




 本文介绍了Spark Streaming的核心概念,包括流处理的本质、StreamingContext的创建与管理、DStreams的基本抽象,以及Input DStreams和Receivers的作用。Spark Streaming将连续的数据流转化为批次处理,借助DStream实现数据转换和计算,而Receivers则负责接收和存储数据。文章还提到了使用Spark Streaming需要注意的点,如本地模式下的线程配置。
本文介绍了Spark Streaming的核心概念,包括流处理的本质、StreamingContext的创建与管理、DStreams的基本抽象,以及Input DStreams和Receivers的作用。Spark Streaming将连续的数据流转化为批次处理,借助DStream实现数据转换和计算,而Receivers则负责接收和存储数据。文章还提到了使用Spark Streaming需要注意的点,如本地模式下的线程配置。
一、Spark Streaming流处理的本质
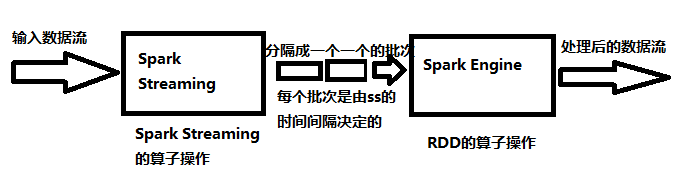
从源输入的数据(Flume、Kafka、hdfs、socket等)源源不断的流入Spark Streaming,Spark Streaming根据时间间隔切分数据,形成一个一个的批次,然后根据定义好的处理流程、算子操作,对每个批次的数据进行处理。处理的过程其实还是转换为Spark引擎来执行相应的任务,最后得到相对应的批次数据的结果。
二、StreamingContext
- Spark Streaming流处理的主入口
为了初始化spark Streaming程序,必须创建一个StreamingContext对象,因为这个是
所有Spark Streaming的主入口。
import org.apache.spark._
import org.apache.spark.streaming._
val sc = new SparkConf().setAppName("appName").setMaster(master)
val ssc = new StreamingContext(sc,Seconds(1))
// appName ,在spark UI展示的程序名字
// master,可以是yarn,mesos或者指定local[*],实际开发中不要在代码中指定master,而应该在spark-submit中指定
// Seconds,是批次的时间间隔,指定spark多久时间处理一次作业,实际要根据你的作业的需求和集群资源决定
- 确定了StreamingContext之后
- 定义输入源
- 定义streaming 应用计算和输出操作
- 开始接收数据和过程,通过代码
streamingContext.start() - 等待处理停止(或者作业报错),
streamingContext.awaitTermination() - 可以手动停止作业流程,
streamingContext.stop()
- 一些值得注意的点
- 一旦一个作业处理流程开始执行了,那这个作业流程不能添加或修改新的计算
- 一旦一个作业处理流程停止了,就不能再重启了;代码streamingContext.stop()后面不能跟start()代码。但是整个作业可以手动在启动一次
- 一个StreamingContext只能同时在一个JVM中存活
- 代码streamingContext.stop()也会把sparkContext对象也停止,如果想要只停止streamingContext,可以在stop()方法中调用sparkContext为false
- 一个sparkContext可以创建多个StreamingContext
三、DStreams
DStream(Discretized Stream)是Spark Streaming中最基本的抽象。它代表了一个持续不断的数据流。DStream只能从一个源的输入数据流创建,或者从一个DStream转换而来。
从更形象的说,一个DStreams就代表一系列的持续不断的RDD,DStream中的一个RDD就包含了seconds时间间隔的数据(在定义streamingContext设置的)。从而,任何对DStreams的操作算子,比如map/flatmat,底层都会翻译为对DStream中的每个RDD做相同的操作。而对RDD的算子操作,又会被spark core引擎执行。
四、Input DStreams和Receivers
Input DStreams表示从源接收的数据,在netcat wordCount的例子中,就是netcat server。每个 Input DStreams都会关联上一个Receiver(文件系统的Input DStreams除外)。Receivers接收数据并把数据存储在spark内存中以供后续spark计算使用。
Spark Streaming提供了两类内置的streaming源:
- 基础源:可以在SparkStreaming中直接使用的API,如文件系统和socket连接
- 高级源:Flume、Kafka、Kinesis,需要提供额外的工具类才可以使用
需要注意的点: - 当使用Spark Streaming的本地模式时,local不能是"local"、"local[1]"作为master 的url;因为receiver接收数据需要占用一个线程,处理数据也需要一个线程,所以1个线程时会出错。当不使用receiver时,如文件系统,就可以使用local[1],一个线程足够
- 使用DStream的算子操作和操作RDD的算子一样

















 2389
2389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









