




 本文介绍了网络爬虫可能遇到的反爬措施,包括服务器负荷限制、产权法律风险和隐私保护。讲解了Web端如何通过User-Agent、Referer和Authorization等HTTP头部信息来限制非正常访问,并以Fiddler为例展示了抓包工具在识别这些信息中的作用。此外,还提及了JS动态加载和需要登录的情况,以及如何通过Fiddler辅助分析和应对反爬策略。
本文介绍了网络爬虫可能遇到的反爬措施,包括服务器负荷限制、产权法律风险和隐私保护。讲解了Web端如何通过User-Agent、Referer和Authorization等HTTP头部信息来限制非正常访问,并以Fiddler为例展示了抓包工具在识别这些信息中的作用。此外,还提及了JS动态加载和需要登录的情况,以及如何通过Fiddler辅助分析和应对反爬策略。
- 目录
- “盗亦有道 ”
- 反爬小知识
- 抓包工具Fiddler
- “盗亦有道”
- 爬虫尺寸

- 问题
- 限于编写者的水平与目的,给服务器带来具大负荷,“性能骚扰”
- 产权归属问题,获取数据后牟利有法律风险
- 隐私泄露
- Web端会对网络爬虫的限制
- 来源审查
检查来访HTTP协议 - 发布公告
告知看爬取策略,要求遵守。可在根目录下查看网站公告,如:
http://www.baidu.com/robots.txt
http://news.qq.com/robots.txt
- 来源审查
- 反爬
- 检查HTTP协议头的User-Agent域,只响应浏览器
# 模拟标准浏览器:mozilla/5.0;Chrom/10 >>> kv = {'user-agent':'Mozilla/5.0'} >>> url = 'https://www.amazon.cn/gp/product/B01M8L5z3Y' >>> r = requests.get(url, headers=kv) >>> r.request.headers {'user-agent': 'Mozilla/5.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'} >>> r.status_code 200 - SSL认证:客户端到服务器端的认证:
- 检查HTTP协议头的User-Agent域,只响应浏览器
8. ssl.SSLError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:777)
9. HTTPSConnectionPool(host='images.unsplash.com', port=443): Max retries exceeded with url: /photo-1560252118-b3ea5bc51cd1?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9 (Caused by SSLError(SSLError("bad handshake: Error([('SSL routines', 'tls_process_server_certificate', 'certificate verify failed')])")))
设置requests.get()方法的参数verify=False,默认设置为True,也就是执行认证。设置为False,绕过认证。
py3引入import ssl; ssl._create_default_https_context = ssl._create_unverified_context # 保持verify=True,同时修改认证内容
3. Others
如上图
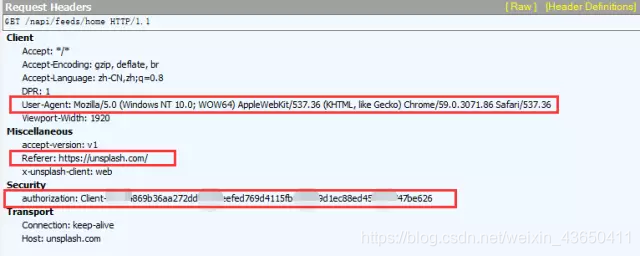
我截取了Fiddler的抓包信息,可以看到Requests
Headers里又很多参数,有Accept、Accept-Encoding、Accept-Language、DPR、User-Agent、Viewport-Width、accept-version、Referer、x-unsplash-client、authorization、Connection、Host。它们都是什么意思呢?专业的解释能说的太多,我挑重点:
User-Agent:这里面存放浏览器的信息。可以看到上图的参数值,它表示我是通过Windows的Chrome浏览器,访问的这个服务器。如果我们不设置这个参数,用Python程序直接发送GET请求,服务器接受到的User-Agent信息就会是一个包含python字样的User-Agent。如果后台设计者验证这个User-Agent参数是否合法,不让带Python字样的User-Agent访问,这样就起到了反爬虫的作用。这是一个最简单的,最常用的反爬虫手段。
Referer:这个参数也可以用于反爬虫,它表示这个请求是从哪发出的。可以看到我们通过浏览器访问网站,这个请求是从https://unsplash.com/,这个地址发出的。如果后台设计者,验证这个参数,对于不是从这个地址跳转过来的请求一律禁止访问,这样就也起到了反爬虫的作用。
authorization:这个参数是基于AAA模型中的身份验证信息允许访问一种资源的行为。在我们用浏览器访问的时候,服务器会为访问者分配这个用户ID。如果后台设计者,验证这个参数,对于没有用户ID的请求一律禁止访问,这样就又起到了反爬虫的作用。
Unsplash是根据哪个参数反爬虫的呢?根据我的测试,是authorization。我们只要通过程序手动添加这个参数,然后再发送GET请求。
-
JS动态加载

-
强制登陆才能访问 – s.taobao.com
- 辅助网页分析工具:强大的抓包工具就是Fiddler。
注意观察页反返回的Headers,这里包含了网页所需检查的信息,可以requests.headers进行比对来完成反爬。
附注:部分内容参考MOOCPython网络爬虫与信息提取

















 2533
2533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









