




 本文详细介绍了如何使用SQL的UNION和UNION ALL语句来合并多个查询结果。通过具体的例子,展示了如何查询特定用户名的数据,并将结果进行合并。同时,对比了UNION与UNION ALL的区别,即是否去除重复数据。
本文详细介绍了如何使用SQL的UNION和UNION ALL语句来合并多个查询结果。通过具体的例子,展示了如何查询特定用户名的数据,并将结果进行合并。同时,对比了UNION与UNION ALL的区别,即是否去除重复数据。
user表结构如下所示:
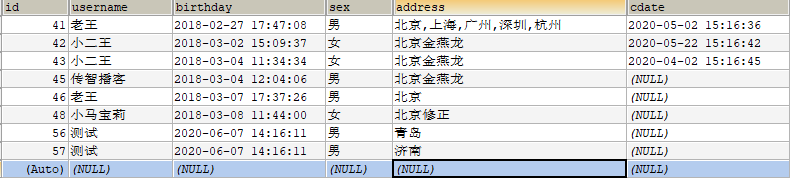
现在要查询username = '小二王’和username = '测试’的数据,并把两次查询的结果拼接到一起,sql语句:
SELECT * FROM `user` WHERE username = '小二王'
UNION ALL
SELECT * FROM `user` WHERE username = '测试'
查询结果如下所示:

要注意查询的列必须是相同的,如果两次查询的某一条结果是相同,也不会合并,如果想要合并相同的数据,使用UNION连接
例:
sql语句:
SELECT username,sex FROM `user` WHERE address = '青岛'
UNION ALL
SELECT username,sex FROM `user` WHERE address = '济南';
结果如下所示:
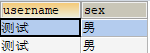
两条相同的结果并没有合并


















 311
311



 到【灌水乐园】发言
到【灌水乐园】发言







