




 本文深入探讨Python中的类装饰器、元类、垃圾回收机制、内建属性与函数等高级特性,解析其工作原理及应用场景,适合进阶学习。
本文深入探讨Python中的类装饰器、元类、垃圾回收机制、内建属性与函数等高级特性,解析其工作原理及应用场景,适合进阶学习。
我若将死,给孩子留遗言,只留一句话:Repetition is the mother of all learning重复是学习之母。他们将来长大,学知识,技巧、爱情、事业、交流....倘若懂得行动的力量,不怕重复,不怕犯错误,那就大有希望靠近幸福了。
---id:实验楼扫地阿姨
目录
0x01 元类(之后jquery中的orm映射的原理就是用这个做的)
0x00 类装饰器
所谓类装饰器,即用类来装饰函数。先理解如下代码:
class Test(object):
def __call__(self):
print("---test---")
t = Test()
t() #对象小括号默认会调用__call__方法那么如何用类来装饰函数呢?
class Test(object):
def __init__(self,func):
print("---初始化----")
print("func name is %s"%func)
self.__func = func
def __call__(self):
print("---装饰器中的功能---")
self.__func()
@Test #相当于在函数之后 添加了一句 test = Test(test)
def test():
print("---test---")
test() #当如此这般调用test的时候会自动调用__call__方法,我们可以在__call__方法中做文章,来扩展原函数从上面的代码中可以看出,类装饰器实质上将 原函数扩展成了一个 对象。
0x01 元类(之后jquery中的orm映射的原理就是用这个做的)
python中类也是一个对象,程序会执行类中每一行代码
class Person(object):
num = 0
print("---test---")
def __init__(self):
self.name ="abc"调用该程序,会看到print语句被执行了。
动态创建类:(了解)
因为类也是对象,所以可以在运行时动态创建他们,就像其他任何对象一样
def choose_class(name):
if name == 'foo':
class Foo(object):
pass
return Foo
else:
class Bar(object):
pass
return Bar
MyClass = choose_class('foo')
laowang = MyClass()使用type创建类:
type(xxx) 返回xxx的类,但是type还有一种完全不同的功能,那就是动态创建类。
type可以接受一个类的描述作为参数,然后返回一个类。(相当于C++中的函数重载,但是函数重载 最好不要让同一个函数根据传入参数不同实现两个差别很大、完全不同的功能,这种一个很傻的做法,但是在python中这样做是为了保持前后兼容性)
type可以这样工作:
type(类名,由父类名称组成的元组(针对继承的情况,可以为空),包函属性的字典(名称和值))
比如:
Test = type("Test",(),{"name":"laowang"}) #定义了一个Test类
test = Test()
print(test.name)
#如何在类中添加方法呢?
def printNum(self):
print("---num----")
Test3 = type("Test3",(),{"printNum":printNum})
t1 = Test3
t1.printNum()
那么什么元类呢?type() 就是元类,它可以用来创建类。type 就是Python在背后用来创建所有类的元类。那么是什么创建的元类呢?是元类创建的元类。如何验证这一点呢?通过 对象名.__class__ 就可以返回该对象 所属于的类(即对象的__class__属性中保存了创建它的类),因为类也是一个对象,所以可以这么用。

元类2 视频需要重看,可以先暂时放一放,
0x02 垃圾回收(了解,面试小概率被问)
1.小整数对象池:
整数在程序中的使用非常广泛,Python为了优化速度,使用了小整数对象池,避免为整数频繁申请和销毁内存空间。
python对小整数的定义是[-5,257] 这些整数对象时提前建立好的,不会被垃圾回收。在python程序中所有位于这个范围内的整数使用的都是同一个对象。
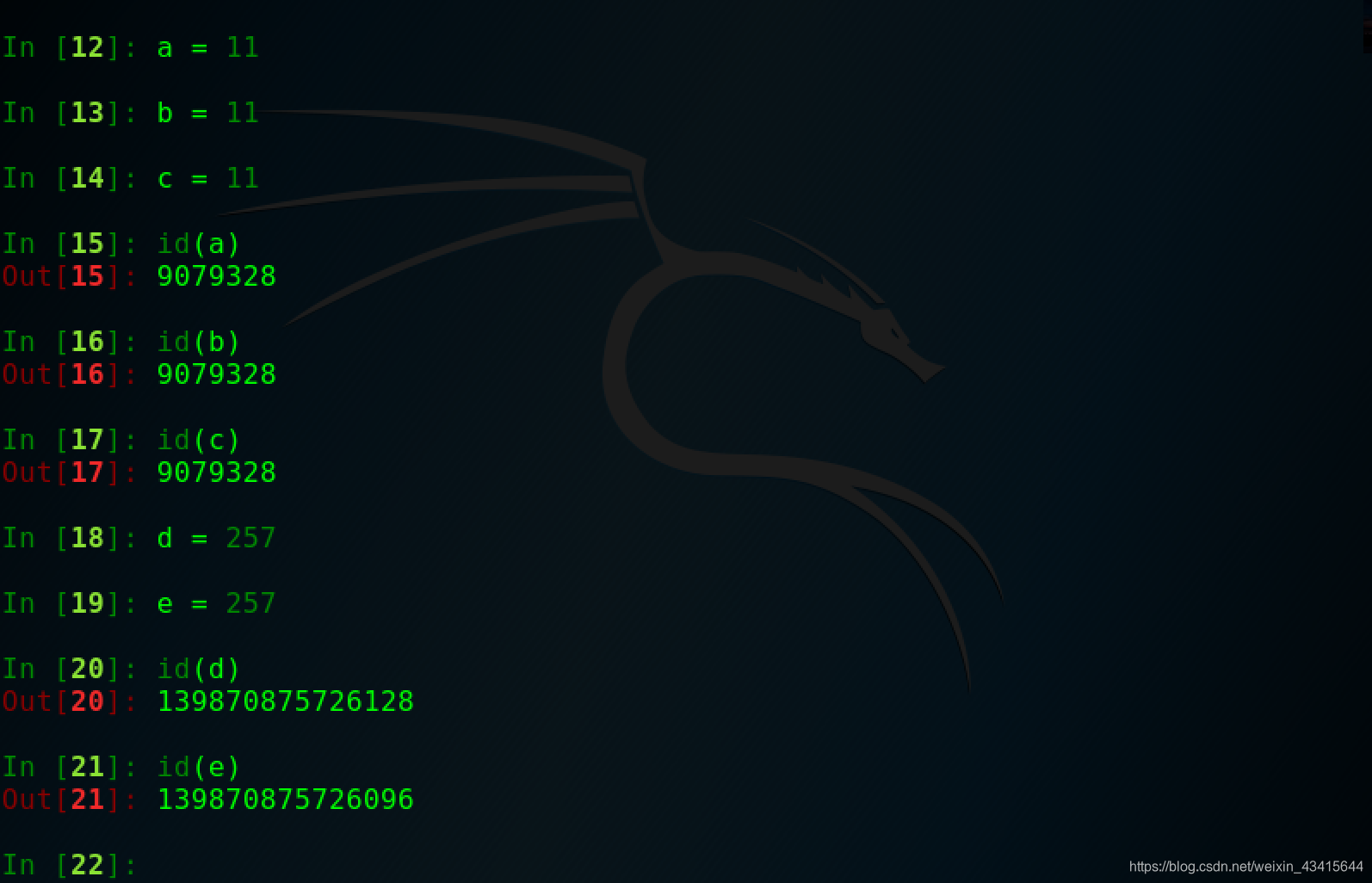
同理,26个字母 也是 提前创建好的,值为同一个字母的变量 使用的都是同一个对象。

2.大整数对象池
只要没有在[-5,257)之间的整数都是大整数,对于这些大整数均会创建一个新的对象。
3.intern机制
所谓intern机制,就是 值为 相同的不含空格下划线的字符串 的变量 不论有个多少个,python解释器只会 开辟一个字符串的内存,然后靠引用计数去维护何时释放。
4.Garbage collection(GC垃圾回收)
python中的GC有两种实现方式,以引用计数机制为主,以分代回收机制为辅:
1.导致引用计数+1的情况:
- 对象被创建,例如 a=23
- 对象被引用,例如 b =a
- 对象被作为参数,传入到一个函数中,例如 func(a)
- 对象作为一个元素,存储在容器中,例如list1 = [a,a]
2.导致引用计数-1的情况:
- 对象的别名被显式销毁,例如del a
- 对象的别名被赋予新的对象,例如 a = 24
- 一个对象离开他的作用域,例如 f函数执行完毕时,func函数中的局部变量(全局变量不会)
- 对象所在容器被销毁,或从容器中删除对象。
3.查看一个对象的引用计数:
import sys
a = “hello world”
sys。getrefcount(a) 先理解如下代码:
class ClassA():
def __init__(self):
print('object born,id:%s'%str(hex(id(self))))
def f2():
while True:
c1 = ClassA()
c2 = ClassA()
c1.t = c2
c2.t = c1
del c1 #因为c1现在的引用计数是2,所以根据引用计数机制,del c1 只是将c1的引用计数变为1,而并没有删除c1指向的内存空间
del c2
f2()也就是对于相互引用(循环引用)的情况,引用计数机制无法搞定。例如在数据结构双链表 中就存在 相互引用的情况
那么分代回收机制是怎样的呢?
下边我介绍 执行过程。
0代链表的产生:
1. 当我们创建对象的时候,会把对象串在链条内
如图:
2. 再创建一个对象也会 添加到链条内如图:

那个黑框就是 对象, 里面的数字就是 引用计数
3. 循环引用扫描
python会遍历链条上的每个对象, 看有没有循环引用,记住了python会遍历所有,为了防止过早的释放。

当发现有循环引用的时候,例如 上图的前两个,虽然没有其他引用计数,但是他们相互引用计数也是1 ,所以不能被释放回收掉。
系统的解决办法就是:让含有循环引用对象的计数 减去一,其他对象的引用计数保持不变, 这样就可以解决没有其他引用导致不能释放的问题。
上边的 前两个 计数就变成了0,符合计数引用回收的机制,立即被回收掉。
1代链条
接着 系统把该删除的删除,把剩下来的保留下来,重新组合串起来,就变成了1代链条
如图:

当一代 链条 扫描一下 还有 循环引用, 接着也用上边的方法 删除 循环引用。
2代链条
接着 系统把该删除的删除,把剩下来的保留下来,重新组合串起来,就变成了2代
注意:
0代链条扫描循环引用几率 是最大的, 接着是1 代,然后是二代 ,python 是根据出现循环引用的几率来决定扫描的几率。
5.gc模块
import gc
gc.get_count() #返回 (567,6,3)
#第一个参数表示0代链表中的 对象数目
#第二个参数表示0代链表被清理的次数
#第三个参数表示1代链表被清理的次数
gc.get_threshold() #返回(700,10,10)
#第一个值表示什么情况(新创建的对象 - 已经释放的对象 如果 大于 700 )下去清理0代链表,
#第二个值表示什么情况下去清理一代链表,即每清理10次0代链表清理1次一代链表 并且同时 清理下 0代链表
#第三个值表示什么情况下去清理二代链表,即每清理10次一代链表清理一次二代链表 并且同时清理0代和1代链表
gc.set_threshold(xxx,xxx,xxx) #设置自动执行垃圾回收机制的频率
gc.disable() #关闭垃圾回收机制
gc.collect() #显示执行垃圾回收
print(gc.garbage) #保存了已经被清理的垃圾(列表)注意:垃圾回收机制本质是调用对象的__del__方法,假如,你重写了__del__方法,记得一定要调用object类中的__del__方法,这样对象占用的内存空间才能被回收。
0x03 内建属性:
所谓内建属性,即提前创建好的属性,例如:__init__ ,__new__,__del__,__str__ ,有人说这些不是方法吗?在python中方法本质上也是属性,属性中保存了函数定义的首地址,加上参数列表便实现了方法的调用。下面着重讨论__getattribute__这个牛逼的内建属性(方法)
属性拦截器
class Itcast(object):
def __init__(self,subject1):
self.subject1 = subject1
self.subject2 = 'cpp'
#属性拦截器:只要访问该类的对象的属性,这个魔术方法就会被自动调用.这个方法可以用来 写log日志 ,例如将什么时候访问了什么属性,都可以记录到数据库中去。
def __getattribute__(self,obj):
if obj == 'subject1':
print('log subject1')
return 'redirect python'
else:
return object.__getattribute__(self,obj)
def show(self):
print("this is Itcast")
s = Itcast("python")
print(s.subject1)#访问一个属性时,会将属性名作为一个字符串传递给obj,print 该函数的 返回值
#log subject
#redirect python
print(s.subject2)
#cpp
s.show() #调用一个方法时,也会将方法的名show传给obj。__getattribute__函数的返回值,将替换show,被加上参数列表,形成调用。(也就说需要先根据__getattribute__得到show指向的那段内存的地址,然后才能调用那段内存定义的函数)注意在开发时有这样一种坑:
class Person(object):
def __getattribute__(self,obj):
print("---test---")
if obj.statswith("a")
return "haha"
else:
return self.test
def test(self):
print("heihei")
t.Person()
t.a #返回haha
t.abc #返回haha
#这就是__getattribute__的精妙之处。不论对象中有没有这些属性,属性名都会发给__getattribute__,只要属性拦截器能搞定这些属性名,就没有任何毛病
t.b #这样会让程序死掉。
#原因是:当t.b执行时,就会将b传给 属性拦截器的第二个参数,因为if条件不满足,所以,会执行return self.test 即返回 self.test的值,要返回self.test的值,由要自动调用 属性拦截器,if条件又不满足,又要返回self.test的值,这样便产生了循环调用的问题,因为每一次调用,都需要开一部分内存来存储变量的值,所以无限次的循环最终会将内存吃光,程序崩溃0x04内建函数
python的内建函数 有3700多个,常用的内建函数有以下:
python2中的range()和xrange()
r = range(10000)
#python2中的range会直接返回一个列表,这是非常危险的,可能会一下子占用大量内存,让程序崩溃
#为了解决这个问题,python2中使用了xrange
x = xrange(10000)
#xrange并不会直接产生这个列表,而是会返回一个对象,但是这个对象并不是一个迭代器对象,因为不能next,通过help(xrange)我们可以知道,这个对象中有个一个内建方法,即__iter__,它的作用是返回一个对应的迭代器对象,输入iter(自己) 就会调用自己的__iter__方法。
i = iter(x)
next(i)#返回值为0
next(i)#返回值为1map函数:(大数据分析、数据挖掘)
下面只介绍冰山一角
#map(函数引用,可迭代对象)
#将可迭代对象的元素逐个扔给 函数,返回函数的 返回值 组成的可迭代对象
#case 1:函数需要一个参数时
list = map(lambda x:x*x,[1,2,3])
print(list) #[1,4,9]
#case 2:函数需要两个参数时
#Example1:
print(map(lambda x,y:x+y,[1,2,3],[4,5,6]))
#[5,7,9]
#Example2:
def f1(x,y):
return (x,y)
nums = [0,1,2,3,4,5,6]
days = ['sunday','monday','tuesday','wednesday','thursday','friday','saturday']
num_days = map(f1,nums,days)
print(num_days)
BTW:
学完python之后,工作两个年,python你就用得非常纯熟了,这个时候,再系统学习一波,高数,线代,概率论,然后就可以直接切到人工智能领域了。
filter函数:
filter(函数引用,可迭代对象)
#filter会将可迭代对象中的每个元素 扔给 函数引用 指向的函数,最后返回 调用结果为true的元素组成的 列表
#例如:
list = filter(lambda x:x%2,[1,2,3,4])#0表示false 非0都是True
print(list) #[1,3]reduce函数:
reduce(函数引用,可迭代对象,初始参数)
#reduce依次从sequence中取一个元素,和上次调用function的结果做参数再次调用function。第一次调用function时,如果提供了初始参数,那么会以可迭代对象的第一个元素和初始参数作为参数调用函数,否则会以可迭代对象的前两个元素作为参数调用function,注意function函数不能为None
reduce(lambda x,y:x+y,[1,2,3,4])
#10
reduce(lambda x,y:x+y,[1,2,3,4],5)
#15 第一调用时,初始参数赋值给x,可迭代对象的第一个元素赋值给y,即相当于将初始参数当做了上次调用的结果。证明如下:
reduce(lambda x,y:x+y,["aa",'bb','cc'],'dd')
#'ddaabbcc'注意:在python3中,reduce函数已经被从全局名字空间里移除了,它现在被放置在functools模块里面。要使用的话,需要先引入:from functools import reduce
sorted函数:
a = [22,11,33]
a.sort() #返回从小到大排序
a.sort(reverse = True)#返回从大到小排序
sorted([22,11,33])#返回从小到大排序的列表
sorted([22,11,33],reverse = 1) #返回从大到小排序0x05 集合:
a = ”abcdef“
b = set(a)
A = "bdf"
B = set(A)
#求交集
jiaoji = b&B #按位与运算符 在这里就是 求交集的意思
#求并集
bingji = b | B
#求差集
chaji = B - b
#求对称差集
duichengchaji = b ^ B #即两个集合的并集减去两个集合交集这些知识 可以用来做用户访问的分析,例如统计本月相对于上个月老用户的人数
0x06 functools:
1.偏函数 partial
import functools
def showarg(*args,**kw):
print(args)
print(kw)
p1 = functools.partial(showarg,1,2,3)
p1() #相当于调用 showarg(1,2,3)
#偏函数的意义在于 只需要传一次参数,之后调用这个函数的时候,就不要再传参数了。简而言之,省事。
p1(4,5,6) #相当于调用 showarg(1,2,3,4,5,6)
2.wrap(包)函数:
def note(func):
"note function"
def wrapper():
"wrapper function"
print('note something')
return func()
return wrapper
@note
def test():
"test function"
print("I am test")
print(help(test))
#显示的是装饰后的说明文档, 即wrapper function。这其实是一个非常不好的副作用。
#例如在原来的函数中你的同事辛辛苦苦写好说明文档,但是你在装饰器中没有写任何说明文档。
#这样一来,经过装饰器改写的函数,被help时,不会显示任何说明文档,一切都凉凉了。
#如何消除这一副作用呢?这就需要用到wrap函数了import functools
def note(func):
"note function"
@functools.wraps(func)
def wrapper():
"wrapper function"
print('note something')
return func()
return wrapper
@note
def test():
"test function"
print("I am test")
print(help(test)) #这样就显示了原来的说明文档0x07 模块进阶:
你了解python中的标准模块吗?什么叫标准呢?一般而言,标准是指“默认常用”的功能。
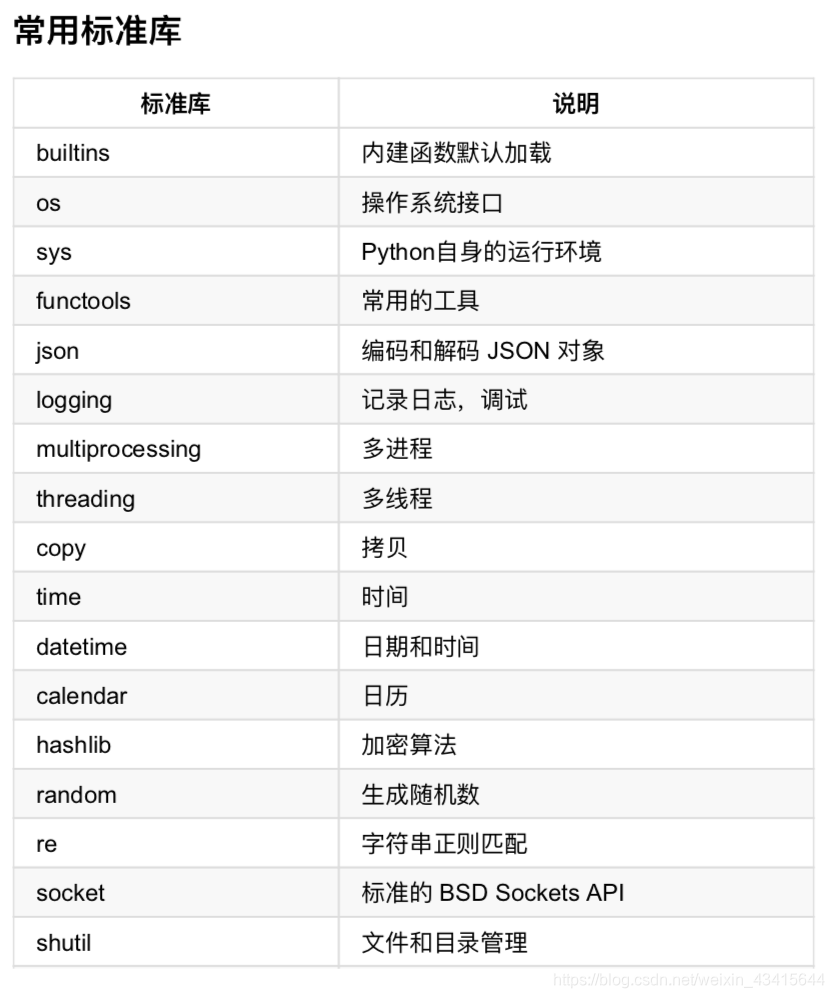
1.hashlib
#python2
import hashlib
m = hashlib.md5() #创建hash对象
print(m) #<md5 HASH object>
m.update('itcast') #更新哈希对象以字符串参数
print m.hexdigest() # 返回加密后的字符串, 即32位,十六进制数字字符串

2.扩展库
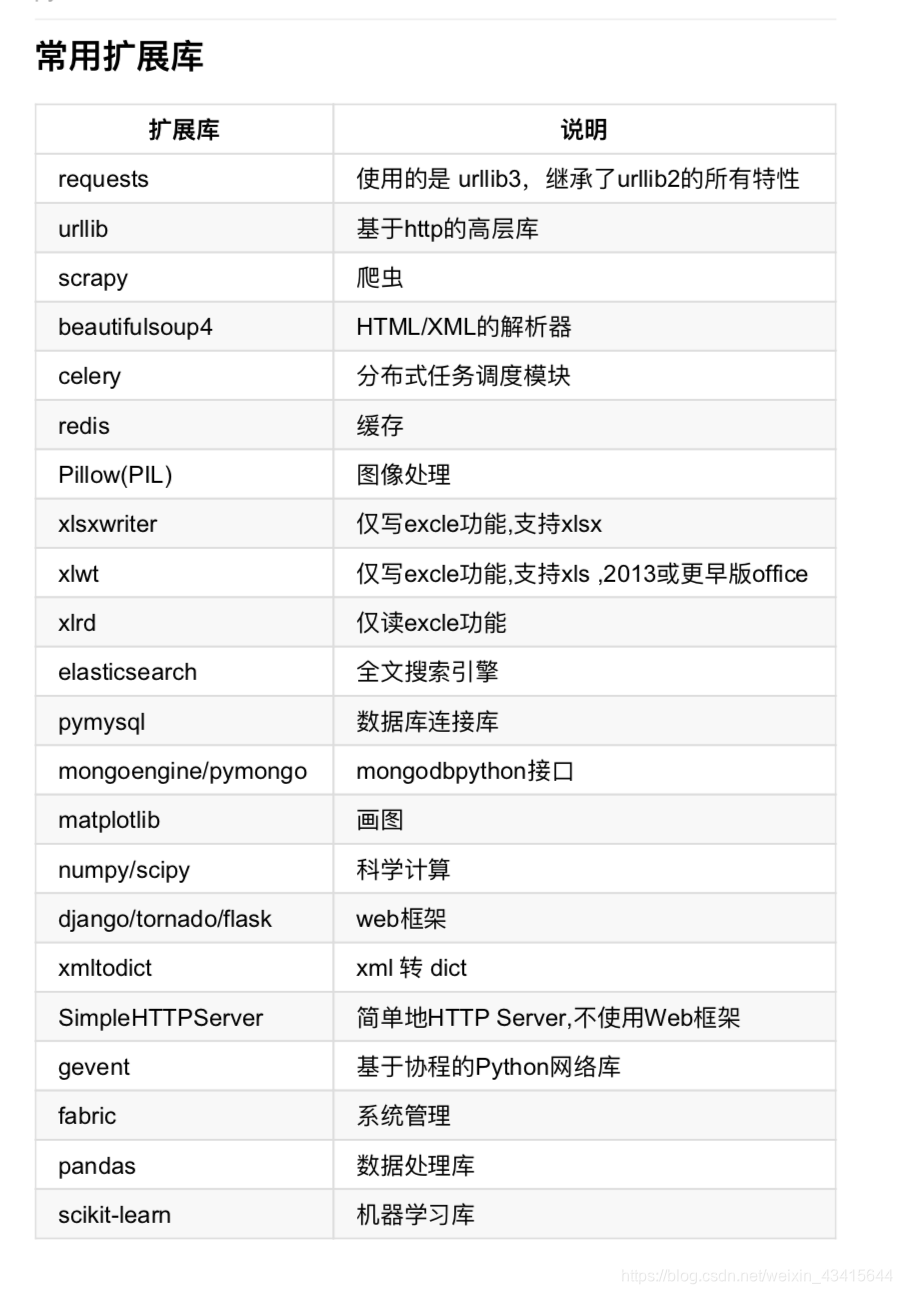
实例:
在终端输入:
python3 -m http-server 端口
将当前文件作为公开目录 开启web服务器。这样在其他电脑上只要知道本机的ip地址,就可以访问本机的公开目录了。
ctrl c 关闭服务器


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









