






 本文提出了一种名为TAM的时间自适应模块,用于视频识别任务,以适应不同视频中的时间变化。TAM包含局部和全局分支,分别处理短期信息和长期时间依赖性。通过在2D CNN中集成TAM,构建了高效的视频识别架构TANet,该架构在Kinetics-400和Something-Something数据集上展现出优越的性能。
本文提出了一种名为TAM的时间自适应模块,用于视频识别任务,以适应不同视频中的时间变化。TAM包含局部和全局分支,分别处理短期信息和长期时间依赖性。通过在2D CNN中集成TAM,构建了高效的视频识别架构TANet,该架构在Kinetics-400和Something-Something数据集上展现出优越的性能。
原文链接:https://arxiv.org/pdf/2005.06803v1.pdf
1.Abstract
时间建模是捕捉视频时空结构进行动作识别的关键。由于摄像机运动、速度变化、不同活动等因素的影响,视频数据在时间维度上具有极其复杂的动态特性。为了有效地捕捉这种不同的运动模式,本文提出了一种新的时间自适应模块(TAM)来生成基于其自身特征映射的视频特定kernel。TAM提出了一种独特的两级自适应建模方案,将动态核解耦为一个位置不敏感的重要映射(importance map)和一个位置不变的聚集权重(aggregation weight)。importance map是在局部时间窗口中学习的,以捕获短期信息,而aggregation weight是从关注长期结构的全局视图中生成的。TAM是一个原则性的模块,可以集成到2D cnn中,以非常小的额外计算成本产生强大的视频架构(TANet)。在Kinetics-400上进行的大量实验表明,由于TAM的自适应建模策略,其性能始终优于其他时间建模方法。在something-something数据集上,TANet比以前最先进的方法获得了更好的性能。该代码将很快在https://github.com/liu-zhy/TANet上提供。
1. 引言
深度学习为图像领域的各种识别任务带来了很大的进展,如图像分类[17,9],物体检测[22],实例分割[8]。成功的关键是设计灵活高效的架构,能够从大规模图像数据集中学习强大的视觉表示[2]。然而,深度学习在视频理解方面的研究进展相对较慢,部分原因是视频数据的高度复杂性。视频理解的核心技术问题是设计一种有效的时域模块,既能灵活地捕捉复杂的时域结构,同时还具有低计算消耗以有效地处理高维视频数据。
3D 卷积神经网络 已成为视频建模的主流架构。 3D 卷积是对 2D CNN的自然扩展,并为视频识别提供了可学习的算子。然而,这种简单的扩展缺乏对视频数据时间属性的具体考虑,并且可能会导致高计算成本。因此,最近的方法旨在通过将轻量级时间模块与 2D CNN 相结合以提高效率(例如,TSN、TSM)或设计专用时间模块以更好地捕获时间关系,从而从两个不同方面改进 3D CNN (例如,Non-Local网络、ARTNet、STM)。然而,如何设计一个高效、灵活的时间模块仍然是视频识别中一个未解决的问题。因此,本文的目标是沿着这个方向推进当前的视频架构。
在本文中,作者专注于设计一个自适应模块,以更灵活的方式捕获时间信息。作者观察到由于相机运动和各种速度等因素,视频数据在时间维度上具有极其复杂的动态。因此,通过简单地使用固定数量的视频无关卷积核,3D 卷积可能缺乏足够的表达能力来描述运动多样性。为了处理视频中如此复杂的时间变化,作者认为每个视频有自适应的时间核是有效的,并且可能是描述运动模式所必需的。为此,如图 1 所示,提出了一种两级自适应建模方案,将这个视频特定的时序核参数被分解成位置敏感和位置无关的。这种独特的设计允许位置敏感的专注于增强来自局部视图的判别时间信息,并使位置无关的能够捕获由输入视频序列的全局视角引导的时间依赖性。
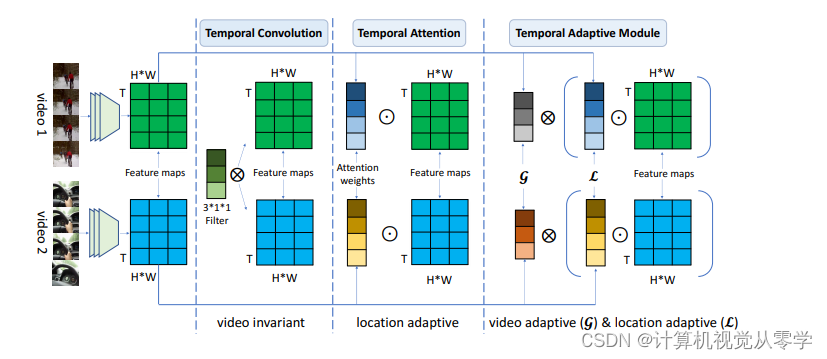
图 1:时间模块比较:标准时间卷积在视频之间共享权重,并且由于视频的多样性,可能缺乏处理视频变化的灵活性。时间注意力通过自适应地为判别特征分配高重要性权重来学习位置敏感权重,并且可能忽略长期时间依赖性。本文提出的时间自适应模块(TAM)通过学习用于位置自适应增强的局部重要性权重和用于视频自适应聚合的全局重要性权重,提出了一种两级自适应方案。表示注意力操作,
表示卷积操作。
具体来说,时间自适
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









