




 该项目使用Python爬虫技术爬取游戏网站的皮肤图片和信息,通过处理数据生成词云图。采用了pyecharts、MongoDB和Python第三方库。目标是检验Python学习成果,爬取的图片被保存,信息用于制作词云图,展示了数据的可视化分析。
该项目使用Python爬虫技术爬取游戏网站的皮肤图片和信息,通过处理数据生成词云图。采用了pyecharts、MongoDB和Python第三方库。目标是检验Python学习成果,爬取的图片被保存,信息用于制作词云图,展示了数据的可视化分析。
一、项目简介
1.1 本项目博客地址:
1.2 项目完成的功能与特色
功能:爬取目标游戏网站的皮肤图片及信息并用爬取的信息生成词云图。
特色:将爬取的信息做简单的处理,并将爬取的图片直接保存在文件夹中。
1.3项目采取的技术线
使用软件:Visual Studio Code、 PyCharm
采用技术:pyecharts、MongoDB、python第三方库
1.4项目借鉴的源代码github或博客地址
https://www.cnblogs.com/su-sir/p/12051564.html
https://www.jianshu.com/p/ca95c2a7233c
https://blog.youkuaiyun.com/luoz_java/article/details/92741358
1.5团队任务分配表
| 成员 | 任务 |
|---|---|
| 小锦 | 全部 |
二、项目的需求分析
2.1项目背景
为了检验自己学习Python一学期的成果。
2.2项目目标
希望通过
3.3项目需求
鉴于当代社会娱乐产业的发达,一个游戏里涵盖了许许多多的内容,也衍生出许许多多不同的产业链和用户需求。通过这个爬虫,将获取到的图片保存用来挑选好看的皮肤以及精美CG。
三、项目功能架构图、主要功能流程图
3.1项目功能架构图:
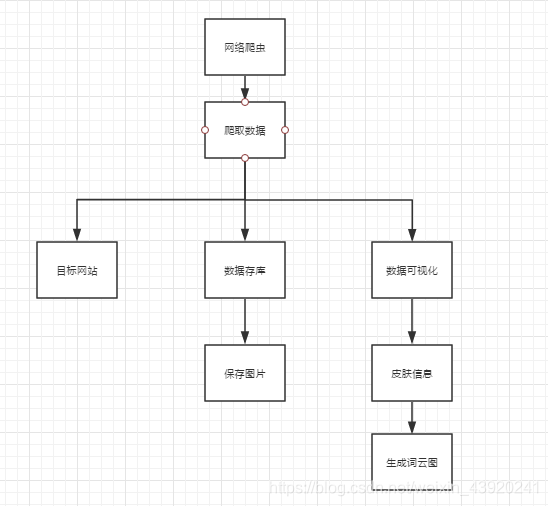
3.2主要功能流程图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1161
1161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









