




 本文对比了关系型数据库和非关系型数据库的特点。关系型数据库易于理解、使用方便且易于维护,但在高并发读写、海量数据处理及扩展性方面存在瓶颈。非关系型数据库支持高性能并发读写,易于扩展,但通常不支持ACID特性。
本文对比了关系型数据库和非关系型数据库的特点。关系型数据库易于理解、使用方便且易于维护,但在高并发读写、海量数据处理及扩展性方面存在瓶颈。非关系型数据库支持高性能并发读写,易于扩展,但通常不支持ACID特性。
我们大概看一下传统数据库存储方式及非关系型数据库的存储方式
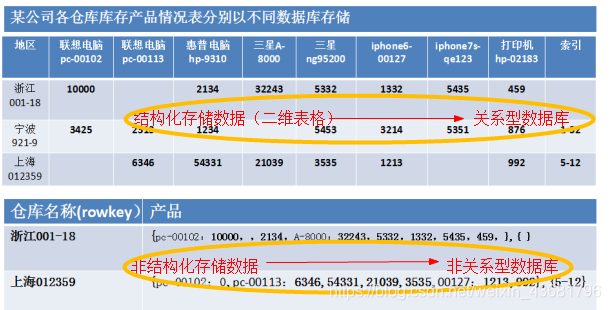
关系型数据库
简单来说关系型数据库就是一个二维表格,并且由其之间的联系所组成的一个数据组织。
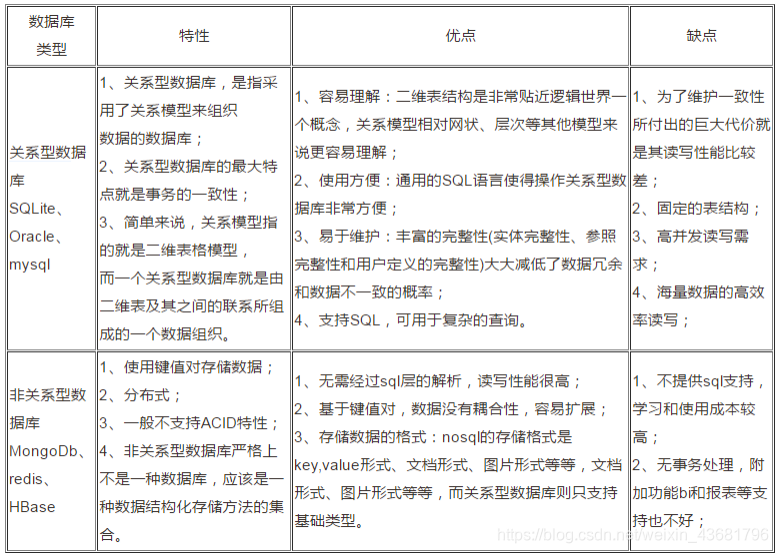
关系型数据库的三大优点:
容易理解:二维表结构是非常贴近逻辑世界的一个概念,关系模型相对网状、层次等其他模型来说更容易理解
使用方便:通用的SQL语言使得操作关系型数据库非常方便
易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率
关系型数据库的三大缺点(瓶颈):
高并发读写需求:网站的用户并发性非常高,往往达到每秒上万次读写请求,对于传统关系型数据库来说,硬盘I/O是一个很大的瓶颈,并且很难能做到数据的强一致性。
海量数据的读写性能低:网站每天产生的数据量是巨大的,对于数据库来说,在一张包含海量数据的表中查询,效率是非常低的。
扩展性和可用性差:在基于web的结构当中,数据库是最难(但是可以)进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,数据库却没有办法像web server和app server那样简单的通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供24小时不间断服务的网站来说,对数据库系统进行升级和扩展是非常痛苦的事情,往往需要停机维护和数据迁移。
PS:当然,对网站来说,关系型数据库的很多特性不再需要了,比如:事务一致性、读写实时性 。在关系型数据库中,导致性能欠佳的最主要原因是多表的关联查询,以及复杂的数据分析类型的复杂SQL报表查询。为了保证数据库的ACID特性,我们必须尽量按照其要求的范式进行设计,关系型数据库中的表都是存储一个格式化的数据结构。
非关系型数据库
非关系型数据库是以keyvalue键值对存储,且结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,这样就不会局限于固定的结构,可以减少一些时间和空间的开销。使用这种方式,用户可以根据需要去添加自己需要的字段,这样,为了获取用户的不同信息,不需要像关系型数据库中,要对多表进行关联查询。仅需要根据id取出相应的value就可以完成查询。
非关系型数据库特点:
一般不支持ACID特性,无需经过SQL解析,读写性能高
存储格式:key value,文档,图片等;数据没有耦合性,容易扩展。
但非关系型数据库不能够提供像SQL所提供的where这种对于字段属性值情况的查询。并且难以体现设计的完整性。他只适合存储一些较为简单的数据,对于需要进行较复杂查询的数据,SQL数据库显的更为合适
非关系型数据库分类,依据结构化方法以及应用场合的不同,主要分为以下几类:
··面向高性能并发读写的key-value数据库:Redis,Tokyo Cabinet,Flare
··面向海量数据访问的面向文档数据库:MongoDB以及CouchDB,可以在海量的数据中快速的查询数据
··面向可扩展性的分布式数据库:这类数据库想解决的问题就是传统数据库存在可扩展性上的缺陷,这类数据库可以适应数据量的增加以及数据结构的变化


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









