



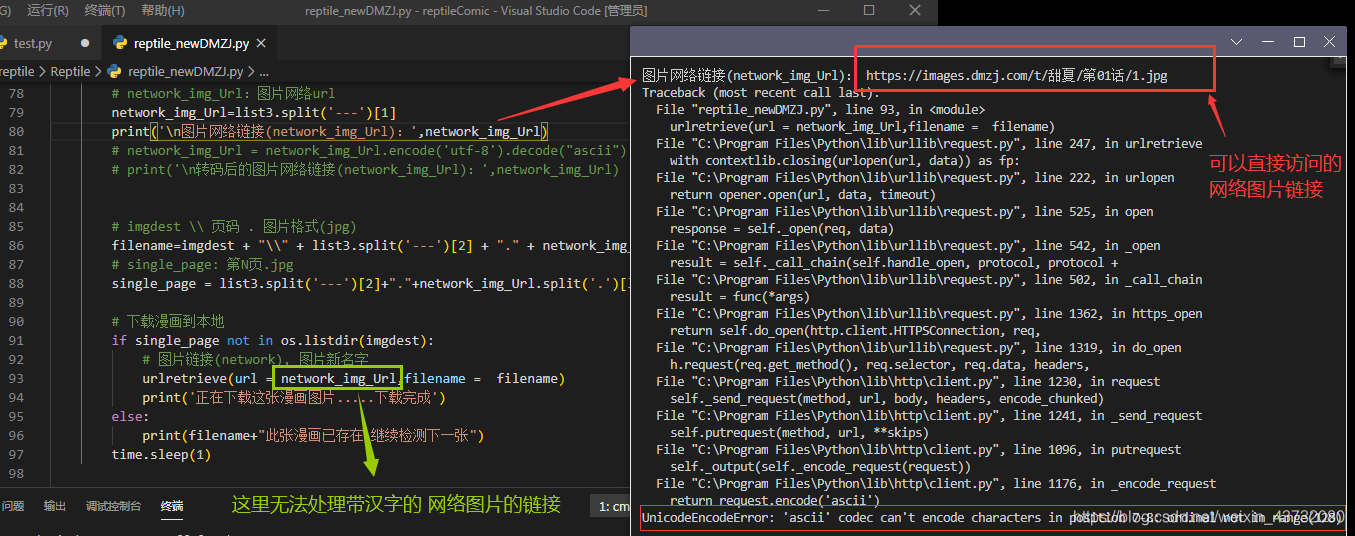
网络图片链接带有汉字,解决方法:
-
使用quote转为url编码(字符串形式)
转码会将 : 也进行转码,所以需要拆分进行转码
# 辅助的库 from urllib.request import quote # 转码前 # network_img_Url:带有汉字的网络图片链接: # https://images.dmzj.com/g/光电学院/2/1副本 副本.jpg network_img_Url=list3.split('---')[1] print('\n转码前:图片网络链接(network_img_Url):',network_img_Url) # 拆分转码: 将//后的转码,再和//前的合并 networkPic_1 = network_img_Url.split("//")[0] networkPic_2 = network_img_Url.split('//')[1] print('networkPic_1:',networkPic_1,'\nnetworkPic_2:',networkPic_2) # 转码后(合并) network_img_Url = networkPic_1 + "//" + quote(networkPic_2) print('\n转码后:图片网络链接(network_img_Url):',network_img_Url)就此便完成对带有汉字的网络图片的链接进行编码,之后便可以使用urlretrieve下载图片(√)
额外知识点
- 解码:使用unquote进行url解码(字符串形式)
涉及到多个异常处理方法,请参考:多异常:urllib.error.ContentTooShortError异常、urllib.error.HTTPError异常的解决方法


















 1845
1845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









