



 本文详细介绍使用Scrapy框架创建并运行爬虫的过程。通过实例网页的爬取演示了从项目搭建、爬虫生成到配置及运行的完整流程。
本文详细介绍使用Scrapy框架创建并运行爬虫的过程。通过实例网页的爬取演示了从项目搭建、爬虫生成到配置及运行的完整流程。
实例网页:https://python123.io/ws/demo.html

准备工作:在E盘中新建一个文件夹pyscrapyfile
步骤如下:
1.建立一个工程,工程名为python123demo
在命令行下进行E盘中的pyscrapyfile文件夹,输入命令
scrapy startproject python123demo
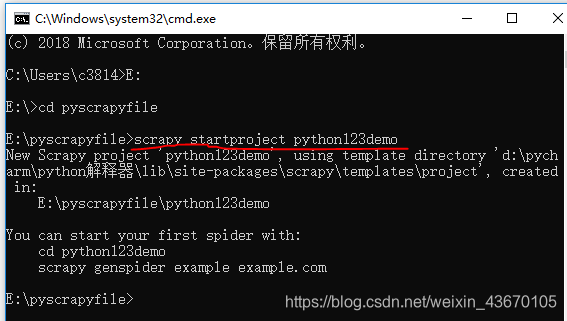
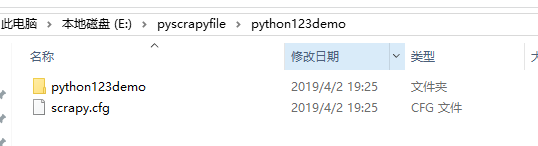
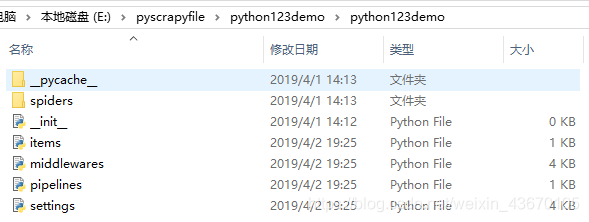
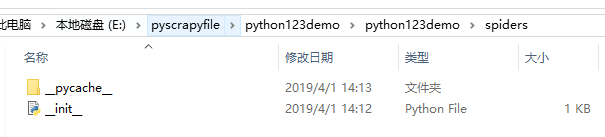
如上图,工程建立之后会出现这些文件与文件夹,下面简单介绍这些文件
python123demo/是最外层目录
scrapy.cfg 部署scrapy爬虫的配置文件
python123demo/文件夹scrapy框架的用户定义的python代码
init.py 初始化脚本 不需要修改
items.py Items代码模板
middlewares.py middlewares代码模板
pipelines.py pipelines代码
settings.py 爬虫配置文件
spiders/ 模板目录
init.py 初始文件 不需要修改
pycache.py 缓存目录,无需修改
第二步:产生一个爬虫
scrapy genspider demo python123.io
demo是爬虫名字,python123.io是要爬取的网站

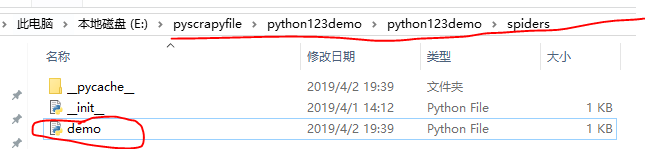
demo爬虫产生在spiders文件夹下
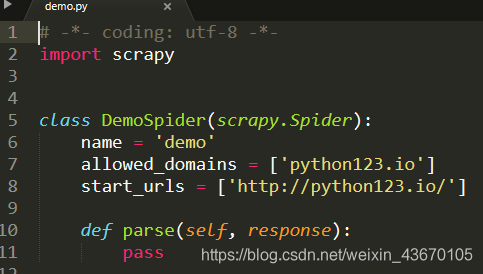
第三步:配置产生的爬虫文件
allowed_domains 表示只能爬取该url下的文件
start_urls修改为爬取得网页链接
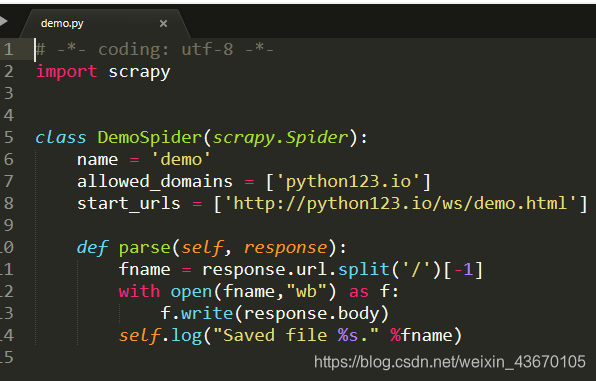
第四步:运行爬虫
scrapy crawl demo
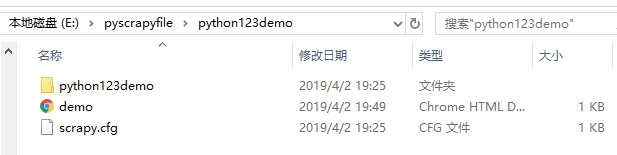
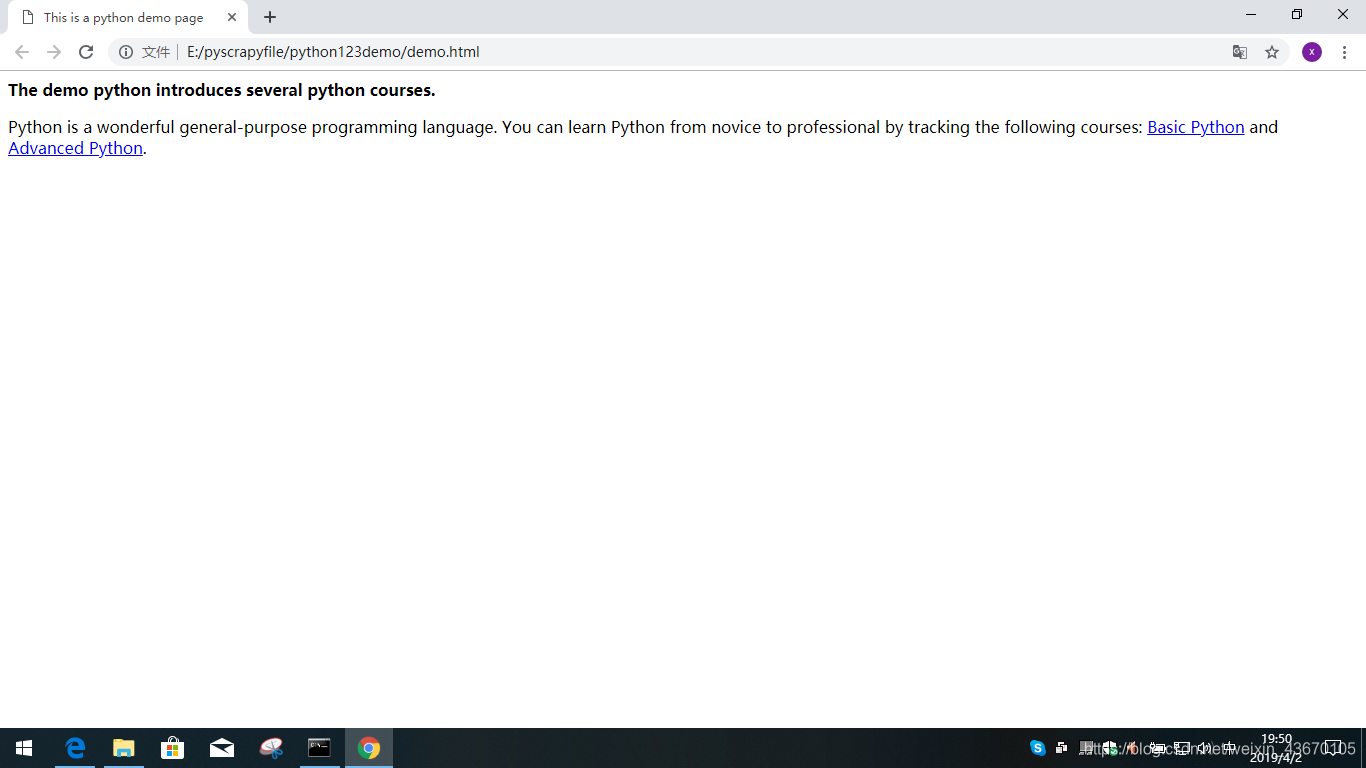
爬虫爬取成功!!

















 297
297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









