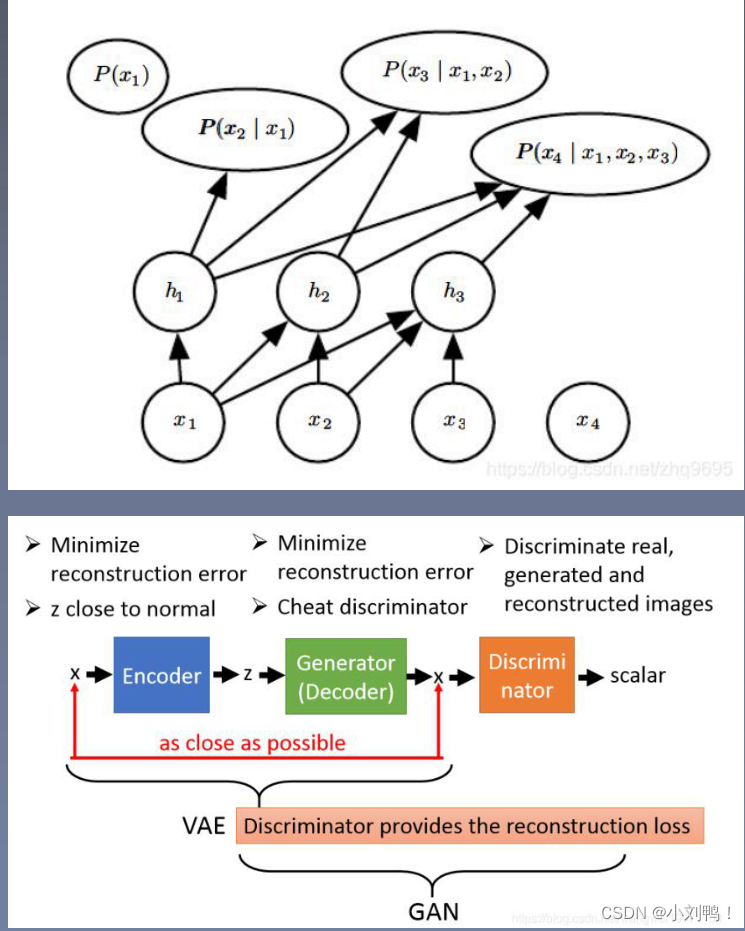
3.1.1显性密度模型:
- 易解显性模型:定义一个方便计算的密度分布,主要的模型是Fully visible belief nets,也被称为Auto-Regressive Network
- 近似显性模型:可以定任意的密度分布,使用近似方法来求解
3.1.2 隐性密度模型:
- GAN
3.2神经自回归网络(PixelRNN/CNN)
- 通过链式法则把联合概率分布分解为条件概率分布的乘积,使用神经网络来参数化每个p
- PixelRNN逐像素生成,效率很低,PixelCNN效果不如PixelRNN
3.3VAE-GAN
编码器:使P(z|x)逼近分布P(z),比如标准正态分布,同时最小化生成器(解码器)和输入x的差距
解码器:最小化输出和输入x的差距,同时要骗过判别器
判别器:给真实样本高分,给重建样本和生成样本低分
3.4GAN损失函数
3.4.1 F-divergence
- JS散度(交叉熵)
∫ x p g ( x ) f ( p data ( x ) p g ( x ) ) d x \begin{aligned} &\int_x p_g(x) f\left(\frac{p_{\text {data }}(x)}{p_g(x)}\right) d x \\ \end{aligned} ∫xpg(x)f(pg(x)pdata (x))dx
LSGAN(MSE)损失函数
E x ∼ p data [ log D ( x ) ] + E z ∼ p z [ log ( 1 − D ( G ( z ) ) ] 1 2 E x ∼ p data ( x ) [ D ( x ) − a ] 2 + 1 2 E z ∼ p z ( z ) [ D ( G ( z ) ) − b ] 2 \begin{aligned} &\mathbb{E}_{x \sim p_{\text {data }}}[\log D(x)]+\mathbb{E}_{z \sim p_z}[\log (1-D(G(z))] \\ &\frac{1}{2} \mathrm{E}_{x \sim p_{\text {data }}(x)}[D(x)-a]^2+\frac{1}{2} \mathrm{E}_{z \sim p_z(z)}[D(G(z))-b]^2 \\ \end{aligned} Ex∼p
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 6577
6577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









