 PHP+MySQL千万级数据分表策略详解
PHP+MySQL千万级数据分表策略详解





 本文介绍了在MySQL分布式环境下,针对千万级数据的分表策略。强调分表需结合实际项目瓶颈,避免盲目操作。通过取模方式实现数据插入到不同分表,确保主表和分表的一致性。在修改、删除和查询时,直接操作分表,通过异步任务或队列保证数据同步,同时提醒分表并非最优解,需依据业务需求选择合适方案。
本文介绍了在MySQL分布式环境下,针对千万级数据的分表策略。强调分表需结合实际项目瓶颈,避免盲目操作。通过取模方式实现数据插入到不同分表,确保主表和分表的一致性。在修改、删除和查询时,直接操作分表,通过异步任务或队列保证数据同步,同时提醒分表并非最优解,需依据业务需求选择合适方案。
场景
一个金融公司有 500w 投资用户,每天充值投资 50w 笔,那么该公司每年将近有 1 亿条充值记录,那么我们改如何处理这个充值订单表的数据呢?难不成都放一张表里面,那万一哪天我让你去统计满足某个需求的记录,1 亿条数据里面检索你会累死 mysql 的!今天我们就来讲述一下如何去处理这种情况。
mysql 分布式之分表思路
分表不是随随便便就分表,必须要结合项目的实际情况,比如我们的项目的瓶颈在哪里,区区几千几万几十万或者几
百万的数据用分表那就是高射炮打蚊子了,不要盲目的分表!必须要达到一定的数量级,并且影响了我们的用户的访问速度,性能下降的情况下才能考虑去做分表处理!
画个简单的不能再简单的图吧
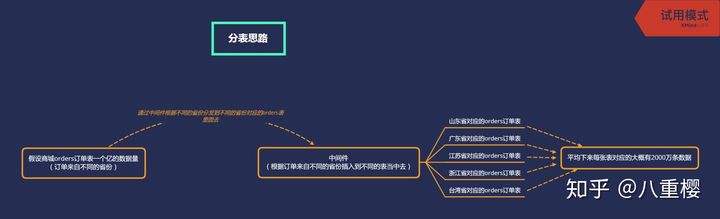
分表的思路就是如此简单,借助中间件可以根据不同省份的订单插入到不同省份对应的表当中去,当然实际当中还得要结合自身的业务来寻找制作这个中间件,不要照搬人家的逻辑思路!
mysql 分布式之分表实战(插入总表分然后取模分发到分表)
//伪代码
//假设用户数据入库 定为每天50w的数据量入库
//我们创建一张用户主表+两张用户分表 用户分表user0 用户分表user1
//首先所有用户数据入用户主表
$sql = insert into users(a,b,c) values($a,$b,$c);
$res = $model->query($sql);
if($res){
//获取user主表插入的最后一条sql的id
$insert_id = $model->getLastInsId();
//对刚才入库成功的记录的id取模 如果你是两种用户分表那么就%2如果是200张那么就%200
$d = $insert_id%2;
//取 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1009
1009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









