




 本文深入探讨XML的基础知识,包括语法、元素定义、属性、注释等内容,并详细讲解了DTD约束及其实现,同时介绍了JAXP的DOM和SAX解析方式,展示了如何使用JAXP进行XML的查询、添加、修改和删除操作。
本文深入探讨XML的基础知识,包括语法、元素定义、属性、注释等内容,并详细讲解了DTD约束及其实现,同时介绍了JAXP的DOM和SAX解析方式,展示了如何使用JAXP进行XML的查询、添加、修改和删除操作。
1,表单提交方式(重点)
*使用submit提交
</form>
......
<input type="submit"/>
</form>
*使用button提交表单
-代码:
//实现代码方法
function form1(){
//获取text文本输入
var form1 = document.getElementById("form1");
//设置action
form1.action ="hello.html";
//提交
form1.submit();
}
*使用超链接提交
<!--
超链接提交方法:
<a href="地址?表单name值=提交的值">超链接提交</a>
-->
-代码
<a href ="hello.html?username=123">超链接提交</a>
*事件:
*onclick:鼠标点击事件
*onchange:改变内容(一般和select一起使用)
*onfocus:得到焦点
*onblur:失去焦点
2,xml的简介
*eXtendsible Markup Language: 可扩展标记型语言
**标记型语言:HTML是标记型语言
-也是使用标签来操作
**可扩展:
-HTML里面的标签是固定的,每个标签都有特定的含义,例如:<h1><br/></h1>
-标签可以自己定义,可以写中文的标签,例如:<person></person>,<虎></虎>
*xml用途:
**html是用来显示数据,xml也可以显示数据(不是主要功能)
**xml主要功能,是为了存储数据
*xml是w3c组织发布的技术
*xml有两个版本1.0 和 1.1
-使用都是1.0版本
(因为1.1版本不能向下兼容,使用1.1版本开发的东西,在1.0版本下不能用)
3,xml的应用
*不同的系统之间传输数据
**qq之间数据的传输
**画图分析过程
*用来表示生活中有关系的数据
*经常用在配置文件
**比如现在连接数据库,肯定知道数据库的用户名和密码,数据名称
**如果修改数据库信息,不需要修改原代码,只要修改配置文件就可以了
4,xml的语法(重点)
(1)xml的文档声明(***)
*创建一个文件,后缀名是.xml
*如果写xml,第一步:必须要有一个文档声明(写了文档声明之后,表示写xml文件的内容)
**<?xml version="1.0" encoding="jbk"?>
****注意!!!****:文档声明必须写在 第一行第一列
属性:
-version:xml的版本1.0(使用),1.1
-encoding:xml编码gbk,utf-8,iso8859-1(不包含中文)
**注意!!!**:保存在磁盘上的文件编码要与声明的编码一致.
-standalone:是否需要依赖其它文件(yes/no)
如:<?xml version="1.0" standalone="yes"?>
(2)定义元素(标签)(***)
(3)定义属性(***)
(4)注释(***)
(5)特殊字符(***)
(6)CDATA区(了解)
(7)PI指令(了解)
5,xml的元素定义
*标签定义:
**标签定义有开始必须有结束:如<person></person>
**标签没有内容,可以在标签内结束;如<tag/>
**标签可以嵌套,必须要合理嵌套;
如:***合理嵌套<aa><bb></bb></aa>
***不合理嵌套<aa><bb></aa></bb>
**一个xml中,只能有一个根标签,其他标签都是这个标签下面的标签
**在xml中空格和换行都当成内容来解析
下面这两段代码含义是不一样的:
*<aa>1111</aa>
*<aa>
111
</aa>
**xml标签可以是中文
**xml标签中的名称规则
(1)xml代码区分大小写
<p> <P>:这两个标签是不一样的
(2)xml的标签不能以数字和下划线(_)开头
<2a> <_aa>:这样是不正确的
(3)xml的标签不能以xml,XML,Xml等开口
<xmla> <XmlB> <XMLC>:这些都是不正确的
(4)xml的标签下不能包括空格和冒号
<a b> <b:c> :这些都是不正确的
6,xml中属性的定义:
*html是标记型文档,可以有属性
*xml也是标记型文档,可以有属性
如:<person id1="aaa" id2="bbb"></person>
*属性的定义要求:
(1)一个标签可以有多个属性
<person id1="aaa" id2="bbb"></person>
(2)属性名称不能相同
<person id1="aaa" id1="bbb"></perosn>:这个是不正确的,不能有两个id1
(3)属性名称和属性值之间使用=,属性值使用引号包起来(可以是单引号,也可以是双引号)
(4)xml属性的命名规范和元素的命名规范一致
7,xml中的注释
*写法:<!--xml的注释-->
**注意的地方:
***注释不能嵌套
<!-- <!-- --> -->
<!-- <!-- <sex>nv</sex> --> -->
**注意:**注释也不能放在第一行,第一行第一列必须放文档声明
8,xml中的特殊字符
*如果想要在xml中现在a<b ,不能正常显示,因为把<当做标签
*如果就想要显示,需要对特殊字符 < 进行转转义
** < : <
** > : >
9,CDATA区
*可以解决多个字符都需要转义的操作,例如:if(a<b && b<c &&b>f){}
*把这些内容放到CDATA区里面,不需要转义了
**写法:
<![CDATA[ 内容 ]]>
-代码:
<![CDATA[ <b>if(a<b && b<c &&b>f){}</b>]]>
**把特殊字符,当作文本内容,而不是标签
10,PI指令(处理指令)
*可以在xml中设置样式
*写法:<?xml-styelsheet type="text/css" href="css的路径"?>
**注意!!!:**设置样式,只能对英文标签名称起作用,对于中文的标签名称不起作用的
11,xml的约束
*为什么需要约束?
**比如现在定义一个person的xml文件,只想要这个文件里面保存人的信息,比如:name age等,但是如果在xml文件中
写了一个标签<猫>,发现可以正常显示,因为符合语法规范,但是猫肯定不是人的信息,xml的标签是自定的,需要技术
来规定xml中只能出现的元素,这个时候需要约束.
*xml的约束的技术分为: dtd约束 和 schema约束 (看懂)
12,dtd的快速入门
*创建一个文件,后缀名是 .dtd
步骤:
(1)看xml中有多少个元素,有几个元素,在dtd文件中写几个<!ELEMENT>
(2)判断元素是简单元素还是复杂元素
-复杂元素:有子元素的元素
<!ELEMENT 元素名称 (子元素)>
-简单元素:没有子元素
<!ELEMENT 元素名称 (#PCDATA)>
(3)需要在xml文件中引入dtd文件
<!DOCTYPE 根元素名称 SYSTEM "dtd文件的路径">
*打开xml文件使用浏览器打开的,浏览器只负责校验xml的语法,不负责校验约束
*如果想要校验xml的约束,需要使用工具(如:myeclipse工具)
*打开myeclipse开发工具
**创建一个项目
**在项目的src目录下面创建一个xml文件和一个dtd文件
**当xml中引入dtd文件之后,比如只能出现name age,多写一个a,会提示出错
13,dtd的三种引入方式
(1)引入外部的dtd文件
<!DOCTYPE 根元素名称 SYSTEM "dtd文件路径">
(2)使用内部的dtd文件
<!DOCTYPE 根元素名称[
复杂元素:<!ElEMENT 根元素名称 (子元素名称)>
简单元素:<!ELEMENT 子元素名称 (#PCDATA)>
]>
如:<!DOCTYPE person [
<!ELEMENT person (name,age)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
]>
(3)使用外部的dtd文件(网络上的dtd文件)
<!DOCTYPE 根元素 PUBLIC "DTD名称" "DTD文档的URL">
-后面学到框架 struts2 使用配置文件 使用外部的dtd文件
**注意!!!:**注意空格和大小写
14,使用dtd定义元素
*语法: <!ELEMENT 元素名 约束>
*简单元素: 没有子元素的元素
<!ELEMENT name (#PADATA)>
** (#PCDATA):约束name是字符串类型
** EMPTY :元素为空(没有内容)
** ANY :任意
例如:
<?xml version="1.0" encoding="UTF-8"?>
<!--
引入外部dtd文件:
<!DOCTYPE person SYSTEM "使用dtd定义元素.dtd"> -->
<!-- 使用内部dtd文件 -->
<!DOCTYPE person[
<!ELEMENT person (name,age,sex)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age EMPTY>
<!ELEMENT sex ANY>
]>
<person>
<name>张三</name>
<age></age>
<sex>nv</sex>
</person>
*复杂元素:
<!ELEMENT person (name,age,sex,School)>
-子元素只能出现一次
*<ELEMENT 元素名称 (子元素)>
*表示子严肃出现的次数
'+' 一次或者多次
'?' 一次或者零次
'*' 零次或者多次
例如:<!ELEMENT person (name+,age?,sex*,School)>
*子元素直接用逗号进行隔开
**表示元素出现的顺序
例如:<!ELEMENT person (name,age,sex,School)>
*子元素直接使用|隔开
**表示元素只能出现其中的任意一个
如:<!ELEMENT person (name|age|sex|School)>
15,使用dtd定义属性
*语法: <!ATTLIST 元素名称
属性名称 属性类型 属性的约束
>
*属性类型:
-CDATA:字符串
如:<!ATTLIST birthday
ID1 CDATA #REQUIRED
>
-枚举:表示只能在一定范围内出现值,但是只能每次出现其中一个
**红绿灯效果:
**(aa|bb|cc)
如:<!ATTLIST age
ID2 (AA|BB|CC) #REQUIRED
>
ID:值只能是字母或者下划线开头
如:<!ATTLIST name
ID3 ID #REQUIRED
>
*属性的约束:
-#REQUIRED :属性必须存在
-#IMPLIED :属性可有可无
-#FIXED :表示一个固定值 #FIXED "AAA"
-属性的值必须是设置的这个固定值
如:<ATTLIST sex
ID5 CDATA #FIXED "abc"
>
-直接值 :
*不写属性,使用直接值
*写了属性,使用设置那个值
如:<!ATTLIST school
ID5 CDATA "www"
>
例如代码 :
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE person[
<!-- 定义标签约束 -->
<!ELEMENT person (name,age,sex,birthday,height,width)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age EMPTY>
<!ELEMENT sex ANY>
<!ELEMENT birthday (#PCDATA)>
<!ELEMENT height EMPTY>
<!ELEMENT width ANY>
<!-- 定义标签属性-->
<!-- dtd定义标签属性:属性名为property 类型为字符串(CDATA) 属性约束为(#REQUIRED) -->
<!ATTLIST name property1 CDATA #REQUIRED>
<!-- dtd定义标签属性:属性名为property 类型为枚举行型(aa|bb|cc) 属性约束为(#REQUIRED) -->
<!ATTLIST age property2 (aa|bb|cc) #REQUIRED>
<!-- dtd定义标签属性:属性名为property3 类型为ID 属性约束为(#REQUIRED) -->
<!ATTLIST sex property3 ID #REQUIRED>
<!-- dtd定义标签属性:属性名为property4 类型为CDATA 属性约束为(#IMPLIED) -->
<!ATTLIST birthday property4 CDATA #IMPLIED>
<!-- dtd定义标签属性:属性名为propery5 类型为CDATA 属性约束为(#FIXED) -->
<!ATTLIST height property5 CDATA #FIXED "aaa">
<!-- dtd定义标签属性:属性名为propery6 类型为CDATA 属性约束为(直接值) -->
<!ATTLIST width property6 CDATA "直接值">
]>
<person>
<name property1="AAAA">张三</name>
<age property2="aa"></age>
<!-- 属性约束为(#REQUIRED):属性必须存在 -->
<sex property3="_a">男</sex>
<!-- 属性约束为(IMPLIED):属性可有可无 -->
<birthday>生日</birthday>
<!-- 属性约束为(FIXED):固定一个值,属性的值必须是设置这个固定值 -->
<height property5="aaa"></height>
<!-- 属性约束为(直接值):不写属性,使用直接值;写了属性,使用设置的那个值 -->
<width property6="直接值"></width>
</person>
16,实体的定义
*语法:<!ENTITY 实体名称 "实体的值">
**<!ENTITY TEST "HAHAHEHE">
**使用实体 &实体名称; 比如 &TEST;
**注意:**定义实体需要写在内部dtd里面,如果写在外部dtd里面,在某些浏览器下,内容得不到
17,xml的解析的简介(写到Java代码)(重点)
*xml是标记型文档
*js使用dom解析标记型文档
-根据HTML的层级结构,在内存中分配一个树形结构,把html的标签,属性和文本都封装成对象
-document对象,element对象,属性对象,文本对象,Node节点对象
*xml的解析方式(技术):dom 和 sax
**画图分析使用dom和sax分析xml过程
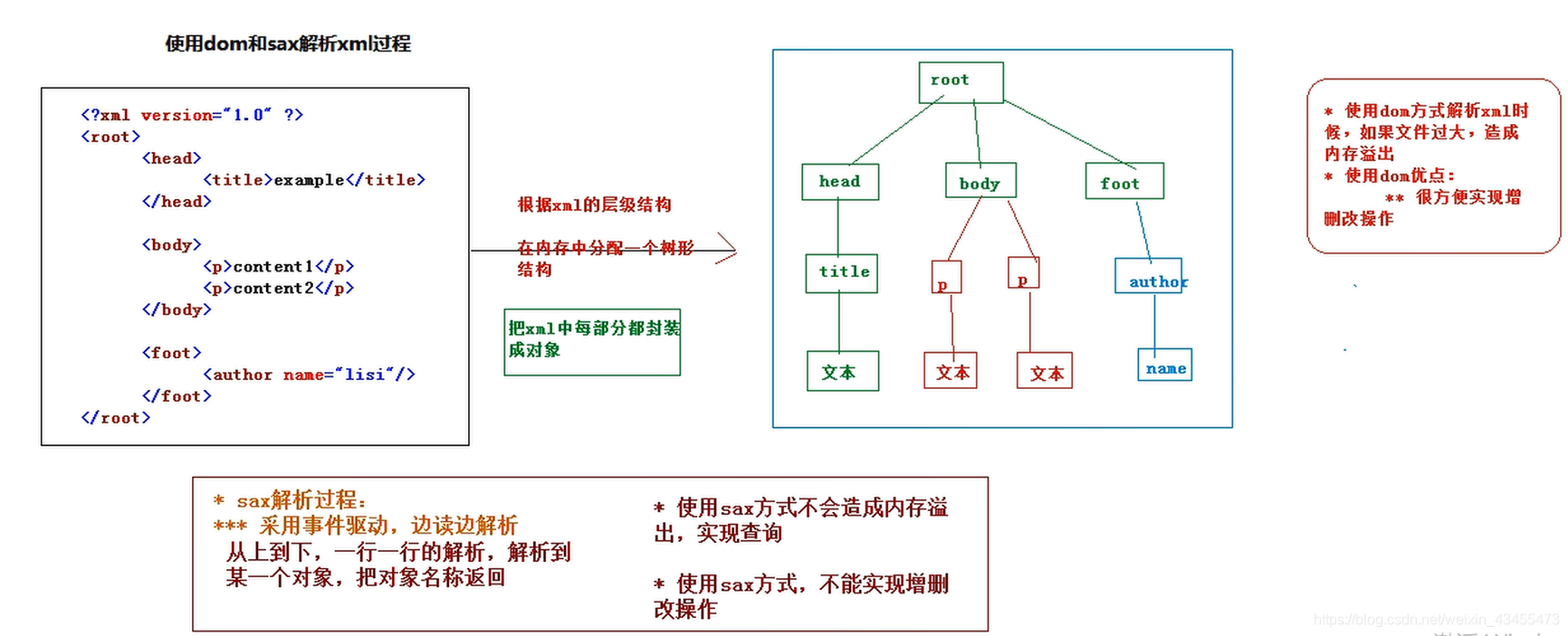
**dom方式分析
*根据xml的层级结构在内容中分配一个树形结构,把xml的标签,属性和文本都封装成对象
*缺点;如果文件过大,造成内存溢出
*优点:很方便实现增删改操作
**sax方式解析
*采用事件驱动,边读边解析
-从上到下,一行一行的解析,解析到某一个对象,返回对象名称
*缺点:不能实现增删改操作
*优点:如果文件过大不会造成内存溢出,方便实现查询操作
18,jaxp的api的查看
*jaxp是javase的一部分
*jaxp解析器在jdk的javax.xml.parsers包里面
**四个类:分别是针对dom和sax解析使用的类
***dom:
DocumentBuilder :解析器类
-这个类是一个抽象类,不能new
此类的实例可以从DocumentBuilderFactory.newDocumentBuilder()方法获取
-一个方法,可以解析xml parse("xml路径") 返回是Document 整个文档
-返回的document是一个接口,父节点是Node,如果在document里面找不到想要的方法
则到Node里面去找
-在document里面的方法
getElementsByTagName(String tagname)
--这个方法可以得到标签
--返回集合NodeList
createElement(String tagname)
--创建标签
-createTextNode(String data)
--创建文本
appendChild(Node newChild)
-把文本添加到标签下面
removerChild(Node oldChild)
-删除节点
getParentNode()
-获取父节点
NodeList
-getLength() 得到集合的长度
-item(int index) 下标取到具体的值
for(int i=0;i<list.getLength();i++){
list.item(i);
}
DocumentBuilderFactory:解析器工厂
-这个类是一个抽象类,不能new
newInstance()获取DocuementBulilderFactory 的实例.
***sax:
SAXParser:解析器类
SAXParseFactory:解析器工厂
19,使用jaxp实现查询操作
*查询xml中所有的name元素的值
*步骤
**查询所有name元素的值
/*
* 1,创建解析器工厂
* DocumentBuilderFactoryFactory.newInstance();
* 2,根据解析器工厂创建解析器
* builderFactory.newDocumentBuilder();
* 3,解析xml返回document
* Document document = builder.parse("src/person.xml");
* 4,得到所有的name元素
* 使用document.getElementsByTagName("name");
* 5,返回集合,集合遍历,得到每一个name元素
* */
**查询xml中第一个name元素的值
步骤:
/*
1,创建解析器工厂
*2,根据解析器工厂创建解析器
*3,解析xml,返回document
*
*4,得到所有name元素
*5,使用返回集合,里面方法item,下标获取具体的元素
* NodeList.item(下标); 集合下标从0开始
* 6,得到具体的值 ,使用getTextContent方法
*/
20,是用jaxp添加节点
*在第一个p1下面(末尾)添加<sex>nv<sex>
*步骤:
/**
1,创建解析工厂
2,根据解析器工厂创建解析器
3,解析xml,返回document
4,得到第一个p1
-得到所有p1,使用item方法下标得到
5,创建sex标签,createElement
6,创建文本 createTextNode
7,把文本添加到sex下面appendChild
8,把sex添加到第一个p1下面 appendChild
9,回写xml
**/
回写:
//回写
TransformerFactory tranformerFactory = TransformerFactory.newInstance();
Transformer transformer = tranformerFactory.newTransformer();
transformer.transform(new DOMSource(document), new StreamResult("src/person.xml"));
21,使用jaxp修改节点
*修改一个p1下面的sex内容nan
*步骤:
/*
* 1,创建解析器工厂
* 2,根据解析器工厂创建解析器
* 3,解析xml,返回document
* 4,得到sex item方法
* 5,修改sex里面的值
**setTextContent()方法
* 6,回写xml
*/
22,使用jaxp删除节点
*删除<sex>nan</sex>节点
*步骤:
/*
* 1,创建解析器工厂
* 2,根据解析器工厂创建解析器
* 3,解析xml,返回document
* 4,获取sex元素
* 5,获取sex的父节点,使用getParentNode();方法
* 6,删除使用父节点删除 removeChild();方法
* 7,回写xml
* */
23,使用jaxp遍历节点
*把xml中的所有元素名称打印出来
/*
* 1,创建解析器工厂
* 2,根据解析器工厂创建解析器
* 3,解析xml,返回document
*
* ==使用递归实现==
* 4,得到根结点
* 5,得到根节点子节点
* 6,得到根节点子节点的子节点
* */
*遍历的方法
//递归遍历的方法
public static void list1(Node node){
//判断是元素类型的时候才打印
if(node.getNodeType()==Node.ELEMENT_NODE){
System.out.println(node.getNodeName());
}
//获取一层子节点
NodeList list = node.getChildNodes();
//遍历子节点
for(int i = 0;i<list.getLength();i++){
//获取没每一个子节点
Node node1 = list.item(i);
list1(node1);
}
}

















 1122
1122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









