



 该博客介绍了如何使用TensorFlow2构建Deep Convolutional Generative Adversarial Networks(DCGAN)。主要内容包括生成器和鉴别器模型的构建,模型训练过程中的损失函数,以及预处理步骤的简要提及。
该博客介绍了如何使用TensorFlow2构建Deep Convolutional Generative Adversarial Networks(DCGAN)。主要内容包括生成器和鉴别器模型的构建,模型训练过程中的损失函数,以及预处理步骤的简要提及。
主体部分
我的GitHub
导入相应的包
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Reshape
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import UpSampling2D
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.layers import Flatten
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import mnist
import numpy as np
from PIL import Image
import argparse
import math
import tensorflow as tf
1.生成器模型generator_model
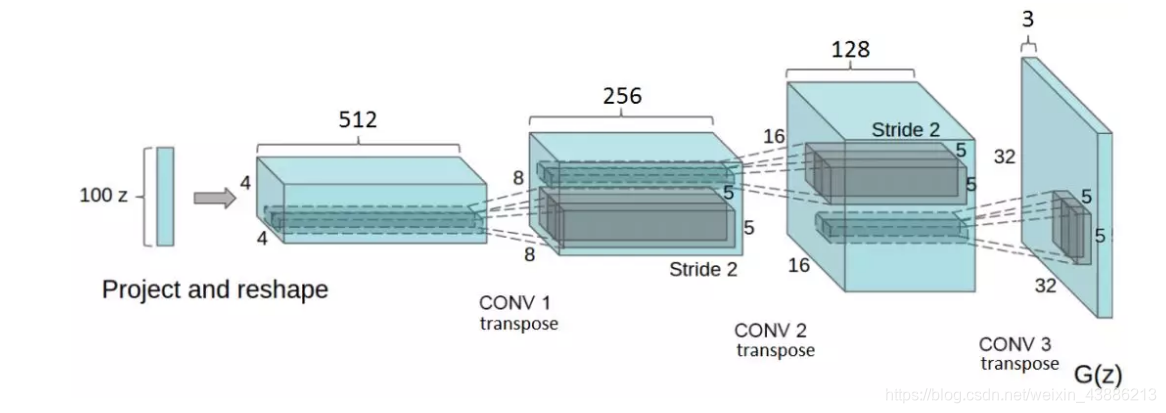
def generator_model():
model = Sequential()
model.add(Dense(256*7*7,input_shape=(100,)))
model.add(Activation('tanh'))
model.add(Dense(128*7*7))
model.add(BatchNormalization())
model.add(Activation('tanh'))
model.add(Reshape((7, 7, 128), input_shape=(128*7*7,)))
model.add(UpSampling2D(size=(2, 2)))
model.add(Conv2D(64, (5, 5), padding='same'))
model.add(Activation('tanh'))
model.add(UpSampling2D(size=(2, 2)))
model.add(Conv2D(1, (5, 5), padding='same'))
model.add(Activation('tanh'))
return model
2.生成鉴别器模型discriminator_model
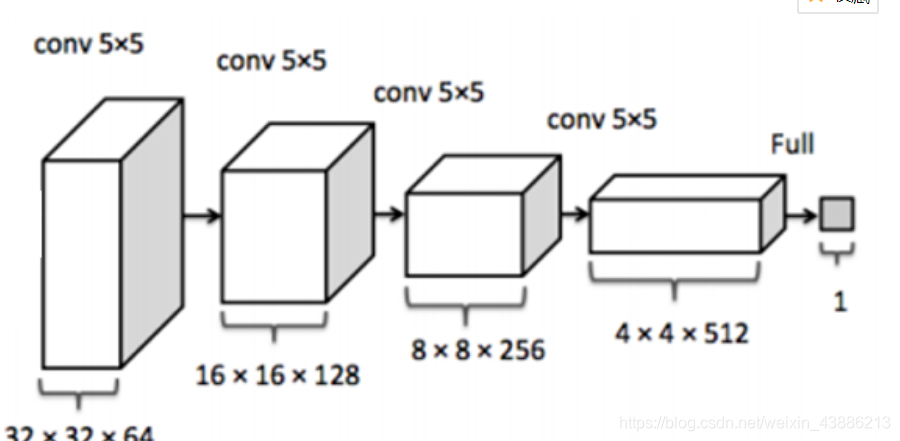
def discriminator_model():
model = Sequential()
model.add(
Conv2D(64, (5, 5),
padding='same',
input_shape=(28, 28, 1))
)
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, (5, 5)))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation('tanh'))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
生成混合模型
def generator_containing_discriminator(g, d):
model = Sequential()
model.add(g)
d.trainable = False
model.add(d)
return model
损失部分
我们希望,生成器能够生成鉴别器能够鉴别的图像,鉴别器对真实图像输出接近 1 的概率,对虚假图像输出接近 0 的概率。为了做到这一点,判别器需要两类损失,其总损失函数是两部分损失函数之和
d_loss = d.train_on_batch(X, y)
print("batch %d d_loss : %f" % (index, d_loss))
noise = np.random.uniform(-1, 1, (BATCH_SIZE, 100))
d.trainable = False
g_loss = d_on_g.train_on_batch(noise, [1] * BATCH_SIZE)
预处理部分见GitHub


















 664
664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









