







 本文详细介绍了浏览器从解析URL到渲染页面的过程,包括DNS解析、TCP连接建立、请求和数据传输,以及前端如何处理响应并渲染页面。通过理解这一流程,有助于深入理解Web工作原理。
本文详细介绍了浏览器从解析URL到渲染页面的过程,包括DNS解析、TCP连接建立、请求和数据传输,以及前端如何处理响应并渲染页面。通过理解这一流程,有助于深入理解Web工作原理。
最近面试经常会被问到一个问题,当你输入URL前端都干嘛了,当时心中各种“XXX”,我一个测试我需要知道前端的内容吗,但是面试终究是面试,而且干技术的,知道永远比不知道好。
1.解析URL(统一资源定位符):浏览器在输入URL后,浏览器首先拿到URL进行识别,抽取出对应域名字段(比如baidu.com)
PS:URL包括:传输协议(比如HTTP/HTTPS等)、服务器、域名、端口、虚拟目录、文件名、锚、参数
2.DNS解析(域名解析):
DNS实际上是一个域名和IP对应的数据库,先解释下为什么会有域名,机器相互之间只认IP,但是IP地址很难记住,所以就发明了域名,让域名与IP地址之间一一对应,它们之间的转换工作称为域名解析,域名解析需要由专门的域名解析服务器来完成,整个过程是自动进行的。
DNS解析时,一般经历几个步骤:
1.查询浏览器缓存:浏览器会缓存之前拿到的DNS 2-30分钟时间,如果没有就进入下一步
2.检查系统缓存:检查hosts文件,这个文件保存了一些以前访问过的网站的域名和IP的数据。它就像是一个本地的数据库。如果找到就可以直接获取目标主机的IP地址了。
3.检查路由器缓存:路由器有自己的DNS缓存,可能就包括了这在查询的内容
4.查询ISP DNS 缓存:ISP服务商DNS缓存(本地服务器缓存)那里可能有相关的内容
5. 递归查询:从根域名服务器到顶级域名服务器再到极限域名服务器依次搜索对应目标域名的IP。
通过以上的查找,就可以获取到域名对应的IP了。接下来就是向该IP地址定位的HTTP服务器发起TCP连接
3.浏览器与服务的建立TCP连接(熟称三次握手)
第一次握手:客户端向服务器端发送请求(SYN=1) 等待服务器确认;
第二次握手:服务器收到请求并确认,回复一个指令(SYN=1,ACK=1);
第三次握手:客户端收到服务器的回复指令并返回确认(ACK=1)。
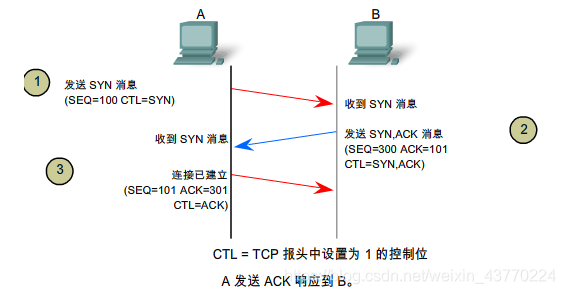
通过三次握手,建立了客户端和服务器之间的连接,现在可以请求和传输数据了。
4.请求和传输数据:
比如要通过get请求访问“http://www.dydh.org/”,通过抓包可以看到:
请求网址(url):http://www.dydh.org/
请求方法:GET/POST
远程地址:IP
状态码:200 OK
Http版本: HTTP/1.1
请求头: …
响应头: …
具体可以参考:https://blog.youkuaiyun.com/weixin_43770224/article/details/90105633
通过这样请求,和服务器的响应。可以将服务器上的目标文件传输到浏览器进行渲染。
5.前端得到对应的响应,开始渲染页面
客户端拿到服务器端传输来的文件,找到HTML和MIME文件,通过MIME文件,浏览器知道要用页面渲染引擎来处理HTML文件。
- 浏览器会解析html源码,然后创建一个 DOM树。
在DOM树中,每一个HTML标签都有一个对应的节点,并且每一个文本也都会有一个对应的文本节点。 - 浏览器解析CSS代码,计算出最终的样式数据,形成css对象模型CSSOM。
首先会忽略非法的CSS代码,之后按照浏览器默认设置——用户设置——外链样式——内联样式——HTML中的style样式顺序进行渲染。 - 利用DOM和CSSOM构建一个渲染树(rendering tree)。
渲染树和DOM树有点像,但是是有区别的。
DOM树完全和html标签一一对应,但是渲染树会忽略掉不需要渲染的元素,比如head、display:none的元素等。
而且一大段文本中的每一个行在渲染树中都是独立的一个节点。
渲染树中的每一个节点都存储有对应的css属性。 - 浏览器就根据渲染树直接把页面绘制到屏幕上
你若盛开,清风自来,我是顽童,一个活在底层的3C搬砖工程师!

















 4155
4155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









