







 本文详细解析了HashMap的数据结构,包括其内部的Entry数组和链表结构,以及如何通过哈希函数定位元素。此外,还介绍了JDK1.8中HashMap的升级,即在链表长度超过8时转换为红黑树,以提高查找效率。
本文详细解析了HashMap的数据结构,包括其内部的Entry数组和链表结构,以及如何通过哈希函数定位元素。此外,还介绍了JDK1.8中HashMap的升级,即在链表长度超过8时转换为红黑树,以提高查找效率。
转自:
https://www.cnblogs.com/chengxiao/p/6059914.html
一、HashMap的结构:
我们知道,在数组中根据下标查找某个元素,一次定位就可以达到,哈希表利用了这种特性,它的主干就是数组。
HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。
我们平时遍历一张Map表时,最常用的方法便是
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue());
}
(这就是里面为什么会有Entry的原因)
Entry是HashMap中的一个静态内部类。代码如下
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;//存储指向下一个Entry的引用,单链表结构
int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
所以,HashMap的整体结构如下

简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;
如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;
对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。
所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
二、HashMap的哈希过程
我们知道,在数组中根据下标查找某个元素,一次定位就可以达到,哈希表利用了这种特性,哈希表的主干就是数组。
比如我们要新增或查找某个元素,我们通过把当前元素的关键字 通过某个函数映射到数组中的某个位置,通过数组下标一次定位就可完成操作。
存储位置 = f(关键字)
其中,这个函数f一般称为哈希函数,这个函数的设计好坏会直接影响到哈希表的优劣。举个例子,比如我们要在哈希表中执行插入操作:

查找操作同理,先通过哈希函数计算出实际存储地址,然后从数组中对应地址取出即可。

需要注意的是,新来的Entry节点采用的是“头插法”,而不是直接插入在链表的尾部,这是因为HashMap的发明者认为,新插入的节点被查找的可能性更大。
三、HashMap升级版结构
我知道了HashMap处理哈希冲突时通过链表的方式,但如果这种冲突很严重,链表里有很多的节点,遍历的效果就很差。
为了解决这种情况,JDK1.8的版本对HashMap进行了升级。
对于长链表,会转为红黑树的结构。
当链表的值超过8则会转红黑树
当链表的值小于6则会从红黑树转回链表
转自:https://www.sohu.com/a/327165642_753508

红黑树的结构如下:红黑树
为什么使用红黑树呢?
- 在链表长度大于8时,红黑树效率更高。
- 红黑树与AVL树相比,更加通用,因为AVL查找快但插入慢,红黑树查找插入都挺好
四、HashMap的扩容机制
扩容的触发条件
HashMap的扩容是由其负载因子(Load Factor)控制的。当HashMap中的元素数量(包括链表和树中的元素)超过当前容量 × 负载因子(默认是容量×0.75)时,HashMap会进行扩容。
比如,初始时容量为16,负载因子为0.75,那么当插入第13个元素(16 * 0.75 = 12)时,便会触发扩容。
一般在在 插入操作(put 或 putAll)时触发。
扩容的过程
容的过程包括以下几个步骤:
- 新数组的创建:扩容时,HashMap会将当前数组的容量扩展为原容量的2倍。比如,初始容量为16,扩容后的容量会变为32。
- 重新计算哈希值:由于扩容后数组长度发生了变化,所有已存在的键值对都需要重新计算哈希值,并找到其在新数组中的位置。
- 数据的迁移:将旧数组中的元素重新分配到新数组中,这个过程也称为rehash。在Java 8之前,迁移数据时是通过遍历链表实现的;而在Java 8之后,当链表长度超过一定阈值时,会将其转化为红黑树进行迁移,以提高性能。
数据的迁移rehash的过程
在 JDK 1.7 和 JDK 1.8 中,HashMap 在扩容时对链表的处理方式不同:
版本 插入方式 说明
- JDK 1.7 头插法,也就是新插入元素放在链表的第一个,扩容时链表顺序反转,可能导致 死循环(多线程环境下)。
- JDK 1.8 尾插法,也就是新插入元素放在链表的最后一个,扩容时保持链表顺序,解决死循环问题,但仍 非线程安全。
头插法的链表反转可能会导致死循环,具体演示过程如下:
单线程插入如下:

多线程插入如下:
这里假设有两个线程同时执行了put操作并引发了rehash,执行了transfer方法,并假设线程一进入transfer方法并执行完next = e.next后,因为线程调度所分配时间片用完而“暂停”,此时线程二完成了transfer方法的执行。此时线程一、线程二的状态分别如下。

接着线程1被唤醒,继续执行第一轮循环的剩余部分,我们会发现它最终执行结果如下,产生了死循环。线程一接下来要执行的是,将key为9的entry插入进去,再将key9的下一个插入进去,但因为线程二头插法,已经将key5插入进去,成为key9的下一个,所以就会形成循环。

HashMap在扩容时如何进行添加和查询
在单线程环境下,HashMap 的扩容过程不会影响 get 和 put 的正确性,因为扩容是原子性完成的(虽然分步骤执行,但不会并发干扰)。多线程环境下的扩容行为是线程不安全的。
我们能否让HashMap同步/线程安全?
HashMap本身是线程不安全的,但是可以通过下面的语句进行同步:
Map m = Collections.synchronizeMap(hashMap);
原文链接:https://blog.youkuaiyun.com/ye17186/article/details/88233505
注意:重写equals方法需同时重写hashCode方法
五、ConcurrentHashMap为什么能保证线程安全
ConcurrentHashMap相当于是HashMap的多线程版本,它的功能本质上和HashMap没什么区别。因为HashMap在并发操作的时候会出现各种问题,比如死循环问题、数据覆盖等问题。而这些问题,只要使用ConcurrentHashMap就可以完美地解决。那问题来到了,ConcurrentHashMap它是如何保证线程安全的呢?
这里要区分两个版本,1.7和1.8,两个版本使用的方式不一样
1、JDK1.7实现原理
首先,我们来看JDK 1.7中ConcurrentHashMap的底层结构,它基本延续了HashMap的设计,采用的是数组 加 链表的形式。和HashMap不同的是,ConcurrentHashMap中的数组设计 分为大数组Segment和小数组HashEntry,来着这张图。
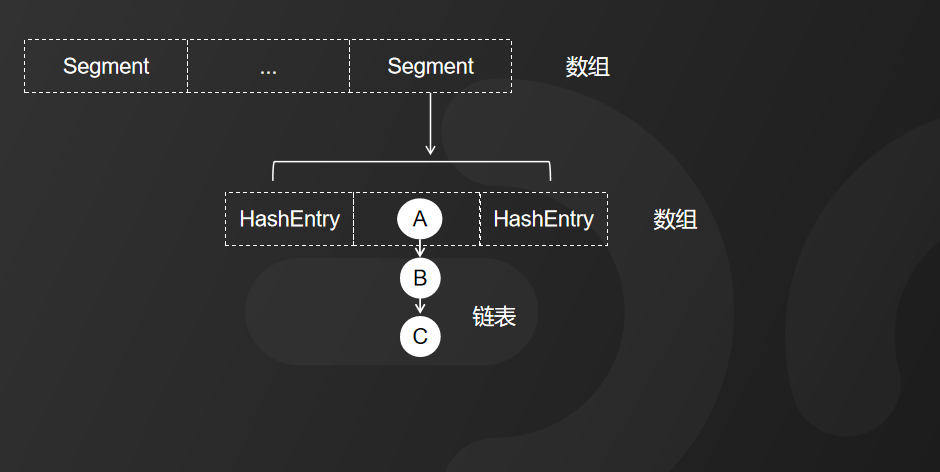
Segment本身是基于ReentrantLock重入锁实现的加锁和释放锁的操作,这样就能保证多个线程同时访问ConcurrentHashMap时,同一时间只能有一个线程能够操作相应的节点,这样就保证了ConcurrentHashMap的线程安全。
也就是说ConcurrentHashMap的线程安全是建立在Segment加锁的基础上的,所以,我们称它为分段锁或者片段锁,如图中所示。
2、JDK1.8实现原理
在JDK1.7中,ConcurrentHashMap虽然是线程安全的,但因为它的底层实现是数组加链表的形式,所以在数据比较多情况下,因为要遍历整个链表,会降低访问性能。所以,JDK1.8以后采用了数组 加 链表 加 红黑树的方式优化了ConcurrentHashMap的实现,具体实现如图所示。
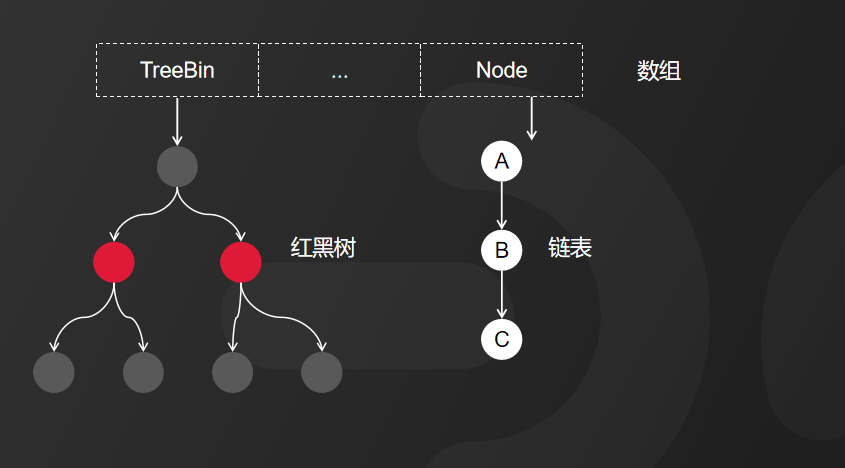
那在JDK 1.8中ConcurrentHashMap的源码是如何实现的呢?它主要是使用了CAS 加 volatile 或者 synchronized 的方式来保证线程安全。
- 添加元素时首先会判断容器是否为空,如果为空则使用 volatile + CAS 来初始化。
- 如果容器不为空,则根据存储的元素计算该位置是否为空。如果根据存储的元素计算结果为空则利用 CAS 设置该节点;
- 如果根据存储的元素计算为空不为空,则使用 synchronized 对头结点加锁,然后,遍历桶中的数据,并替换或新增节点到桶中,最后再判断是否需要转为红黑树。这样就能保证并发访问时的线程安全了。
ConcurrentHashMap 为什么不允许插入null
因为如果允许为null,就有一个二义性的问题:
- 有key,这个key的value是null
- 没有key,获取不到
在并发环境下,就会有歧义,在并发环境下,需要保证语义的严格准确,而 ConcurrentHashMap 是设计给并发环境的。
这是因为 HashMap 的设计是给单线程使用的,所以如果查询到了 null 值,我们可以通过 hashMap.containsKey(key) 的方法来区分这个 null 值到底是存入的 null?还是压根不存在的 null?
而 ConcurrentHashMap 就不一样了,因为 ConcurrentHashMap 使用的场景是多线程,所以它的情况更加复杂。 我们假设 ConcurrentHashMap 可以存入 null 值,有这样一个场景,现在有一个线程 A 调用了 concurrentHashMap.containsKey(key),我们期望返回的结果是 false,但在我们调用 concurrentHashMap.containsKey(key) 之后,未返回结果之前,线程 B 又调用了 concurrentHashMap.put(key,null) 存入了 null 值,那么线程 A 最终返回的结果就是 true 了,这个结果和我们之前预想的 false 完全不一样。
六、Redis的Hash和java的HashMap有啥区别
- HashMap是单机的,Redis的Hash是分布式的。
- HashMap是线程不安全的,Redis的Hash是线程安全的。
- 它们的扩容机制不一样,HashMap是一次性复制,RedisHash采用渐进式迁移。
下面详情说明一下他们的扩容机制:
- HashMap有一个初始容量(默认为16)和负载因子(默认为0.75)。当 HashMap 中的元素数量超过容量乘以负载因子时,就会触发扩容操作。扩容时,HashMap 的容量会增加到原来的两倍,并重新计算所有元素的哈希值,将它们重新分配到新的桶中(rehashing)。这个过程涉及到遍历整个表,因此是一个相对耗时的操作。
- Redis Hash 采用渐进式 Rehash:当 Hash 达到一定大小(例如超过 512 个元素)时,Redis 会开始将旧的哈希表中的数据逐步迁移到新的更大的哈希表中。这个迁移过程不会一次性完成,而是在每次执行命令时迁移一部分数据,直到所有数据都迁移完毕。这样可以避免因一次性大规模迁移而导致的阻塞问题。在渐进式 Rehash 期间,Redis 同时维护两个哈希表:旧表和新表。读写操作会同时在这两个表中进行,确保即使在 Rehash 过程中也不会影响服务的可用性。一旦所有的数据都迁移到新表,旧表会被释放,Rehash 结束。Redis 的 Hash 并没有固定的负载因子或容量限制,而是根据实际需求动态调整大小。这使得 Redis 的 Hash 更加灵活,适用于各种不同规模的数据集。
- ConCurrentHashMap采用渐进式迁移:不像 HashMap 那样一次性迁移所有数据,ConcurrentHashMap 采用渐进式的方式,在每次执行写操作时逐步迁移部分数据到新表中。转发节点:为了指示正在迁移中的状态,会在旧表中放置一个特殊的 ForwardingNode 节点,指向新表。这样可以确保读操作能够正确找到数据,即使它们已经被迁移到新表中。
https://blog.youkuaiyun.com/gupaoedu_tom/article/details/124449788
https://blog.youkuaiyun.com/hyc010110/article/details/142856587

















 1420
1420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









