




 文章讨论了机器学习中的关键概念,包括模型的泛化能力、误差类型(如过拟合和欠拟合)、方差与偏差的分析,以及性能度量标准如均方误差、错误率、精度、F1分数和ROC曲线。此外,还介绍了如何通过假设检验来比较不同学习器的性能。
文章讨论了机器学习中的关键概念,包括模型的泛化能力、误差类型(如过拟合和欠拟合)、方差与偏差的分析,以及性能度量标准如均方误差、错误率、精度、F1分数和ROC曲线。此外,还介绍了如何通过假设检验来比较不同学习器的性能。
1. 经验误差与过拟合
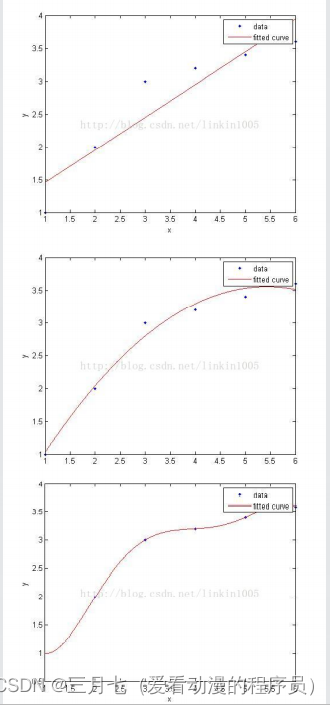
第三张图建立的模型,在训练集中通过x可以很好的预测y,然而我们不能预期该模型能够很好的预
测集外的数据,换句话说,这个模型没有很好的泛化能力。
第一张图建立了一个线性模型,但是该模型并没有精确地捕捉到训练集数据的结构,我们称具有第
一张图较大的偏倚(bias),也称欠拟合。
第三张图通过5次多项式函数很好的对样本进行了拟合,然而,如果将建立的模型进行泛化,并不
能很好的对训练集之外的数据进行预测,也称过拟合。
机器学习的主要挑战在于在未见过的数据输入上表现良好,这个能力称为泛化能力
(generalization)。
误差:学习器实际预测输出与样本真实输出的差异。
训练集误差:训练误差
训练集的补集:泛化误差
测试集误差:测试误差
我们希望得到泛化误差小的学习器。
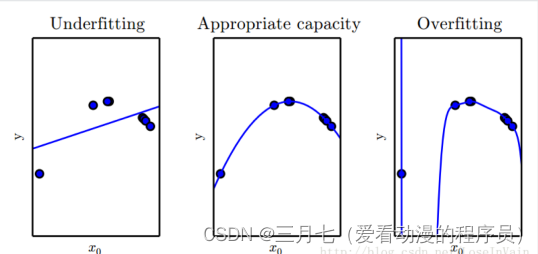
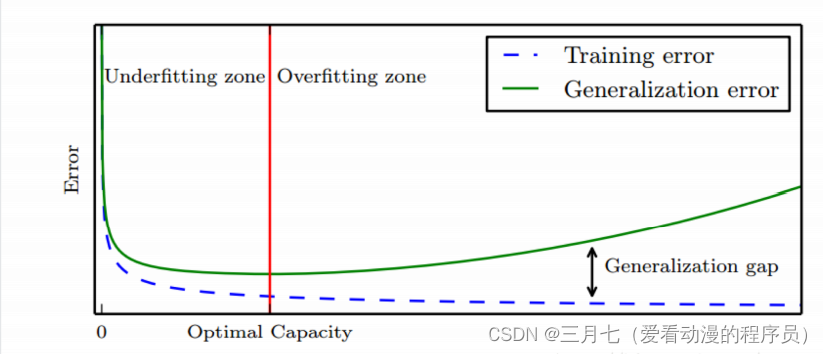
过拟合:训练过度使泛化能力下降。
欠拟合:未能学好训练样本的普遍规律。
过拟合是机器学习的关键障碍,且不可避免。
模型误差包含了数据误差,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1119
1119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











