




 本文围绕SQL展开,介绍了SQL基础,包括数据库语言(DML、DDL等)、数据类型、常用数据类型转换、集合查询和子查询;还阐述了SQL高级内容,如表复制语句、merge用法和递归查询;最后讲解了SQL分析函数,如over、rollup、cube等函数及排名函数。
本文围绕SQL展开,介绍了SQL基础,包括数据库语言(DML、DDL等)、数据类型、常用数据类型转换、集合查询和子查询;还阐述了SQL高级内容,如表复制语句、merge用法和递归查询;最后讲解了SQL分析函数,如over、rollup、cube等函数及排名函数。
Sql基础
数据库语言
数据操纵语言:DML (data manipulation language)
select insert update delete merge
数据定义语言:DDL(data definition language)
create alter drop truncate
事务控制语言:TCL (transaction control language)
commit rollback savepoint
数据控制语言:DCL (Data Control Language)
grant revoke
数据类型
Sql的数据类型:
- 字符型
char固定字符,最长2000个
varchar2可变长,最长4000最小值是1 - 数值型
number类型 - 日期型
date timestamp - 大对象型
clob(存储单字节数据,文本数据)
blob(存储二进制数据)
常用数据类型转换
SELECT TO_DATE('2015-08-19','YYYY-MM-DD')AS A_DAY FROM DUAL;
SELECT TO_CHAR(SYSDATE,'YYYY-MM-DD')AS TODAY FROM DUAL;
SELECT TO_TIMESTAMP('2015-08-19 17:40:32.11','YYYY-MM-DDHH24:MI:SS.FF') AS A_DAY FROM DUAL;
SELECT TO_CHAR(SYSTIMESTAMP, 'YYYY-MM-DD HH24:MI:SS.FF')AS TODAY FROM DUAL;
SELECT TO_NUMBER(REPLACE(TO_CHAR(SYSDATE, 'YYYY-MM-DD'),'-')) FROM DUAL;
集合查询
- 交叉连接(笛卡尔积)
- 等值、非等值连接
- 内连接
- 外连接(左外、右外、全连接)
- 自连接
- 自然连接(隐含链接条件,自动匹配链接自动)
- 集合运算
union(求合集重复记录只显示一次)
union all(求合集显示所有记录信息)
intersect(求交集,显示公共的数据部分)
minus(集合相减,哪个表在前面以哪个表的数据为主)
CREATE TABLE A(ID INT,NAME VARCHAR2(10));
CREATE TABLE B(ID INT,NAME VARCHAR2(10));
INSERT INTO A VALUES(1,'张三');
INSERT INTO A VALUES(2,'李四');
INSERT INTO B VALUES(3,'王五');
INSERT INTO B VALUES(2,'李四');
--intersect
SELECT * FROM A INTERSECT SELECT * FROM B;

--minus(A为主表)
SELECT * FROM A MINUS SELECT * FROM B;
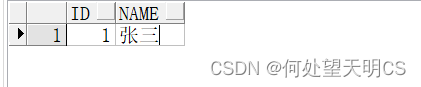
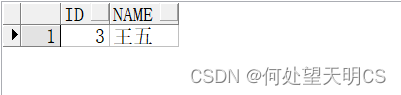
--minus(B为主表)
SELECT * FROM B MINUS SELECT * FROM A;
子查询
- 非关联子查询:主查询和子查询是相对独立的,唯一的,子查询查询结果和主查询进行比较
SELECT A.ENAME,A.SAL FROM EMP A WHERE A.DEPTNO=(SELECT B.DEPTNO FROM DEPTB WHERE B.LOC= 'NEW YORK'); - 关联子查询:主查询和子查询是产生关联关系的主查询的一个列字段代入到子查询中进行比较
SELECT A.DEPTNO,(SELECT B.LOC FROM DEPT B WHEREB.DEPTNO=A.DEPTNO) FROM EMP A; - IN和EXISTS,IN是做全表扫描,EXISTS是做是否存在,非全表扫描。
查询属于领导(大小领导都算)的员工:
SELECT * FROM employees a WHERE EXISTS (SELECT 1 FROM employees b WHERE a.employee_id=b.manager_id);
查询哪个部门不存在员工的部门信息:
SELECT * FROM departments t WHERE NOT EXISTS(SELECT 1 FROM employees b WHERE b.department_id=t.department_id);
sql高级
表复制语句
CT: create table <new table> as select * from <exists table>
要求目标表不存在,因为在插入时会自动创建表,并将查询表中指定字段数据复制到新建的表中
lS: insert into table2 (f1,f2,.….) select v1,v2,... from table1
要求目标表table2必须存在,由于目标表table2已经存在,所以我们除了插入源表table1的字段外,还可以插入常量
merge用法
merge into 表A
using 与表A产生关联字段值
on 和表A关联的条件
when matched then
...
when not matched then
...
递归查询
START WITH CONNECT BY。是oracle提供的递归查询(分层查询)函数,我们在进行递归遍历树形结构的时候可以使用。
start with(从某个节点id开始)
connect by prior (子节点id和父节点pid直接的关系需要)
形如:
SELECT *FROM EMP
START WITH EMPNO=7369
CONNECT BY PRIOR MGR=EMPNO;(父节点=子节点向上查询,反之向下查询)
可以添加WHERE条件限制。
可以指定多个起始节点查询。
可以进行排序。
sql分析函数
数据准备
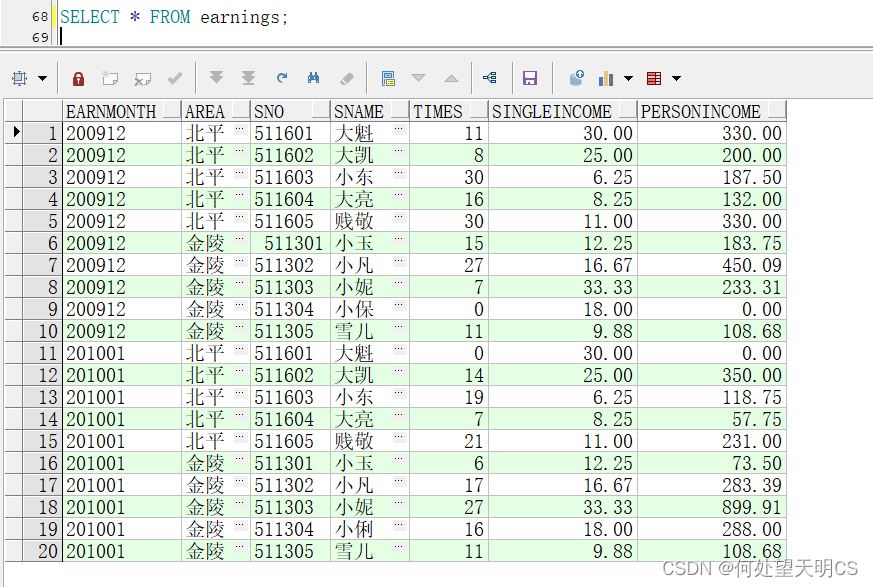
over (partition by…order by)函数
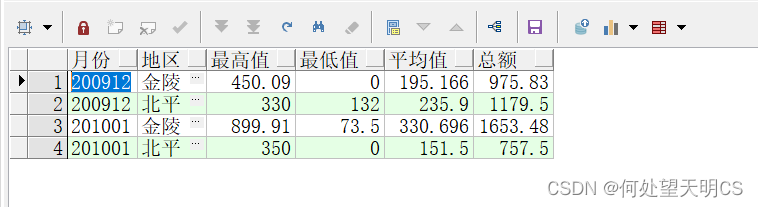
-- 分月份和地区统计最高值,最低值,平均值,总额,并按月份排序
SELECT DISTINCT EARNMONTH 月份,
AREA 地区,
MAX(PERSONINCOME) OVER(PARTITION BY EARNMONTH, AREA) 最高值,
MIN(PERSONINCOME) OVER(PARTITION BY EARNMONTH, AREA) 最低值,
AVG(PERSONINCOME) OVER(PARTITION BY EARNMONTH, AREA) 平均值,
SUM(PERSONINCOME) OVER(PARTITION BY EARNMONTH, AREA) 总额
FROM EARNINGS;
rollup函数
--按照月份,地区统计收入,分开统计,不同字段在前会有不同的结果
SELECT EARNMONTH, AREA, SUM(PERSONINCOME)
FROM EARNINGS
GROUP BY ROLLUP(EARNMONTH, AREA);
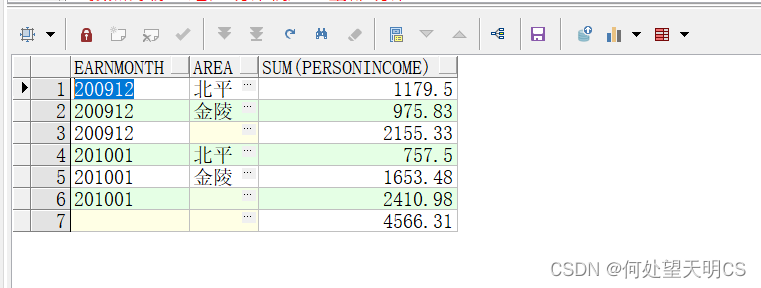
cube函数
--按照月份,地区统计收入,全部统计
SELECT EARNMONTH, AREA, SUM(PERSONINCOME)
FROM EARNINGS
GROUP BY CUBE(EARNMONTH, AREA)
ORDER BY EARNMONTH, AREA;
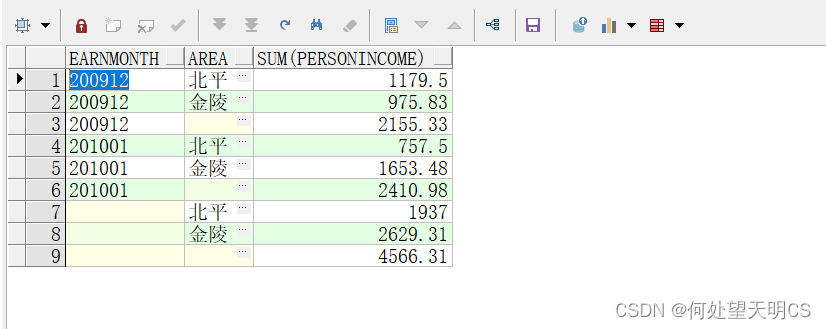
grouping函数
在以上例子中,是用rollup和cuba函数都会对结果集产生null,这时候可用grouping函数来确认该记录是由哪个字段得出来的
示例1:
--grouping函数用法,带一个参数,参数为字段名,如果是该字段就返回0,如果不是该字段结果返回1
SELECT EARNMONTH,grouping(EARNMONTH)
FROM EARNINGS
GROUP BY ROLLUP(EARNMONTH);
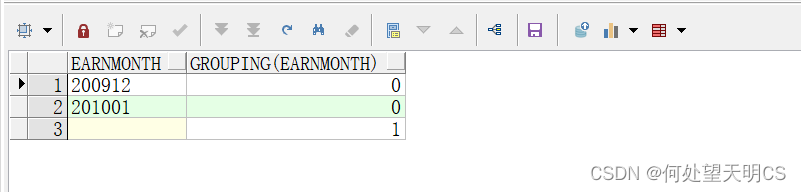
示例2:
SELECT EARNMONTH,
(CASE
WHEN ((GROUPING(AREA) = 1) AND (GROUPING(EARNMONTH) = 0)) THEN
'月份小计'
WHEN ((GROUPING(AREA) = 1) AND (GROUPING(EARNMONTH) = 1)) THEN
'总计'
ELSE
AREA
END) AREA,
SUM(PERSONINCOME)
FROM EARNINGS
GROUP BY ROLLUP(EARNMONTH, AREA);
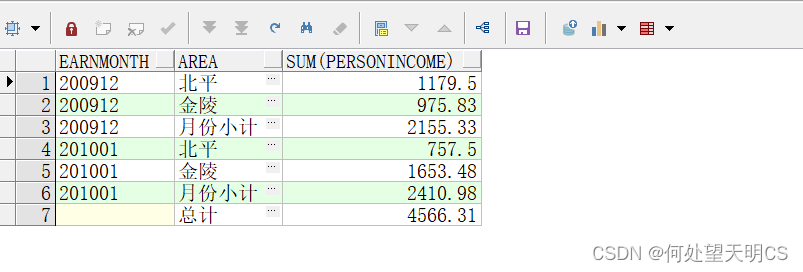
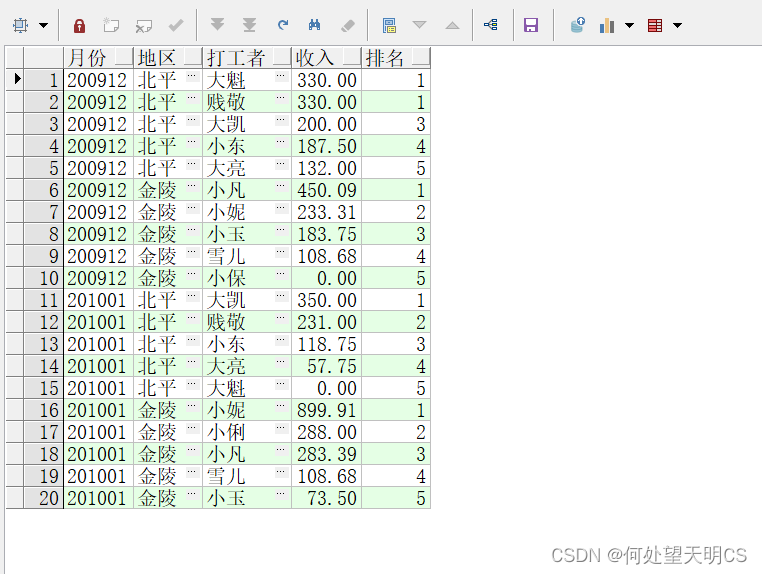
rank / dense_rank / row_number
rank:排名会有并列,产生跳跃排名
SELECT EARNMONTH 月份,
AREA 地区,
SNAME 打工者,
PERSONINCOME 收入,
RANK() OVER(PARTITION BY EARNMONTH, AREA ORDER BY PERSONINCOME DESC) 排名
FROM EARNINGS;
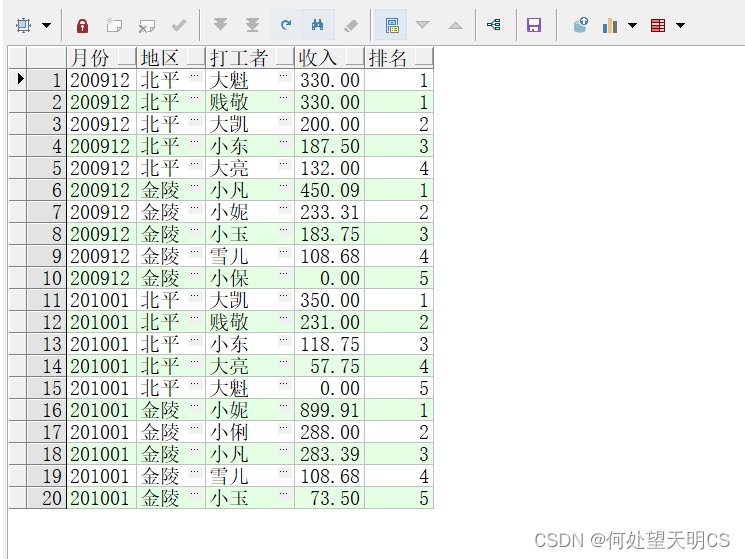
- dense_rank:排名会有并列,不产生跳跃排名
SELECT EARNMONTH 月份,
AREA 地区,
SNAME 打工者,
PERSONINCOME 收入,
DENSE_RANK() OVER(PARTITION BY EARNMONTH, AREA ORDER BY PERSONINCOME DESC) 排名
FROM EARNINGS;
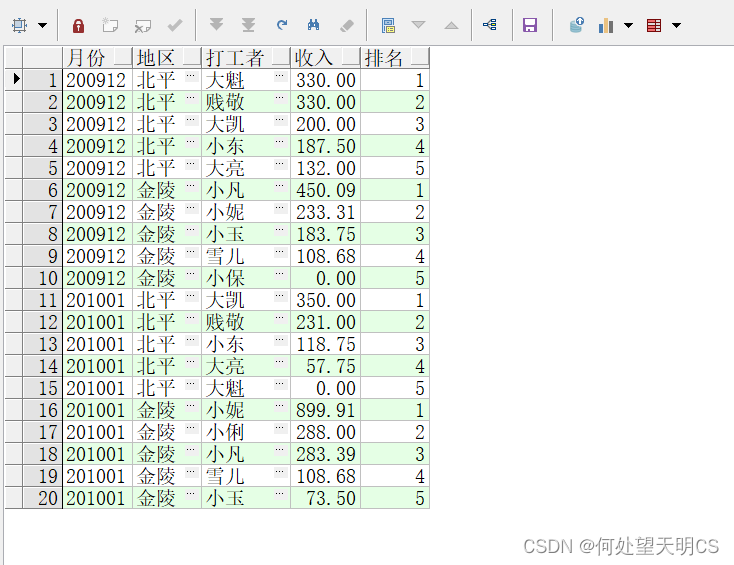
- row_number:排名没有并列,不产生跳跃排名
SELECT EARNMONTH 月份,
AREA 地区,
SNAME 打工者,
PERSONINCOME 收入,
ROW_NUMBER() OVER(PARTITION BY EARNMONTH, AREA ORDER BY PERSONINCOME DESC) 排名
FROM EARNINGS;

















 4202
4202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









