




在做商城类项目的 UI 自动化测试时,我们经常需要验证价格、标签等信息是否正确。
最近我在测试商品详情页时,遇到了一个有趣的问题:页面上明明有“¥”符号,但用 Selenium 获取元素文本时却拿不到。
🧩 问题背景
HTML 代码如下:

页面上实际显示为:
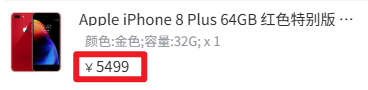
但执行以下定位时,输出却只有数字部分:
price_text = driver.find_element(By.CSS_SELECTOR, ".price span").text
print(price_text) # 输出: 5499
而预期应该是:¥5499
🕵️ 原因分析
经过排查,发现“¥”这个符号并不在 HTML 中,而是由 CSS 的 ::before 伪元素生成的。
查看样式表后发现:
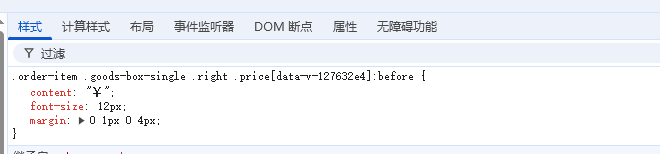
伪元素(::before、::after)是纯样式生成的内容,不属于真实的 DOM 节点。
因此,Selenium 在通过 .text 或 .get_attribute(“textContent”) 获取文本时,不会返回伪元素内容。
⚙️ 解决方案
✅ 方案一:通过 JavaScript 获取伪元素的 content 值
可以让 Selenium 执行 JS,从计算样式中读取伪元素内容:
price_element = driver.find_element(By.CSS_SELECTOR, ".price")
symbol = driver.execute_script(
'return window.getComputedStyle(arguments[0], "::before").getPropertyValue("content");',
price_element
)
symbol = symbol.strip('"') # 去掉引号
price_value = price_element.text
full_price = f"{symbol}{price_value}"
print(full_price) # 输出: ¥5499
这种方法最稳定,适用于所有浏览器。
✅ 方案二:后端或测试辅助接口返回完整价格(推荐在业务层优化)
如果页面的伪元素是用于展示货币符号等固定内容,可以建议前端直接在 HTML 中渲染出来,例如:
<uni-text class="price">¥<span>5499</span></uni-text>
这样不仅方便 UI 测试,也更利于爬虫、辅助功能(如屏幕阅读器)。
🧠 补充:伪元素内容的限制
| 特性 | 是否可被 DOM 访问 | 是否可被 Selenium .text 获取 |
|---|---|---|
| 普通文本节点 | ✅ 是 | ✅ 是 |
| ::before / ::after | ❌ 否 | ❌ 否 |
| 隐藏元素(display:none) | ✅ 是 | ❌ 否 |
| 动态渲染(Vue/React 数据绑定) | ✅ 是 | ✅ 是 |
🚀 总结
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 页面显示有“¥”但 .text 拿不到 | 是由 CSS ::before 生成的伪元素 | 使用 JavaScript 获取伪元素内容,或让前端在 HTML 中渲染真实符号 |
在 UI 自动化测试中,如果你发现“肉眼看到的文字”获取不到,很可能是伪元素、图片字体(iconfont)或动态绘制的内容导致的。
这类问题只要掌握“DOM 与样式的边界”,就能轻松定位。
✅ 推荐做法:
- 测试中临时用 JS 获取;
- 开发中建议避免业务关键信息放在伪元素中。

















 1024
1024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









