






 本文探讨了在弱监督视频异常检测中被忽视的视频分类的重要性。通过使用BERT进行视频分类,研究发现这种方法显著提高了异常检测性能,尤其是在XD-Violence数据集上,平均精度提高了3.26%。文章详细介绍了BERT在训练和测试流程中的应用,以及与RTFM的结合使用,展示了视频分类在异常检测领域的潜力。
本文探讨了在弱监督视频异常检测中被忽视的视频分类的重要性。通过使用BERT进行视频分类,研究发现这种方法显著提高了异常检测性能,尤其是在XD-Violence数据集上,平均精度提高了3.26%。文章详细介绍了BERT在训练和测试流程中的应用,以及与RTFM的结合使用,展示了视频分类在异常检测领域的潜力。
目录
一、前言知识
基于BERT的时序建模
来自:Late Temporal Modeling in 3D CNN Architectures with BERT for Action Recognition 二、论文阅读


二、论文阅读
【摘要】
当前的弱监督视频异常检测算法大多使用多实例学习(MIL)或其变种。几乎所有最近的方法都侧重于如何选择正确的训练片段以提高性能。他们忽视或没有意识到视频分类在提高异常检测性能方面的作用。在本文中,我们明确研究了使用BERT或LSTM进行视频分类监督的能力。使用此BERT或LSTM,可以将视频所有片段的CNN特征聚合为可用于视频分类的单个特征。这种简单而强大的视频分类监管,结合到MIL框架中,在所有三个主要的视频异常检测数据集上带来了非凡的性能改进。特别是,它将XD-Violence的平均精度(mAP)从SOTA 78.84%提高到新的82.10%。该代码公开于 https:// github.com/wjtan99/BERT_Anomaly_Video_ Classification.
1.引言
在几乎所有的后续研究中,关于如何选择最佳质量的片段来训练模型,都提出了不同的方法。有些人选择多个片段而不是一段视频中的一个片段[22],另一些人则选择一系列连续片段[14],[7]。其中一些使用片段分类分数来选择片段,另一些使用包括特征量值在内的其他度量[22]。一些人使用GCN来提高所选片段的质量[30]。
然而,几乎所有人都忽视或没有充分认识到视频分类的威力及其对异常检测性能的影响。在异常检测中,视频被分类为异常或正常视频。除了RTFM[22]、[14]和[29]之外,这种强大的信息被忽略了。在RTFM中,每个视频选择具有最大特征量值的前k个片段,并将其分类得分的平均值用作二进制交叉熵损失中的视频分类得分,尽管作者并没有这样称呼。
在[29]中,使用GCN近似地对视频分类建模,并使用视频分类BCE损失。与我们最相关的工作是[14]。当我们使用BERT[4],[9]研究显式视频分类时,我们发现他们使用transformer来建模具有BCE损失的视频分类。除了这种视频分类之外,transformer还用于改进CNN特征。他们提出了一种多序列学习(MSL),寻找连续片段以改进训练,这被称为他们的主要贡献。然而,在我们的工作中,我们发现BERT或transformer不一定同时完成视频分类和特征细化这两项任务。我们发现它无助于特征细化,因此我们只研究它在视频分类中的作用。通过这种简单的单一更改,无需MSL或RTFM,我们在UCFCrime[21]和ShanghaiTech[16]数据集上实现了卓越的性能。
我们进一步在RTFM之上使用BERT视频分类。我们结合了他们的BCE损失和我们提出的BERT-enabled BCE损失,并在XD-Violence数据集上实现了非凡的性能。基于这些结果,我们证明了视频分类监督在异常检测中的作用。它可以单独工作或结合RTFM等其他技术来提高异常检测的性能。
我们的贡献总结如下:
•我们明确研究了视频分类监督在弱监督视频异常检测中的作用。这种视频分类是通过一个BERT在片段CNN特征上实现的。我们发现BERT只应用于视频分类,而不应用于特征细化。不应将两种现有思想(BERT和MIL)的结合作为我们的主要贡献。相反,我们的关键贡献是我们发现了一个事实,即视频分类在异常检测上的有效性以前被忽视了,现在这项工作填补了这一空白。作为消融研究,我们实现了一个更简单的基于LSTM的视频分类器。尽管其复杂度低得多,但其性能与BERT几乎相同。
•该方案有两种推理模式。第二种在线模式提供了一个非常有吸引力的低复杂度选项,尽管它只能从视频分类监督中获得部分性能改进。
•我们在UCF-Crime和ShanghaiTech数据集的标准MIL框架中单独研究了该算法。我们测试RGB、Flow或RGB+Flow模式。这种在异常检测中引入视频分类的简单方法在每个模态上都带来了卓越的性能改进。在RGB+Flow模式下,我们实现了最佳的ROC-AUC性能,超过SOTA 1.5%。
•我们在UCF-Crime和XD-Violence数据集的RTFM[22]之上研究了该算法。我们只测试RGB模式。虽然我们的算法在UCF-Crime数据集上仅实现了微小的ROC-AUC性能改进,但在XD-Violence数据集上实现了近3.51%的AP性能改进。这一改进表明,我们提出的显式视频分类可以与许多其他视频异常检测算法相结合,其中不使用显式视频分类器。
2.相关工作
通过利用可用的视频级注释,弱监督异常检测已显示出比自监督方法显著提高的性能。这些注释仅为视频提供异常或正常的二进制标记。Sultani等人[21]提出了仅使用视频级别标签的MIL框架,并引入了大规模异常检测数据集UCF-Crime。这项工作启发了许多后续研究[30],[17],[26],[28],[27],[7],[22],[14]。
然而,在基于MIL的方法中,异常视频标签不容易被有效地使用。通常,分类分数用于判断代码片段是异常还是正常。这个分数在阳性包中很嘈杂,正常片段可能被错误地视为异常视频中的顶部异常事件。为了解决这个问题,Zhong等人[30]将这个问题视为有噪声标签问题下的二进制分类,并使用图卷积神经(GCN)网络来清除标签噪声。在[7]中,提出了一种多实例自训练框架(MIST),以利用多实例伪标签生成器和自引导注意力增强特征编码器有效地细化任务特定的区分表示。在[28]中,提出了一种弱监督的时空异常检测来定位包含异常事件的时空管。在[28]中,研究了因果时间线索和特征辨别。在[17]中,使用高阶上下文编码模型来编码时间变化以及用于弱监督异常检测的高级语义信息。
在RTFM[22]中,稳健的时间特征量(RTFM)用于从异常视频和正常视频中选择最可靠的异常片段。它们通过时间特征排序损失来统一表示学习和异常分数学习,从而能够更好地分离正常和异常特征表示,与以前的MIL方法相比,改进了对弱标签的探索。在[14]中,使用了多序列学习(MSL)。MSL使用多个实例的序列作为优化单元,而不是MIL中的单个实例。此外,还使用了一个transformer来细化代码段特征。视频分类与transformer分类令牌一起使用。
在[29]中,视频和音频信号都用于检测视频和音频中的异常。他们使用GCN来建模长期和局部依赖关系。同时,他们发布了迄今为止最大的视频异常检测数据集XD-Violence数据集。
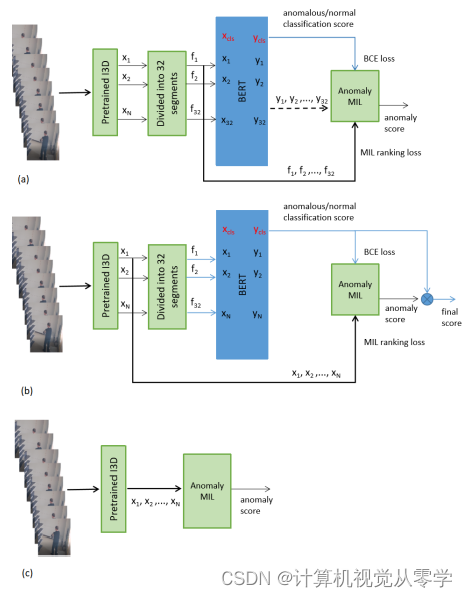
图1.我们使用BERT视频分类进行异常检测的框图,(a)训练,(b)使用视频分类进行测试,(c)不使用视频分类的测试。
3.提出的方法
我们建议使用BERT作为视频分类器,因为它具有聚合空间和时间注意力信息的非凡能力。训练和测试流程图如图1所示。下面将给出更多细节。
让我们先定义一些可能令人困惑的术语。视频分类是指将每个视频分类为正常或异常。snippet被定义为固定长度的视频帧序列,在本文中,视频帧序列长度为16。Segment被定义成片段序列。在这项工作中,我们遵循先前的工作,将每个训练和验证视频分割为长度相等的32个Segment。在测试视频中,可以使用片段或片段。
3.1 BERT简介
Transformer首次出现在2017年的一篇题为“Attention is all you need”的论文中[24]。它是一个非常成功的自然语言处理(NLP)模型,近年来成为突破性创新之一。从那时起,transformer已经扩展到机器学习的几乎每个领域,包括图像分类[5]、对象检测[1]和视频理解[8]等等。Transformer关注输入数据序列中的每个元素,并提取整个数据集的轨迹。
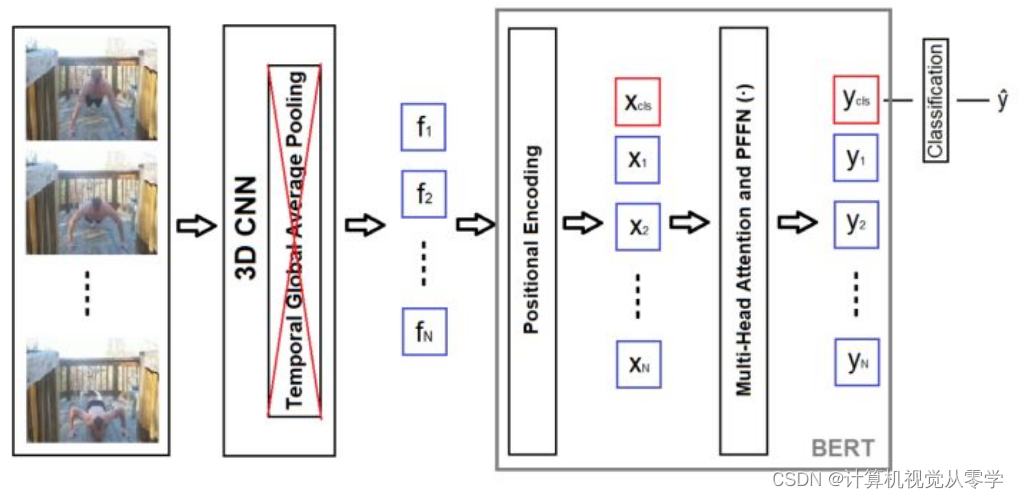
继transformer(一种单向模型)的成功之后,transformer(BERT)[4]的双向编码器表示是一种双向自关注模型,在许多下游NLP任务中也取得了巨大成功。双向属性使BERT能够从两个方向融合上下文信息。此外,BERT引入了具有挑战性的无监督预训练任务,这导致了许多任务的有用表示。BERT在[9]中引入用于视频动作识别,并在两个主要动作识别数据集UCF-101[20]和JHMDB-51[12]上实现SOTA性能。我们受到BERT的启发,特别是它在动作识别方面的应用。
在[9]中,BERT被用作后期池函数,以取代先前广泛使用的全局平均池(GAP)(见章节0.什么是BERT?)。BERT的输入是通常在GAP和FC层之前获取的内部CNN特征图。为了保存位置信息,学习的位置编码被添加到提取的特征。为了执行分类,如[4]所示,附加了额外的分类标记xcls。利用相应的分类向量 ycls 来实现分类,该分类向量 ycls 被发送到FC层用于分类预测。
BERT的通用单头自我注意模型公式如下:
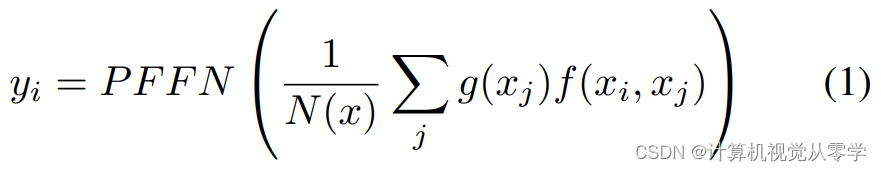
其中,xi 值是包括位置编码的输入向量;i 表示目标输出时间位置的索引;j 表示所有可能的组合;N(x) 是归一化项。函数 g() 是BERT自注意力机制内的线性投影,而函数 f() 表示 xi 和 xj 之间的相似性,如 ,其中函数 θ() 和 φ() 是线性投影。可学习函数 g() 、 θ() 和 φ() 试图将特征嵌入向量投影到注意力机制更有效工作的更好空间。g() 、θ() 和φ() 函数的输出通常称为key、query和value[24]。PFFN是位置前馈网络 (position-wise feed forward network),分别应用于所有位置,与
相同,其中 GELU() 是高斯误差线性单元(GELU)激活函数[24]。分类向量 ycls 的形式与 yi 相似,
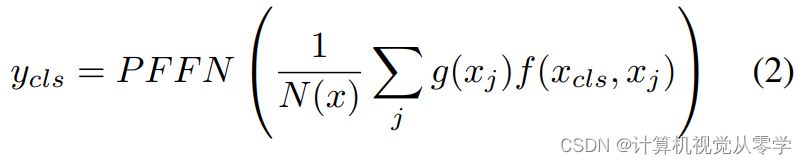
在我们的工作中,由于我们的重点是研究视频分类的影响,我们的主要目标是使用学习的分类嵌入 ycls 将视频的时间特征聚合为视频分类的单个特征。输入向量 xi 是片段(segments)的特征向量。如果在异常MIL中,特征表示 yi 的学习好的子空间比原始特征 xi 的子空间工作得更好,则该子空间是一个优势。然而,我们有一个强烈的动机,为什么我们不必将其用于应用目的——以推理模式获得一个与原始MIL框架一样复杂度低的解决方案[21].
3.2 提出的训练流程
图1所示为我们提出的具有显式视频分类的异常检测的框图。我们将此建议的解决方案称为MIL-BERT。
图1 (a) 是训练流程。首先,给定视频,将帧提取为16帧的片段。使用预训练的3D CNN骨干网络来
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









