




一、mysql的复制原理
- 当数据写入到Master节点后,会将操作写入Binarylog中,salve接待你会通过I/ thread 线程读取Binarylog,并写入到Relay log中,然后SQL thread线程会读取Relay log信息写道salve库中
- 使用binlog 的三种格式来保证主从一致
- Statement(Statement-Based Replication,SBR):每一条会修改数据的 SQL 都会记录在 binlog 中。
- 存在的问题:如果根据多个条件(索引)删除数据,主库可能根据a条件删除,从库可能根据b条件删除,会造成数据不一致问题
- Row(Row-Based Replication,RBR):不记录 SQL 语句上下文信息,仅保存哪条记录被修改。
- 问题:占用空间比较多,并且如果执行的事务比较大,影响行数比较多的话,binlog会比较大,并且写binlog也会消耗IO资源,影响执行速度
- Mixed(Mixed-Based Replication,MBR):Statement 和 Row 的混合体。
- mysql会自己判断是否 存在索引影响,从而选择保存格式
- Statement(Statement-Based Replication,SBR):每一条会修改数据的 SQL 都会记录在 binlog 中。
- 双M架构下的循环复制
- 双m模式下,互为从,因此会存在互相写log的问题:借助server id,在前面的实验中,我们已经知道在binlog中会记录server id
- 主备库server id必须不同,如果相同不允许设置为主备关系
- 一个备库在binlog的重放过程中,生成与原binlog的server id相同的新的binlog
- 每个库在收到主库发过来的binlog日志时,先判断server id,如果与自己的相同说明是自己生成的,就会直接丢弃这个日志。
- 双m模式下,互为从,因此会存在互相写log的问题:借助server id,在前面的实验中,我们已经知道在binlog中会记录server id
二、分库分表策略
- 垂直分库:根据不同的业务将表分配到不同的数据库上,减轻数据库的请求压力
- 水平分表:将不同的业务数据分到不同的表中
三、聚簇索引(索引和数据存放一块)和非聚簇索引(索引和数字分开存放)
- 索引都是存在磁盘
- innodb的索引和数据共同存放在同一个文件,但是有多个索引的情况,只会有一个索引和数据存在同一文件中,其他的索引的叶子节点会存储索引的key,当查询数据时,会根据key查找数据(回表查询)
- myisam都是非聚簇索引
- 索引存储会根据存储类型,存储到不同文件
- mysql默认会有三种存储文件
- .frm:表结构
- .MYD存放myisam数据
- . MYI:存放myisam索引
- .ibd 存放innodb的索引
四、MYSQL锁的类型
- 基于锁的属性:共享锁和排他锁
- 共享锁又称为读锁:读锁的不影响读,但是会禁止写锁
- 排他锁:又称为写锁:禁止添加其他锁
- 基于锁的粒度:行级锁(innodb)、表级锁、页级锁、记录锁、间隙锁、临建锁
- 间隙锁:只会出现在可重复读事务中 所著某一个区间,当相邻的ID出现空隙则会出现间隙锁
- 基于锁的状态:意向锁(当某一线程需要加锁的时候,会先去判断是否有更高粒度的锁存在)、意向排他锁
五、Hibernate和Mybatis的区别
- 相同点
- 构建流程相同:通过SessionFactoryBuilder根据xml配置文件生成SessionFactory, 然后由SessionFactory生成session,通过session执行sql
- 都支持JDBC和JTA事务
- 不同点
- H 全自动ROM框架 M 半自动ROM框架
- H 具有完整的日志模块
- M的二级缓存建立在每一个映射的xml中通过cache-ref实现 H 完全代理二级缓存
- M 便于sql优化
六、面向对象的特征
- 继承:通用共性属性、方法;划分职能作用,便于数据的独立和区分性
- 封装:保护内部数据,对外抛出通用方法,提供代码的维护性
- 多态:对父类方法的调用,会呈现子类重写的方法逻辑
- 抽象(非java特有)
七、抽象类(abstract class)和接口(interface)有什么异同
- 都不可以被实例化、接口和抽象方法都需要被重写
- 接口可以定义构造函数
- 抽象类可以有具体的方法,接口只能定义方法
- 接口中的方法都是public,因为接口的方法都需要被实现
- 抽象类中可以定义成员变量、接口只能定义常量
- 抽象方法必须在抽象类中,抽象方法必须被重写
- 抽象类中可以包含静态方法,接口不能
- 静态方法不能被重写
- 单继承和多实现
八、AOP的详细理解:面向切面编程,它是为了解耦而生
- 切面:创建一个切面类,来自定义切面逻辑
- 连接点:确定切入的点位
- 通知:在执行连接点的时候,确定执行的规则:befor、after、around
- 切点:匹配连接点
- 引入:
- 目标对象:被通知的对象
- AOP代理:
九、引用(指针)类型
- 强引用:基本的new 对象,队中的内存块一直被指针引用
- 软引用:java.lang.ref.SoftReference类来表示软引用
- 当JVM内存不足,软引用会被回收
- 弱引用: java.lang.ref.WeakReference来表示弱引用
- gc会处理掉所有的弱引用
- 虚引用: PhantomReference 类来表示
- 随时可能被gc回收,虚引用必须要和 ReferenceQueue 引用队列一起使用
- ReferenceQueue
- 虚引用会被装到队列中,当gc进行回收的时候,会先检查队列,如果队列中的虚引用,引用了堆外数据,则也会回收堆外的内存
十、ThreaLocal管理全局线程对象
- 底层通过ThreadLocalMap实现的k-v形式
- Thread 线程创建的时候,内部有一个Map
- 线程的局部变量:为每一个线程提供一个变量副本,避免了并发下变量冲突
- 本质在JVM在每一个线程中创建一个ThreadLocalMap,以线程(ThreadLocal)为key,并且继承了 WeakReference 弱引用
- 当ThreaLocal tl = new ThreaLocal();
- ThreaLocal 内部引用entry的key
- 当tl断开引用,但是当前线程依然存在,但是threadLocal对象因为key一直在引用,因此无法被回收,因此key这里设置为弱引用,因此,tl没有引用的时候,可以直接被回收,此时key也会成为null
- 不使用ThreadLocal时,一定要remove掉
- 当key是null,value将无法被获取,因此无法回收value
- ThreadLocal.remove() : 移除entry
- 当ThreaLocal tl = new ThreaLocal();
- 本质在JVM在每一个线程中创建一个ThreadLocalMap,以线程(ThreadLocal)为key,并且继承了 WeakReference 弱引用
- 系统任意地方使用,在同一个线程中都会使用同一个对象(local.set(xxx);local.get(xxx))
十一、synchronized和ReentrantLock
- synchronized:关键字,无法判断锁状态,会一直等待锁释放,适合锁小块代码
- lock:类,可以获取锁状态,lock.tryLock() 尝试重新获取锁,适合锁大量代码
- 延伸问题:之所以使用锁,是因为多线程操作同一个变量引发的是数据错问题
- 原子性:原子是最小的不可分割的单位,当前原子操作,不会被其他线程干扰
- 可见性,线程所操作的变量,会被立即同步到主内存中,其他线程可以获取到最新的数据
- volatile:线程直接操作主内存变量,而不是复制的本地内存
- 有序性:指令串行执行,不会出现指令重排序
十二、线程的状态
- 新建:线程被创建但未被运行
- 就绪:线程已进入jvm,但不确定是否在运行还是在等待
- 阻塞
- 等待:wait
- 终止
十三、死锁
- AB分别占用AB锁,AB此时要获取对方的锁后释放自身锁,因此,永远释放不了锁
- jps -l :获取当前java的进程
- jstack 进程号: 查看进程信息 :found a deadlock (发现一个死锁)
十四、AtomicInteger底层实现原理
- AbstractQueuedSynchronizer(AQS):其是 Java 并发包中,实现各种同步结构和部分其他组成单元(如线程池中的 Worker)的基础
- AQS内部可以分为三部分
- 一个使用volatile修饰的变量,包括了set和get
- 一个先进先出的队列
- 基于cas的操作方法
- 实现AQS的两个必备条件
- acquire :获取资源的独占权
- release:释放资源
- AQS内部可以分为三部分
十五、 ReentrantLock 解析AQS的实现
- AQS内部提供了acquire获取资源锁的方法
public final void acquire(int arg) {
if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
//tryAcquire:尝试获取资源锁
//acquireQueued:获取锁失败
- ReentrantLock 提供了两种获取资源所的方法
- NonfairSync:非公平锁
- FairSync:公平锁
- 以非公平锁讲解
- 当一个线程尝试获取资源锁(tryAcquire),首先获取AQS的状态:0 代表资源未被占用
- 当未被占用的情况,则会使用cas修改AQS状态
- 当被占用的情况下,会出现两种情况
- 被当前线程占用:当前线程占用了同一个对象的其他方法,此时会进行重入锁,锁状态+1
- 被其他线程占用:重新回到锁竞争的队列
- 当前一个节点获取锁失败后,会执行acquireQueued方法
- 循环获取当前节点,判断当前节点的前一个节点是否是头节点以及尝试获取锁
- 如果满足上述条件并且获取锁,设置当前线程为头节点
- 当一个线程尝试获取资源锁(tryAcquire),首先获取AQS的状态:0 代表资源未被占用
十六、类加载过程以及双亲委派
- 加载:java将字节码数据加载到jvm中并映射成jvm可识别的class对象,数据可以是class文件、jar文件以及网络资源等
- 链接:核心步骤,将原始的类定义信息转入JVM运行过程
- 验证:jvm检验字节信息是否符合要求
- 准备:创建类或者接口中的静态变量并初始化值(分配内存空间)
- 解析:将常量池中的符号引用替换为直接引用
- 初始化:初始化类,包括变量的赋值、静态代码块的执行,父级的相关初始化优先于子类
- 双亲委派:加载子类的时候,会优先在父级中查找相关的类型,查找不到才会加载子类
- jvm加载class的时候,会先执行loadclass方法,在父级中查找相关类型
- 当没有找到后,会执行当前类的findclass方法:根据名称读取文件的二进制字节数组
- dnfineclass:把字节转化为class文件
十七、自定义类加载器
- 加密class文件,避免被轻易的反编译
- 编译:javac -xxx.java
- 反编译:javap -v xxx.class
- 从其他地方获取class文件,需要自定义加载器
- 根据双亲委派原则,可以实现自定义类加载器,继承loadclass,实现findclass
- 自定义MyClassLoader,需要定义一个People类并编译成class文件
MyClassLoader mcl = new MyClassLoader(); Class<?> clazz = Class.forName("People", true, mcl); Object obj = clazz.newInstance();
十八、关于运行时动态生成Java类
- java程序生成源码或者提前预备好源码,通过ProcessBuilder 操作系统命令执行javac编译源码,然后通过自定义的类加载器加载编译后的class文件
十九、谈谈JVM内存区域的划分,哪些区域可能发生OutOfMemoryError
- 计数器:每一个线程都会有自己的程序计数器,程序计数器会存储当前线程正在执行的java方法的JVM指令地址,如果执行的是本地方法,则地址为undefined
- 虚拟机栈:每个线程在创建的时候都会创建一个虚拟机栈,内部保存着各个栈帧,对应着java方法一次次的调用,同一时间只会有一个活动的栈帧
- 栈帧:存储着局部变量、操作数栈、动态链接、方法退出等信息
- 堆:java内存的核心管理区域,用来存放对象的实例,几乎所有的对象实例都存储在堆中,堆中的信息得所有的线程共享,启动虚拟机的是否,可以通过Xmx等参数指定虚拟机的内存大小
- 因为存在垃圾收集器,因此为了垃圾回收问题,堆内存还会被分为新生代、老年代
- 方法区:用于存储元数据,例如:类结构信息、以及对应的运行时常量、字段、方法代码等;属于共享区域,jdk1.8之前被称为永久代,现在已经移除了永久代增加了此元数据区
- 运行时常量池:存放着各种形态的常量信息,不管是编译过程生成的字面量,还是在运行期决定的符号引用
- 编译常量:被final修饰的变量或者字符串相加的常量,在编译阶段都会被jvm优化放入常量池,而不会等待运行时再获取并放入常量池
- 经典案例:Sting s = “a” + “b” + “c”:本质上如果常量池中没有 abc,则会创建一个abc对象,否则不会创建新对象而是直接去常量池中拿
- 本地方法栈:和java虚拟机非常相似,支持堆本地方法(native)的调用,每一个线程都会创建一个对应的本地方法栈
- jvm本身就是一个本地程序,除了上述之外,其实jvm还会使用其他内存来完成自身的一些基本任务
- 直接内存、codeCache等其他内存
二十、关于OOM
- 可能发生OOM的原因
- 内存泄漏、堆的大小不合理,不能支撑class对象的加载
- 栈溢出:当函数不断地被调用,会将函数的参数不断地积压在栈中,可能会出现StackOverFlowError,如果jvm尝试扩展栈的内存大小失败,也会抛出OutOfMemoryError
- 方法区(旧版本的永久代):当不断地创建新的实例化对象或者填充运行时常量,可能会导致堆内存OOM
二十一、如何监控和诊断JVM堆内和堆外内存使用
-
堆外内存
- 除了jvm管理的内存之外的系统内存
- ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024);
- 直接调用对外内存缓存到buffer
-
可视化工具JConsole、VisualVM
-
JDK 的jar包中已经引入了jconsole
- windows系统直接 命令窗口 输入jconsole 即可打开可视化界面
- linux在启动java 项目的时候,添加上启动参数
nohup java -Xms128M -Xmx256M -Djava.rmi.server.hostname=192.169.1.71 -Dcom.sun.management.jmxremote.rmi.port=10099 -Dcom.sun.management.jmxremote.port=10099 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -jar web.jar & Djava.rmi.server.hostname:服务所在的服务器ip Dcom.sun.management.jmxremote.port:JConsole链接的端口号,不能和其他端口重复 Dcom.sun.management.jmxremote.authenticate:false代表可以不需要账号密码认证 -
JDK 的jar包中已经引入了VisualVM
- windows系统直接 命令窗口 输入jconsole 即可打开可视化界面
- linux在启动java 项目的时候,添加上启动参数,同JConsole
- 在服务器{JAVA_HOME}/bin目录建立文件:jstatd.all.policy(名字随便,符合*.policy即可)
grant codebase "file:${java.home}/../lib/tools.jar" { permission java.security.AllPermission; }; # 启动policy:nohup $JAVA_HOME/bin/jstatd -J-Djava.security.policy=jstatd.all.policy - 1009 & # 默认端口1009
二十二、JVM通过GC年代划分
- 新生代:对象创建和销毁的区域
- Eden(伊甸园):对象初始化分配的区域
- 内部还会被分为多个TLAB
- TLAB:和线程一一对应,每一个线程会有一私有缓存区,被称为TALB
- TLAB会包含三个标志点
- start:缓存开始点
- top:缓存当前位置
- end:TALB的混村最大值
- 当top到达end点的时候,会重新分配一个新的TALB
- TLAB会包含三个标志点
- TLAB:和线程一一对应,每一个线程会有一私有缓存区,被称为TALB
- 内部还会被分为多个TLAB
- Survivor(幸存者):会被分为两个区域,一个from一个to,被用来放置没有被GC清理的对象
- GC在工作的时候,会把清理不掉的对象拷贝到to区域
- Virtual:暂时不可用区域,默认JVM只会使用初始化的内存,当需求的内存越来越大,才会使用此区域
- Eden(伊甸园):对象初始化分配的区域
- 老年代
- Survivor区域的对象会被拷贝到老年代
- 在Eden中如果对象过大,在新生代中找不到能存储此对象的连续空间,则会被直接分配到老年代
- 永久代:这部分就是早期 Hotspot JVM 的方法区实现方式了,储存 Java 类元数据、常量池、Intern 字符串缓存
- 在 JDK 8 之后就不存在永久代,被替换为MetaSpace(元数据区)
- 可以通过启动参数设置
- 最大内存:-Xmx value
- 初始化的内存:-Xms value
- 老年代和新生代的比例:-XX:NewRatio=value
- 默认情况下,这个数值是 2,意味着老年代是新生代的 2 倍大;换句话说,新生代是堆大小的 1/3。
- 设置新生代的大小:-XX:NewSize=value
- 设置Eden和Survivor 的比例:-XX:SurvivorRatio=value
- YoungGen=Eden + 2*Survivor ;新生代和永久代的计算比例
- 如果设置为8,也就是代表Eden是Survivor的八倍
- YoungGen=Eden + 2*Survivor ;新生代和永久代的计算比例
- 可以通过启动参数设置
二十三、利用NMT特性,分析JVM
- 准备工作
-XX:NativeMemoryTracking=summary:启动时候,选择NMT的统计模式
-XX:+UnlockDiagnosticVMOptions -XX:+PrintNMTStatistics:应用退出的时候打印统计信息
- 统计信息分析
- java Heap:java堆内存的信息(剩余内存和被使用的内存)
- class:统计java类元数据占用的空间
-XX:MaxMetaspaceSize=value:设置类元数据大小 #Thread:包括java主线程、Cleaner线程等,也包括了GC线程 #如果小系统,可以通过修改使用的GC #G1回收器复杂度最高,效果最好,占用线程数最多 #Parallel GC:线程数较少 #修改GC使用 -XX:+UseG1GC -XX:+UseParallelGC -XX:+UseSerialGC- code:统计了其他内存及codeCache使用的内存,也就是 JIT compiler 存储编译热点方法等信息的地方
- compiler 部分的内存消耗较大,默认是开启的,如果我们不需要编辑,则可以关闭
- -XX:-TieredCompilation
二十四、JAVA的垃圾回收器都有哪些
- JVM提供商有很多家,具体分析Oracle的JDK
- Serial GC:最古老的GC,使用单线程,并且在运行时会进入Stop-The-World状态,设计简单
- 老年代区域采用标记-整理算法、新生代采取复制算法
- -XX:+UseSerialGC
- ParNew GC:新生代的GC,实际是Serial GC的多线程版本,通常配合CMS GC工作
- -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
- CMS GC:基于标记-清除算法
- 减少了停顿时间,降低了系统响应时间
- 会存在内存碎片,长时间运行的情况下会存在full gc
- 在并发情况下会抢占用户线程、占用更多的cpu
- -XX:+UseParallelGC
- Parrallel GC:也是使用标记-整理算法,整体复杂度较高,是新生代和老年代是同步进行的,在web环境下效率较高
- -XX:+UseParallelGC
- -XX:MaxGCPauseMillis=value:设置停顿时间
- jdk9之后默认使用了G1GC
- G1可以直观的设置停顿时间,不能保证每次都是完美的停顿时间,但是避免了超长时间的停顿
- G1将每个区域作为一个region,region之间是复制算法,总体可以被看作标记-整理算法,避免了内存碎片
- Serial GC:最古老的GC,使用单线程,并且在运行时会进入Stop-The-World状态,设计简单
二十五、垃圾收集的原理和基础概念
- 垃圾回收器主要作用域两个地方:对象实例回收和方法区的元数据回收
- 引用计数法:为对象的引用添加一个计数,当计数为0则代表没有对象引用了
- 因为java难以处理循环引用,因此java中使用可达性分析
- 将对象及其引用关系看作一张图,选定活动的对象(栈引用的对象、静态属性引用的都西昂和常量)作为GC Roots,当一个对象无法和GC Roots建立引用关系,则为可回收对象
二十六、常见的垃圾收集算法
- 复制算法:将存活的对象复制到to区域,拷贝过程中,按照顺序放置对象,可以避免内存碎片
- 复制存在的问题就是浪费了一部分内存,对于G1,则还要多维护region之间的关系
- 标记-清除:标记需要被回收的对象,然后清除,此过程会导致对象和对象之间存在空置的内存,也就是所谓的内存碎片
- 标记-整理:先标记所有需要被回收的对象,然后清理对象后依次移动对象,避免内存碎片
二十七、java程序不断地创建新对象,新对象都会被放置在Eden区域
- 第一步:当Eden区域达到垃圾回收的标准后,会进行回收,存活下来的对象会被复制到Survivor 区域(当前区域被称为from),对象标记+1
- 第二步:当Eden再次需要回收的时候,存活下来的对象以及from中的对象会被复制到另外一个Survivor 区域(此区域及为to),对象标记+1
- 接下来,类似的过程会不不断地发生,直到有的对象的标记达到一定的数值,则会被复制到老年代
-XX:MaxTenuringThreshold= num:设置标记的数值 - 老年代中则会采用相关的算法进行GC
二十八、GC的优化思路
- 主要分为三个点:内存占用、停顿时间以及吞吐量
- 如果服务偶尔出现抖动,较长时间的服务停顿:则将停顿时间修改控制在可接受的范围之内
- 通过 jstat 工具监控gc的变化:主要利用JVM内建的指令对Java应用程序的资源和性能进行实时的命令行的监控,包括了对Heap size和垃圾回收状况的监控
- 命令:jstat [Options] vmid [interval] [count]
- Options:
- 一般使用 -gcutil :查看gc情况
- -gcnewcapacity:查看年轻代对象的信息及其占用量
- -gcoldcapacity:查看老年代对象的信息及其占用量
- -gcnew:查看年轻代对象的信息
- -gcold:查看老年代对象的信息
- -gc显示gc的信息,查看gc的次数,及时间
- 使用top -Hp显示进程所有的线程信息查找CPU耗时最长线程PID
- 使用jstack查找耗时进程是哪个函数
- vmid,VM的进程号,即当前运行的java进程号
- interval,间隔时间,单位为秒或者毫秒
- count,打印次数,如果缺省则打印无数次
- Options:
- jstat -gc 12538 5000 :即会每5秒一次显示进程号为12538的java进成的GC情况

- 针对当前环境选择合适的gc
- 响应时间优先:选择CMS和G1
- 在乎内存:Parrallel GC
- 根据服务器的配置,设置相关参数、扩大内存等
- jstack命令用于生成虚拟机当前时刻的线程快照(一般称为threaddump或javacore文件)。线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如请求外部资源导致的长时间等待、线程间死锁、死循环等都是导致线程长时间停顿的常见原因。线程出现停顿的时候通过jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做些什么事情,或者等待着什么资源。
- jstat -xxxx PID
- 查看当前进程Class类加载的统计: class
- 查看编译情况:compiler
- 查看垃圾回收gc统计:gc

二十九、Java内存模型中的happen-before是什么
- 保证顺序执行,保证在某操作之后必须执行后续规定的某一个操作
- 线程内执行的每个操作,都保证 happen-before 后面的操作,这就保证了基本的程序顺序规则
- 对于 volatile 变量,对它的写操作,保证 happen-before 在随后对该变量的读取操作
- 对于一个锁的解锁操作,保证 happen-before 加锁操作
- 对象构建完成,保证 happen-before 于 finalizer 的开始动作
- 甚至是类似线程内部操作的完成,保证 happen-before 其他 Thread.join() 的线程等待
三十、Exception和error
- 都继承了Throwable
- Exception是运行时异常
- error是系统异常
三十一、Hashtable、HashMap、TreeMap 有什么不同
- Hashtable:早期提供的,不支持null键和值,同步问题(synchronized)导致性能较差
- 每一个add方法都加锁
- 使用Enumeration
- 默认大小11,扩容采用old*2 +1
- HashMap:支持null键和值,不是同步,性能较高,使用put和get
- 使用iterator
- hashmap源码中 newTab[e.hash & (newCap - 1)];
- 默认大小16,加载因子0.75,扩容采用2次幂
- 1.7之前采用的是重新计算hash
- 1.8之后的二次幂扩容(图)
- 容量为16转化为二进制是10000,因此15的二进制是01111
- 当任意hash 和 01111 进行& 运算的时候,得到结果的后四位都是不同的,因此不会出现hash碰撞问题
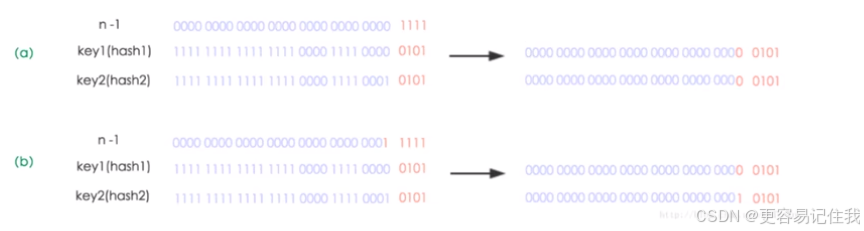
- HashMap的默认大小必须是2的,避免hash计算二进制,造成位数0,避免浪费资源
- 1.7版本 采用数组+链表的进行头部插入
- 1.8版本 采用数组+链表+红黑树:当链长达到8并且数组数量大于64时,会将链表替换成红黑树
- 线程不安全:当多个线程竞争的时候,可能存在线程打断,数据错误问题
- TreeMap:基于红黑树的一种顺序访问的map
- Collections.synchronizedMap():线程安全
- ConcurrentHashMap:大量使用了Volatile和cas,保证了线程安全
- volatile:可见性、禁止重排序、不保证原子性
- 程1从主内存中拿了一个值为1的数据到自己的工作空间里面进行加1的操作,值变为2,写回主内存,然后还没有来得及通知其他线程,线程1就被线程2抢占了,CPU分配,线程1被挂起,线程2还是拿着原来主内存中的数据值为1进行加1,值变成2,写回主内存,将主内存值为2的替换成2,这时线程1的通知到了,线程2重新去主内存拿值为2的数据。
- 经典的单例模式,重排序会导致对象引用先于对象初始化,多线程下,会出现线程拿到空对象
- 所有线程都可见主内存的中被volatile修饰的变量,而不是复制到自身内存的副本
- volatile:可见性、禁止重排序、不保证原子性
三十二、关于String类为final修饰并且不可变
- String字符通常都被还在String常量池
- 因为字符串是不可变的,所以在它创建的时候HashCode就被缓存了,不需要重新计算
- 这就使得字符串很适合作为Map中的键,字符串的处理速度要快过其它的键对象。这就是HashMap中的键往往都使用字符串。
三十三、 & 和 && 的区别
- 当作为运算符号的时候
- &不管左边什么结果都会执行右边的操作
- && 当左边的操作是false的时候,则不会执行右边的逻辑
- 当作为二进制运算符号的的时候
- & 与运算:都为1才为1
- | 或运算:一个为1则为1
- ^ 异或运算:不同为1、相同为0
- >> x 右移x位:高位补0
- >>> x 右移x位:正数高位补0、负数高位补1
三十四、针对String类型的变量初始化和赋值
- 当创建一个String对象的时候,会被放到常量池中
- 1.7之后,常量池从方法区被迁移到了堆内存
- 如果new String(“xxxx”),会先在堆内存分配空间用来存储常量池的地址
- 所以String aa = “xxx”;和String bb = new String(“xxx”),虽然最终指向的String常量池的地址是一样的,但是bb首先指向到是对内存的地址,堆内存最终指向常量池的地址
- 当使用+ 拼接的时候,会产生一个新的String对象,而不是修改之前旧的String对象
- 使用 StringBuilder和StringBuffer,会修改原字符串
- StringBuilder线程不安全
- StringBuffer的方法都使用了synchronized
三十五、字符流和字节流
- 将字节流转化为字符流
- InputStreamReader inputStreamReader = new InputStreamReader(new FileInputStream(new File(“”)));
//将对象写出到文件 ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(new File("D://obj"))); objectOutputStream.writeObject(new User()); //将文件内容读取为对象 ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream(new File("D://obj"))); User user = (User)objectInputStream.readObject();
三十六、深浅克隆以及序列化
- 浅克隆,引用对象指向同一个内存地址
- 深克隆,引用对象被创建一个新对象
- 定义一个通用的clone方法,此方法需要对象实现序列化
public static <T extends Serializable> T clone(T obj) throws Exception {
ByteArrayOutputStream bout = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bout);
oos.writeObject(obj);
ByteArrayInputStream bin = new ByteArrayInputStream(bout.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bin);
return (T) ois.readObject();
}
- 实现Serializable 接口代表当前对象可以被实例化,将对象转化为流,则为真正的序列化操作
三十七、final、finally、finalize 的区别
- final:定义为不可变
- finally:不论什么结果,都或执行finally中的操作
- finalize:Object类的方法,当对象被标记为被回收状态,GC会在回收前调用对象的finalize方法
三十八、常见的异常
● java.lang.ClassNotFoundException 指定的类找不到;出现原因:类的名称和路径加载错误;通常都是程序试图通过字符串来加载某个类时可能引发异常。
● java.lang.NumberFormatException 字符串转换为数字异常;出现原因:字符型数据中包含非数字型字符。
● java.lang.IndexOutOfBoundsException 数组角标越界异常,常见于操作数组对象时发生。
● java.lang.IllegalArgumentException 方法传递参数错误。
● java.lang.ClassCastException 数据类型转换异常。
● java.lang.NoClassDefFoundException 未找到类定义错误。
● SQLException SQL 异常,常见于操作数据库时的 SQL 语句错误。
● java.lang.InstantiationException 实例化异常。
● java.lang.NoSuchMethodException 方法不存在异常。
三十九、Math.round(xxx)
- 四舍五入的算法:四舍五入的窍门,在数值+0.5取整
- 例如Math.round(11.5):结果12
- 例如Math.round(-11.5):结果-11
四十、switch支持的类型
- char, byte, short, int, Character, Byte, Short, Integer, String, enum
四十一、获取日期相关操作
LocalDate today = LocalDate.now();
//获取本月第一天
LocalDate firstday = LocalDate.of(today.getYear(), today.getMonth(), 1);
//获取本月最后一天
LocalDate lastDay = today.with(TemporalAdjusters.lastDayOfMonth());
//格式化日期
DateTimeFormatter newFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
LocalDate date2 = LocalDate.now();
System.out.println(date2.format(newFormatter));
//获取今天
LocalDateTime today = LocalDateTime.now();
//获取昨天
LocalDateTime yesterday = today.minusDays(1);
四十二、java8新特性排序用法
-
根据对象的属性排序集合
userList.stream().sorted(Comparator.comparing(User::getUserNo)).collect(Collectors.toList()); -
根据map的key排序map;默认从小到大排序,reversed从大到小排序
Map<Integer, Object> result = new LinkedHashMap<>(); HashMap<Integer, Object> map = new HashMap<>(); map.entrySet().stream() .sorted(Map.Entry.<Integer, Object>comparingByKey().reversed()) .forEachOrdered(x -> result.put(x.getKey(), x.getValue())); -
根据map的key对应的值去重
nowCollectList = nowCollectList.stream() .collect(Collectors.collectingAndThen( Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(value -> value.get("id") + ";"))), ArrayList::new));
四十三、事务的四大特性(ACID)
- 原子性(atomicity):不可分割的最小单元,同时失败或成功
- 通过undolog保证原子性,它记录了需要回滚的日志信息,事务回滚会撤销已经完成的sql操作
- 一致性(consistency):从一种状态到另一种状态保持一致
- 由其他三大特性共同保证
- 隔离性(isolation):事务之间互不干扰
- 持久性(durability):事物的操作会持久化数据
- 通过redolog保证,mysql修改数据会记录到redolog中,最终会根据日志进行持久化操作
四十四、MVCC多版本并发控制保证事务的隔离性
- 读读:不存在问题
- 读写:有线程安全,可能存在脏读、幻读、不可重复读
- 写写::有线程安全,可能存在数据丢失
- MVCC是一种用来解决读写冲突的无锁并发机制,也就是为事务 中的每一项增加个时间戳,为每一次修改增加一个版本号,版本和时间戳相关关联 ,读事务,只会读取事务开始前的数据快照
四十五、MVCC实现原理:undolog、read view和三个隐藏字段
- DR_TRX_ID:最新修改的事务id
- DB_ROLL_PTR:回滚指针,指向这条记录的上一个版本,用于配合undolog
- DB_ROW_ID:隐藏的主键,如果表没有主键,innodb会生成一个6字节主键
- undolog详解:回滚日志
- 执行插入操作,事务提交后,会删除log日志
- 当进行删除或者更新操纵,除了事务提交之后,还要再快照以及其他事务不涉及到此日志的情况下,才会删除log
- purge 线程进行 log的删除
- readView
- 当某个事务在执行快照读的时候,对该记录创建一个readView 视图,把它当作当前事务能够看到的那个面板数据
- readview遵循可见性算法,去除当前事务的id和系统当前活跃事务id进行比较,如果不符合,则取undolog中查找与之匹配的事务id对应的数据
- 三个全局属性
- trx_list:记录了readview生成时刻的活跃事务id集合
- up_limit_id:记录了trx_list列表中事务ID最小的ID
- low_limit_id:read view生成时刻系统尚未分配的下一个事务id
- 在RC隔离模式下,事务中的每一个 select 读操作都会创建 read view 快照
- 在RR隔离模式下,快照的产生只会在事务开启后第一个 select 读操作后创建 readview 快照
- undolog详解:回滚日志
四十六、并发事务
- 脏读:读到其他事务未提交的数据,
- 幻读:两次读取,第二次读取到了其他事务提交的新数据
- 不可重复读:两次读取,第二次读取到了其他事务更新的数据
- 串行化:按照顺序依次执行
四十七、Spring隔离级别
- 默认:mysql默认事务
- 读未提交(READ UNCOMMITEED):会出现脏读、幻读、不可重复读
- 读已提交(READ COMMITEED):会出现幻读、不可重复读
- 可重复读(REPEATABLE READ):不可读取未提交的数据,会出现不可重复读
- 串行读(SERIALIZABLE):按照顺序依次执行sql
四十八、事物的传播特性
- REQUIRED(默认):加入当前事务
- Never:不加入事务
- MANDATORY: 支持当前事务,若没有事务,抛出异常
- NOT_SUPPORTED: 非事务运行,挂起当前事务
- REQUIRES_NEW: 挂起当前事务,创建新的事务
- NETSETD: 嵌套事务,支持当前事务并且和当前事务同时提交和回滚,不影响当前事务
- SUPPORT: 支持当前事务,不新启事务
四十九、事务失效原因
-
bean没有被spring管理
-
方法的修饰符不是public
- TransactionInterceptor 通过 代理 执行invokeWithinTransaction 方法 ,在方法中通过getTransactionAttribute -> computeTransactionAttribute 判断 public方法
-
方法是static或者final也会失效
- 声明式事务 本质是动态代理,static和final修饰的方法,无法被代理
-
自身调用问题
-
数据没有配置事务管理
-
不支持事务
-
异常捕获
-
异常类型或者数据错误
五十、事务的本质原理
- 事务管理类DataSourceTransactionManager本质就是一个切面类Aspect
- 当事务发生异常没有完全执行时,DataSourceTransactionManager的异常增强对事务进行了回滚rollback。当事务完全执行完毕,DataSourceTransactionManager的后置增强对事物进行了提交commit
五十一、微服务遵循的原则
- 单一职责原则:每个服务都有自己的具体业务职责
- 服务自治原则:服务之间互相解耦,独立开发独立运行
- 轻量级通讯原则:服务之前可以跨平台、轻量级通讯;例如restful风格、队列通讯等
- 粒度进化原则:随着业务的增加,对服务进行粒度划分
五十二、IOC容器基本流程
- 创建一些MAP结构,用于存储对象
- 进行配置文件的读取获取注解的解析,将需要的创建的 bean都封装成BeanDefind对象存储
- 容器将封装好的beanDefind对象通过反射进行实例化,完成对象的 实例化
- 进行对象的初始化操作,也就是给对象的属性赋值,也就是依赖注入,完成对象的初始化创建,存储在map结构中
- 通过容器来获取对象
- 提供对象的销毁操作
五十三、算法复杂度(时间、空间)
- o(1), o(n), o(logn), o(nlogn)
- 括号中的数字和运算:数据量的增大,耗时增大的倍数
- O(1):最优算法,无论数据的大小,耗时和空间都不变,都是直接找到当前元素
- hash算法:不考虑hash冲突,根据hash值可以直接找到
- o(n):当数据量增大一倍,耗时增大一倍
- o(n^2):数据量增大n倍,耗时增大n的二次方倍
- 经典的冒泡排序:要扫描n×n次,时间就是n的平方
- O(logn):以2为底数的log算法
- 当数据增大256倍:256的log值为8,即时间增加8倍;8个2相乘
- O(nlogn):n倍的以2为底数的log算法
- 当数据增大256倍:256的log值为8,即时间增加256*8倍
- O(1):最优算法,无论数据的大小,耗时和空间都不变,都是直接找到当前元素
五十四、线程内部细分
- 每一个线程都有一个本地方法栈:分为三部分
- 代码区:存放程序代码的地方,cpu指令调用,只读
- 静态数据区(全局):存放全局变量和静态变量
- 动态数据区:存放本地变量
五十五、redis线程模型
- IO模型使用多路线程复用,在Linux中是通过select/poll/epoll机制来实现的,类似netty的EventLoopGroup的线程全部设置为1
- 完全基于内存操作,时间复杂度为O(1)
- 单线程操作:避免了加锁、CPU线程切换
- redis6引入多线程:主要用于网络协议和网络数据读取
五十六、redis除了做缓存,还可以应用于哪些方面
- 排行榜,redis提供了zset数据类型,zset可以根据value自动按照顺序排序
- 地理位置:redis提供了geospatial,可以实现部分地理定位问题
- 计数器
- 分布式锁:单线程的特质,保证只允许一个线程占用所
- 通过nx控制只有key不存在的前提下才会设置
- 通过ex设置过期时间
- 分布式session:@EnableRedisHttpSession(maxInactiveIntervalInSeconds = AppConstants.API_TOKEN_TIMEOUT)
五十七、zookeeper如何实现的分布式锁
多个jvm同时在zk上创建临时节点 例如:root/node,假设返回的结果为nodeId,所有节点中nodeId最小的相当于获取到了锁,其他的节点从全部的节点中获取比自己小的一个节点,挂其自身线程并监控此节点,当此节点完成事务释放锁并删除自己的nodeId后,会激活监听的节点获取锁进入运行状态
五十八、说一下你对分布式理解是什么样的
- 分布式服务架构设计初衷是为了保证五个特点:高并发、高可用、高性能、可伸缩、可维护
- 水平切分 :同一个服务部署在不同服务器上
- 由一个统一的注册中心管理通过路由网关对外提供统一接口
- 可以任意伸缩
- 提高系统处理能力
- 避免单节点服务宕机风险
- 垂直切分:将同一个服务根据不同业务拆分成多个服务,减少服务qps
- 系统解耦,业务独立,便于管理
- 服务之间互相关联,需要分布式事务以及服务不可用处理
- 需要堆数据的准确性和一致性进行处理
- 分布式系统的设计原则
- cap原则
- 一致性:保证各节点的数据一致
- 可用性:保证各个节点都能处理请求
- 分区容错性:服务器与服务器之间可能存在的网络不同步的问题
- 服务器之间的网络问题,会导致一致性和可用性不能共存
- base原则
- 基本可用:服务节点存在不可预估状态,但是依然可以使用,存在性能和功能上的缺失
- 软状态:允许各个节点存在数据延迟
- 最终一致性:保证各节点
- cap原则
五十九、缓存与数据库双写时的数据一致性
- 先写入到DB,可以使用canal 订阅binlog日志,监听是否写入成功,然后将删除缓存的操作写入到MQ中,消费MQ的数据


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









