




Original post: https://forum.taichi-lang.cn/t/pcisph/2092/3
介绍下背景:SPH中粒子半径和支撑半径是有关系的,一般取粒子半径的4倍为支撑半径。其依据就是下面所谓的完美采样。由于SPH是靠粒子携带数据,再通过粒子平均得到场数据的。但粒子有时多有时少,就会出现欠采样和过采样的问题。而过采样或欠采样,总要有个衡量的标杆吧?完美采样说的就是认为采样充足的时候,粒子该是什么样的一个密度。
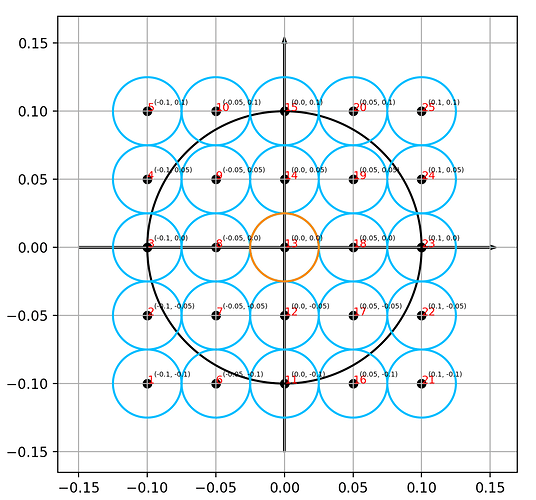
PS:背景中画出的网格(实际上SPH本质上不需要网格,但用网格加速邻域搜索的时候也可以用网格),可以看成是MPM等方法借助的背景网格的一个间距,取粒子直径大小。
参照SPLISHSPLASH那个库,又学习了一下它的代码,于是发现所谓perfect sampling是这样的:
(画出来结果和mzhang 助教 所说一致)
蓝色小圈代表邻居粒子
橙色小圈是当前粒子
黑色大圈是核半径
这里取粒子半径为0.025
核半径是粒子半径的四倍
只要比较各个蓝色小圆的中心点是不是在黑色大圈里面就行了
于是这就是perfect sampling(SplishSPlasH的)
画图的代码如下
# https://forum.taichi-lang.cn/t/pcisph/2092/3
import numpy as np
import math
import matplotlib.pyplot as plt
def circle(x,y,r,color='k',count=1000):
xarr=[]
yarr=[]
for i in range(count):
j = float(i)/count * 2 * np.pi
xa 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









