




1. 前言
最近十年,Elasticsearch 已经成为了最受欢迎的开源检索引擎,其作为离线数仓、近线检索、B端检索的经典基建,已沉淀了大量的实践案例及优化总结。然而在高并发、高可用、大数据量的 C 端场景,目前可参考的资料并不多。因此,我们希望通过分享在外卖搜索场景下的优化实践,能为大家提供 Elasticsearch 优化思路上的一些借鉴。
美团在外卖搜索业务场景中大规模地使用了 Elasticsearch 作为底层检索引擎。其在过去几年很好地支持了外卖每天十亿以上的检索流量。然而随着供给与数据量的急剧增长,业务检索耗时与 CPU 负载也随之上涨。通过分析我们发现,当前检索的性能热点主要集中在倒排链的检索与合并流程中。针对这个问题,我们基于 Run-length Encoding(RLE)[1] 技术设计实现了一套高效的倒排索引,使倒排链合并时间(TP99)降低了 96%。我们将这一索引能力开发成了一款通用插件集成到 Elasticsearch 中,使得 Elasticsearch 的检索链路时延(TP99)降低了 84%。
2. 背景
当前,外卖搜索业务检索引擎主要为 Elasticsearch,其业务特点是具有较强的 Location Based Service(LBS) 依赖,即用户所能点餐的商家,是由商家配送范围决定的。对于每一个商家的配送范围,大多采用多组电子围栏进行配送距离的圈定,一个商家存在多组电子围栏,并且随着业务的变化会动态选择不同的配送范围,电子围栏示意图如下:
图1 电子围栏示意图
考虑到商家配送区域动态变更带来的问题,我们没有使用 Geo Polygon[2] 的方式进行检索,而是通过上游一组 R-tree 服务判定可配送的商家列表来进行外卖搜索。因此,LBS 场景下的一次商品检索,可以转化为如下的一次 Elasticsearch 搜索请求:
POST food/_search
{
"query": {
"bool": {
"must":{
"term": { "spu_name": { "value": "烤鸭"} }
//...
},
"filter":{
"terms": {
"wm_poi_id": [1,3,18,27,28,29,...,37465542] // 上万
}
}
}
}
//...
}
对于一个通用的检索引擎而言,Terms 检索非常高效,平均到每个 Term 查询耗时不到0.001 ms。因此在早期时,这一套架构和检索 DSL 可以很好地支持美团的搜索业务——耗时和资源开销尚在接受范围内。然而随着数据和供给的增长,一些供给丰富区域的附近可配送门店可以达到 20000~30000 家,这导致性能与资源问题逐渐凸显。这种万级别的 Terms 检索的性能与耗时已然无法忽略,仅仅这一句检索就需要 5~10 ms。
3. 挑战及问题
由于 Elasticsearch 在设计上针对海量的索引数据进行优化,在过去的 10 年间,逐步去除了内存支持索引的功能(例如 RAMDirectory 的删除)。为了能够实现超大规模候选集的检索,Elasticsearch/Lucene 对 Term 倒排链的查询流程设计了一套内存与磁盘共同处理的方案。
一次 Terms 检索的流程分为两步:分别检索单个 Term 的倒排链,多个 Term 的倒排链进行合并。
3.1 倒排链查询流程
- 从内存中的 Term Index 中获取该 Term 所在的 Block 在磁盘上的位置。
- 从磁盘中将该 Block 的 TermDictionary 读取进内存。
- 对倒排链存储格式的进行 Decode,生成可用于合并的倒排链。
可以看到,这一查询流程非常复杂且耗时,且各个阶段的复杂度都不容忽视。所有的 Term 在索引中有序存储,通过二分查找找到目标 Term。这个有序的 Term 列表就是 TermDictionary ,二分查找 Term 的时间复杂度为 O(logN) ,其中 N 是 Term 的总数量 。Lucene 采用 Finite State Transducer[3](FST)对 TermDictionary 进行编码构建 Term Index。FST 可对 Term 的公共前缀、公共后缀进行拆分保存,大大压缩了 TermDictionary 的体积,提高了内存效率,FST 的检索速度是 O(len(term)),其对于 M 个 Term 的检索复杂度为 O(M * len(term))。
3.2 倒排链合并流程
在经过上述的查询,检索出所有目标 Term 的 Posting List 后,需要对这些 Posting List 求并集(OR 操作)。在 Lucene 的开源实现中,其采用 Bitset 作为倒排链合并的容器,然后遍历所有倒排链中的每一个文档,将其加入 DocIdSet 中。
伪代码如下:
Input: termsEnum: 倒排表;termIterator:候选的term
Output: docIdSet : final docs set
for term in termIterator:
if termsEnum.seekExact(term) != null:
docs = read_disk() // 磁盘读取
docs = decode(docs) // 倒排链的decode流程
for doc in docs:
docIdSet.or(doc) //代码实现为DocIdSetBuilder.add。
end for
docIdSet.build()//合并,排序,最终生成DocIdSetBuilder,对应火焰图最后一段。
假设我们有 M 个 Term,每个 Term 对应倒排链的平均长度为 K,那么合并这 M 个倒排链的时间复杂度为:O(K * M + log(K * M))。 可以看出倒排链合并的时间复杂度与 Terms 的数量 M 呈线性相关。在我们的场景下,假设一个商家平均有一千个商品,一次搜索请求需要对一万个商家进行检索,那么最终需要合并一千万个商品,即循环执行一千万次,导致这一问题被放大至无法被忽略的程度。
我们也针对当前的系统做了大量的调研及分析,通过美团内部的 JVM Profile 系统得到 CPU 的火焰图,可以看到这一流程在 CPU 热点图中的反映也是如此:无论是查询倒排链、还是读取、合并倒排链都相当消耗资源,并且可以预见的是,在供给越来越多的情况下,这三个阶段的耗时还会持续增长。
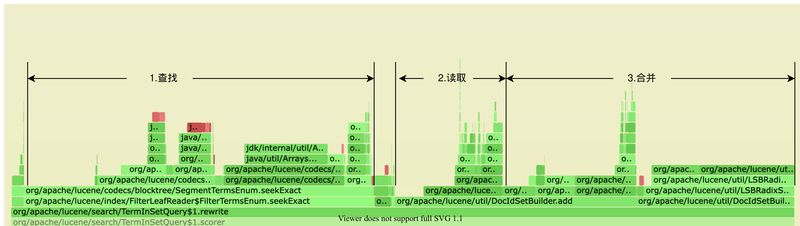
图2 profile 火焰图
可以明确,我们需要针对倒排链查询、倒排链合并这两个问题予以优化。
4. 技术探索与实践
4.1 倒排链查询优化
通常情况下,使用 FST 作为 Term 检索的数据结构,可以在内存开销和计算开销上取得一个很好的平衡,同时支持前缀检索、正则检索等多种多
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











