






论文题目:A Survey of Query Optimization in Large Language Models
论文链接:https://arxiv.org/pdf/2412.17558

核心内容
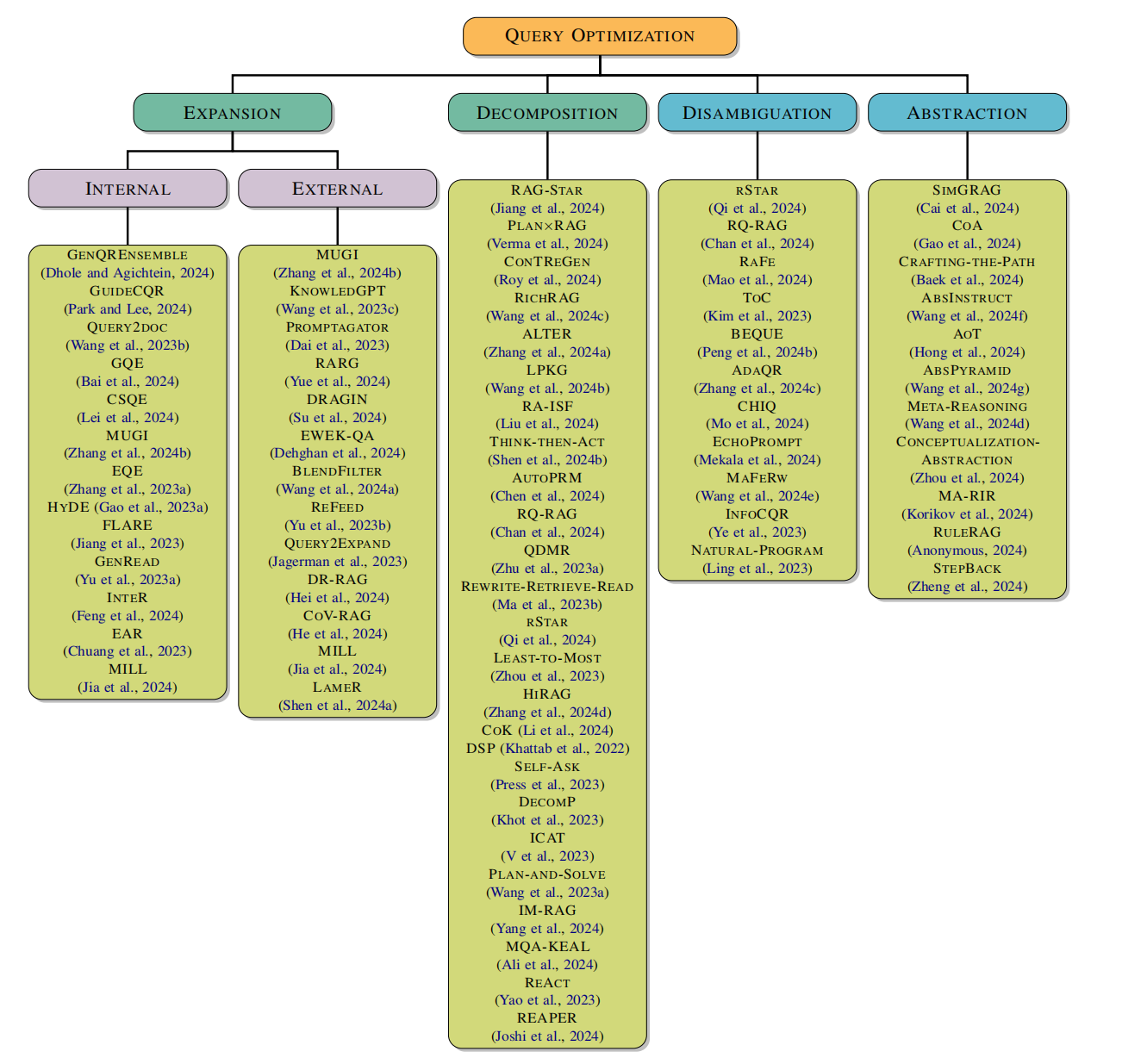
查询优化指的是旨在提高大型语言模型(LLMs)理解及回答查询的效率和质量的一系列技术,特别是在检索增强生成(RAG)场景中处理复杂查询时。通过改进用户的原始查询,这一过程带来了更加准确和上下文适当的响应,包括语义模糊、复杂需求以及查询与目标文档之间的相关性差异。在处理复杂或多面的问题的场景时,有效的查询优化需要深刻理解用户意图和查询背景。这篇文章总结了四个主要查询优化方法:扩展、消歧、分解和抽象
查询优化
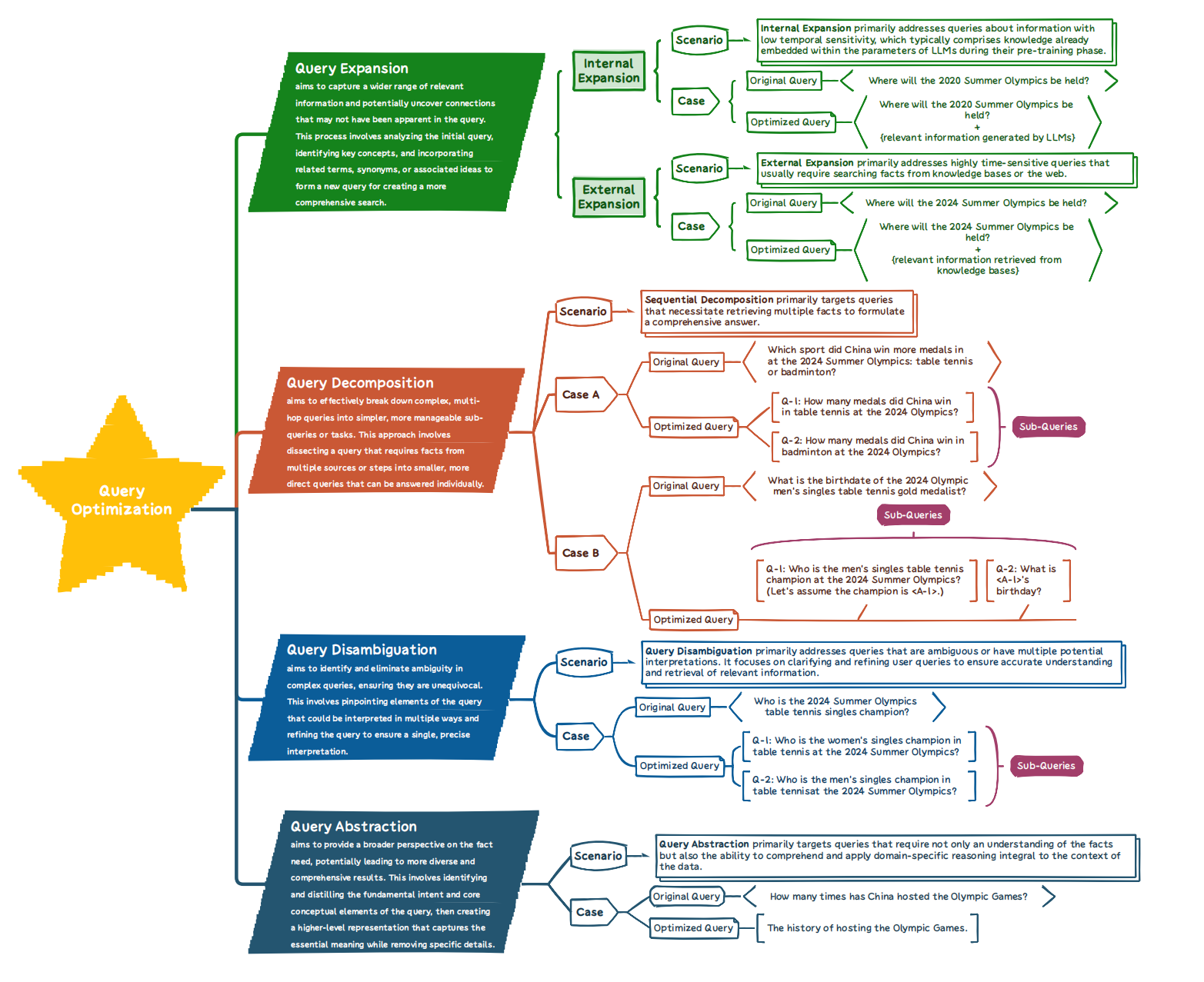
查询扩展
查询扩展技术对于提高检索增强生成的性能尤其重要,特别是在与 LLMs 集成时。根据不同的知识来源,我们可以将查询扩展大致分为内部扩展和外部扩展两类。
- 内部扩展:内部扩展专注于最大化利用原始查询或所用 LLM 中已有的信息,而不依赖于外部知识源。常见技术包括:
- QUERY2DOC:QUERY2DOC 引入了一种简单而有效的方法,用于改善稀疏和密集检索系统。通过少样本提示 LLMs 生成伪文档,原始查询被这些生成的文档所扩展。
- HYDE:HYDE 使用零样本提示与语言模型生成一个捕捉相关模式的假设文档,即使其中可能包含“幻觉”。然后,一个无监督对比编码器将该文档编码为嵌入向量,以识别语料库嵌入空间中的邻域。通过基于向量相似性检索类似的实际文档,HYDE 将生成的内容锚定到实际语料库,编码器的密集瓶颈过滤掉不准确的内容。
- 外部扩展:外部扩展是一种复杂的过程,通过无缝集成来自不同外部来源的相关信息,显著增强文档内容。这种方法通过增强文档语料的整体背景、深度和准确性,提升了内容的质量。扩展过程包括有策略地将权威事实、最新数据点和相关的上下文知识纳入其中,这些知识来源于广泛的外部数据集、知识库和精选的信息资源。
查询分解
对于复杂查询,直接使用原始查询进行搜索往往无法检索到足够的信息。对于大型语言模型(LLMs)而言,首先将这些查询分解为更简单、可回答的子查询,然后针对这些子组件搜索相关信息是至关重要的。通过整合这些子查询的响应,LLMs 能够构建对原始查询的全面回应。
原始查询:
“请告诉我2024年北京冬季奥运会的金牌得主,并列出他们赢得金牌的项目以及这些项目的比赛地点。”
查询分解步骤
子查询1: “2024年北京冬季奥运会的具体举办时间和地点是什么?”
目标是确认事件的存在及其基本详情,这有助于后续查询中的时间过滤和位置限定。
子查询2: “谁在2024年北京冬季奥运会上获得了金牌?”
这一步骤旨在收集所有金牌得主的信息,确保我们有完整的获奖者名单。
子查询3: 对于每位金牌得主,“他们在2024年北京冬季奥运会上赢得了哪些项目的金牌?”
针对每一位金牌得主,进一步细化查询以获取他们具体获胜的项目。
子查询4: 对于每个金牌项目,“该比赛在北京冬季奥运会期间的具体比赛地点是哪里?”
了解每个项目的确切比赛地点,可能需要针对不同项目进行分别查询。
主要技术包括:
- LEAST-TO-MOST 提示法:这种方法利用少样本提示首先将复杂问题分解为一系列较简单的子问题,然后按顺序解决它们。
- PLAN-AND-SOLVE 提示法:这种提示方法包括制定一个计划,将整个任务划分为较小的子任务,并按照该计划执行这些子任务。这种策略有助于提高解决复杂任务的效率和准确性。
- PLAN×RAG:PLAN×RAG 制定了表示为有向无环图(DAG)的全面推理计划。这个推理 DAG 将主要查询分解为相互关联的原子子查询,提供了计算结构,实现了子查询之间的高效信息共享。
查询消歧
对于具有多个可能答案的模糊查询,仅依赖原始查询进行信息检索是不充分的。为了提供完整且细致的响应,大型语言模型(LLMs)必须学会通过识别用户的意图来澄清查询,然后制定更针对性的搜索查询。在收集相关信息后,LLMs 可以提供详细和全面的回答。查询消歧主要分为两种类型的方法:一种是针对本身模糊的查询,另一种则是多轮对话中的查询,需要结合历史对话内容重写查询以实现消歧。
查询抽象
对于复杂的多跳查询,顺序分解可能无法产生准确的答案,甚至会使查询更加复杂。人类常常会退一步进行抽象,以达到高层次的原则来解决复杂查询,减少在中间推理步骤中出错的机会。主要技术包括:
- MA-RIR:MA-RIR 定义了一个查询方面(query aspect),即多方面查询的一个子段,代表查询内的不同主题或方面。这允许在复杂查询的不同方面进行更有针对性和有效的推理。
- META-REASONING:META-REASONING 致力于将每个查询中的实体和操作语义分解为通用的符号表示,从而提高推理效率和准确性。该方法使 LLM能够学习跨多种语义复杂场景的泛化推理模式。


















 1738
1738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









