




一、性能分析过程
1、分析过程
- 检查RT:模拟用户发起负载后,采用自顶向下的方式首先分析RT(响应时间)
- 检查TPS:TPS大时RT小,说明性能良好
- 检查负载机资源消耗:检查cpu使用率,cpu负载(load average)确认是用户cpu占用高还是系统cpu占用高?
前提:确认测试脚本没有性能问题,不会造成结果统计的不准确
检查内存使用情况,确认并发内存泄露风险,不会造成结果统计的不准确
- 判下负载机受否有性能问题:排查负载机的性能问题,确保测试结果可参考
- 检查web服务器的资源消耗:
1)检查cpu使用率,确认用户cpu与系统cpu占用情况
2)检查内存使用情况
3)检查磁盘使用情况
4)检查占用的带宽
5)分析web页面相应的时间组成,确认是什么请求影响了性能
- 确认是否web服务器瓶颈:标判断是否是web服务器硬件性能瓶颈
- 检查中间件配置:确认是否是此配置问题
- 检查APP服务器资源消耗:关注cpu、内存、磁盘、IO,判断是否是APP服务器硬件性能瓶颈
- 数据库服务器资源消耗分析
- cpu消耗,cpu负载
- 内存消耗
- IO繁忙程度
- 数据库监控
对DB不熟悉的可以找DBA帮忙监控分析
- 是否是DB性能问题:有监控结果来判断是否是DB性能问题
- 是否sql问题:
1)定位最不合理的sql占比
2)索引是否正常引用
3)减产共享sql是否合理范围
4)检查分析是否合理
5)检查数据ER结果是否合理
6)检查数据热点问题
7)检查数据分析是否合理
8)检查碎片整理等
- 其他:比如网络阻塞、磁盘IO瓶颈、热点等
2、分析方法
1)自底向上:通过监控硬件及操作系统性能指标(cpu、内存、磁盘、网络等硬件资源的性能指标)来分析性能问题(配置、程序等问题)。因为用户请求最终是由计算机硬件设备来完成的,做事的是cpu。
2) 自顶向下:通过生成负载来观察被测试的系统性能,比如响应时间、吞吐量;然后从请求起点由外及里一层一层地分析,从而找到性能问题所在。
二、粗略分析tps、响应时间,负载机器、服务器资源和瓶颈
第一步:从分析summary的事务执行情况入手,查看tps、响应时间的是否合理,负载机是否为瓶颈
Summary主要是判定事务的响应时间与执行情况是否合理,如果发现问题,则需要做进一步分析
通常情况下,如果事务执行情况失败或者相应时间过程等,都需要做深入分析
查看分析概要时的一些原则
- 用户是否全部运行,最大运行并发数是否与场景设计的最大运行并发用户数一致。如果没有,则需要打开与虚拟用户相关的分析图进一步分析虚拟用户不能正常运行的详细原因;
- 事务的平均相应时间、90%事务最大响应时间用户是否可以接受。如果事务响应时间过长,则要打开与事务相关的各类分析图,深入地分析事务的执行情况
- 查看事务是否全部通过,如果有事务失败,则需要深入分析原因。很多时候,事务不能正常执行意味着系统出现了瓶颈
- 如果一切正常,则本次测试没有必要进行深入分析,可以进行加大压力测试
- 如果事务失败过多,则应该降低压力继续进行测试,使分析更容易进行;
- 更多步骤
第二步:查看负载发生器和服务器的系统资源情况
查看cpu的利用率和内存使用情况,尤其要主要查看是否存在内存泄露问题,这样做是由于很多时候系统出现瓶颈的直接表现是cpu利用率过高或者内存不足。
应该保证负载发生器在整个测试过程中其cpu、内存、带宽没有出现瓶颈,否则测试结果无效。
待测试服务器,重点分析测试过程中cpu和内存是否出现瓶颈:
cpu需要查看其利用率是否经常达到100%或者平均利用率一直高居95%以上;
内存需要查看是否够用以及测试过程是否存在溢出现象(对于一些中间件服务器要查看其分配的内存是否够用)
三、并发数、QPS、平均响应时间三者之间关系
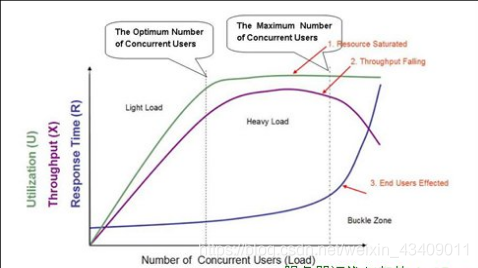
上图横坐标是并发用户数。绿线是CPU使用率;紫线是吞吐量,即tps;蓝线是响应时间。
三个区域:轻负载区(Light Load)、重负载区(Heavy Load)、塌陷区(Buckle Zone)
两个点:最优并发用户数(The Optimum Number of Concurrent Users)、最大并发用户数(The Maximum Number of Concurrent Users)。
三个状态描述:资源饱和(Resource Saturated)、吞吐下降(Throughput Falling)、用户受影响(End Users Effected)。
在 TPS 增加的过程中,响应时间一开始会处在较低的状态,接着响应时间开始有些增加,直到业务可以承受的时间点 ,这时 TPS 仍然有增长的空间。再接着增加压力,达到 1 点时,达到最大 TPS。我们再接着增加压力,响应时间接着增加,但 TPS 会有下降(请注意,这里并不是必然的,有些系统在队列上处理得很好,会保持稳定的 TPS,然后多出来的请求都被友好拒绝)。
较少tps,CPU工作肯定是不饱合的。一方面该服务器可能有多个cpu,但是只处理单个进程,另一方面,在处理一个进程中,有些阶段可能是IO阶段,这个时候会造成CPU等待,但是有没有其他请 求进程可以被处理)。随着tps增加,CPU利用率上升,平均响应时间也在增加,而且平均响应时间的增加是一个指数增加曲线。而当并发数增加到很大时,每秒钟都会有很多请求需要处理,会造成进程(线程)频繁切换,反正真正用于处理请求的时间变少,每秒能够处 理的请求数反而变少,同时用户的请求等待时间也会变大,甚至超过用户的心理底线。
所以1、如果压测结果在轻负载区,且summary报告指标正常,没有必要分析负载机和服务器资源监控
2、如果在种负载区,需要分析负载机和服务器资源监控,结果日志分析是压测脚本原因、负载机、还是服务器资源原因造成了瓶颈
四、瓶颈分析
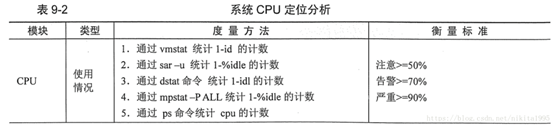
CPU定位分析
在系统的cpu分析定位过程中,当系统的cpu利用率大于50%时,我们就需要注意了,当系统的cpu利用率大于70%的时候,就需要密切关注,当系统的cpu的利用率高于90%的时候,情况就比较严重了,通过这些监控分析情况,我们可以用的命令有vmstat,sar,dstat,mpstat,top,ps等命令来进行统计分析

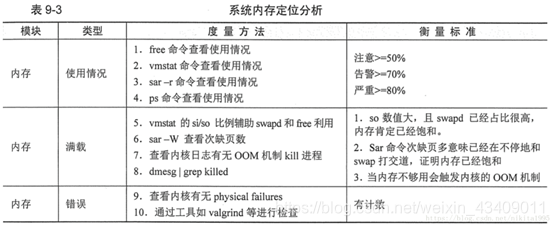
内存定位分析
在系统的内存分析定位过程中,当系统的内存利用率大于50%时,我们就需要注意了,当系统的内存利用率大于70%的时候,就需要密切关注,当系统的内存的利用率高于80%的时候,情况就比较严重了,通过这些监控分析情况,我们可以用的命令有vmstat,sar,dstat,free,top,ps等命令来进行统计分析
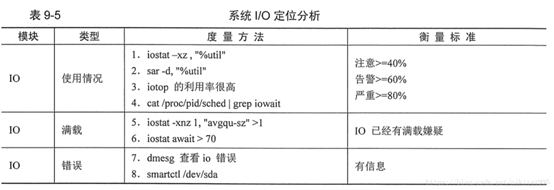
IO定位分析
衡量系统IO的使用情况,我们可以使用sar,iostat,iotop等命令来进行系统级的IO监控分析。当发现IO利用率大于40%时,我们就需要注意了,当IO利用率大于60%的时候,处于告警阶段,高于80%时IO就出现阻塞了
网络定位分析
衡量系统网络的使用情况,我们可以使用sar,ifconfig,netstat以及查看net的dev速率,通过查看发现收发包的吞吐速率达到网卡的最大上限,网络数据报文有因为这类原因而引发的丢包,阻塞等现象都证明当前网络可能存在瓶颈,在进行性能测试时为了减少网络的影响,一般我们都是在局域网中进行测试执行


五、系统监控分析
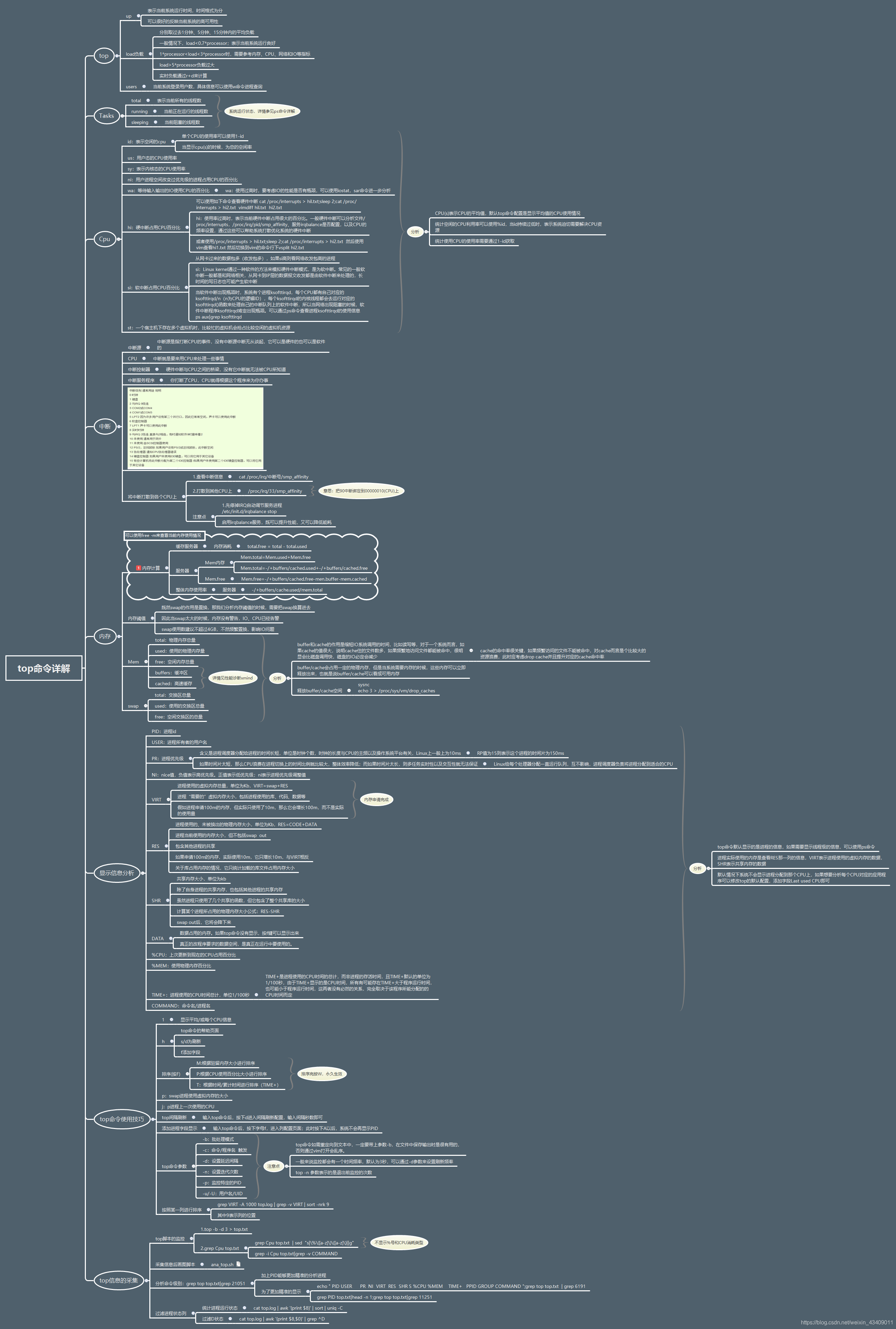
关于top命令使用见下图详解
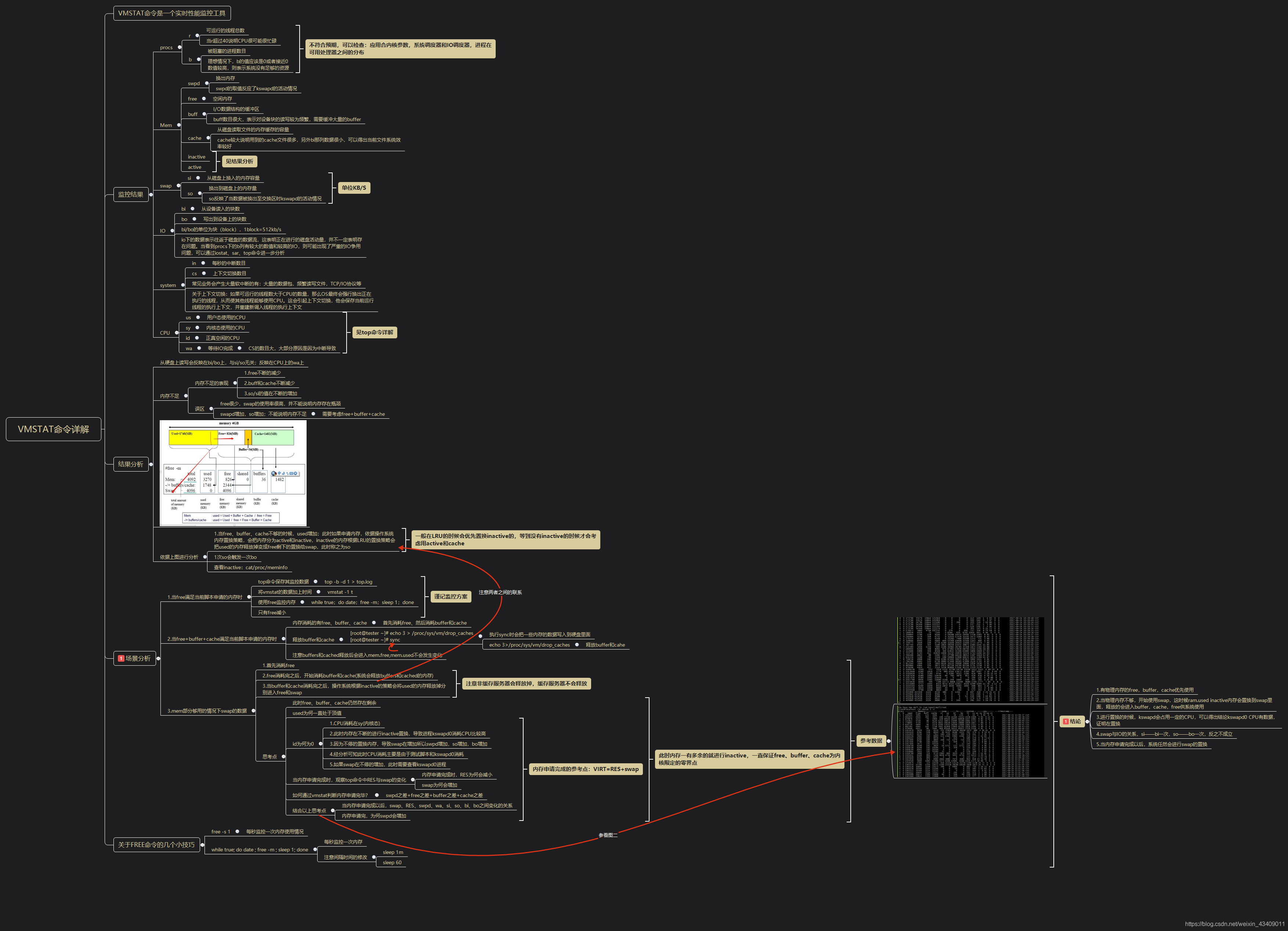
vmstat详解
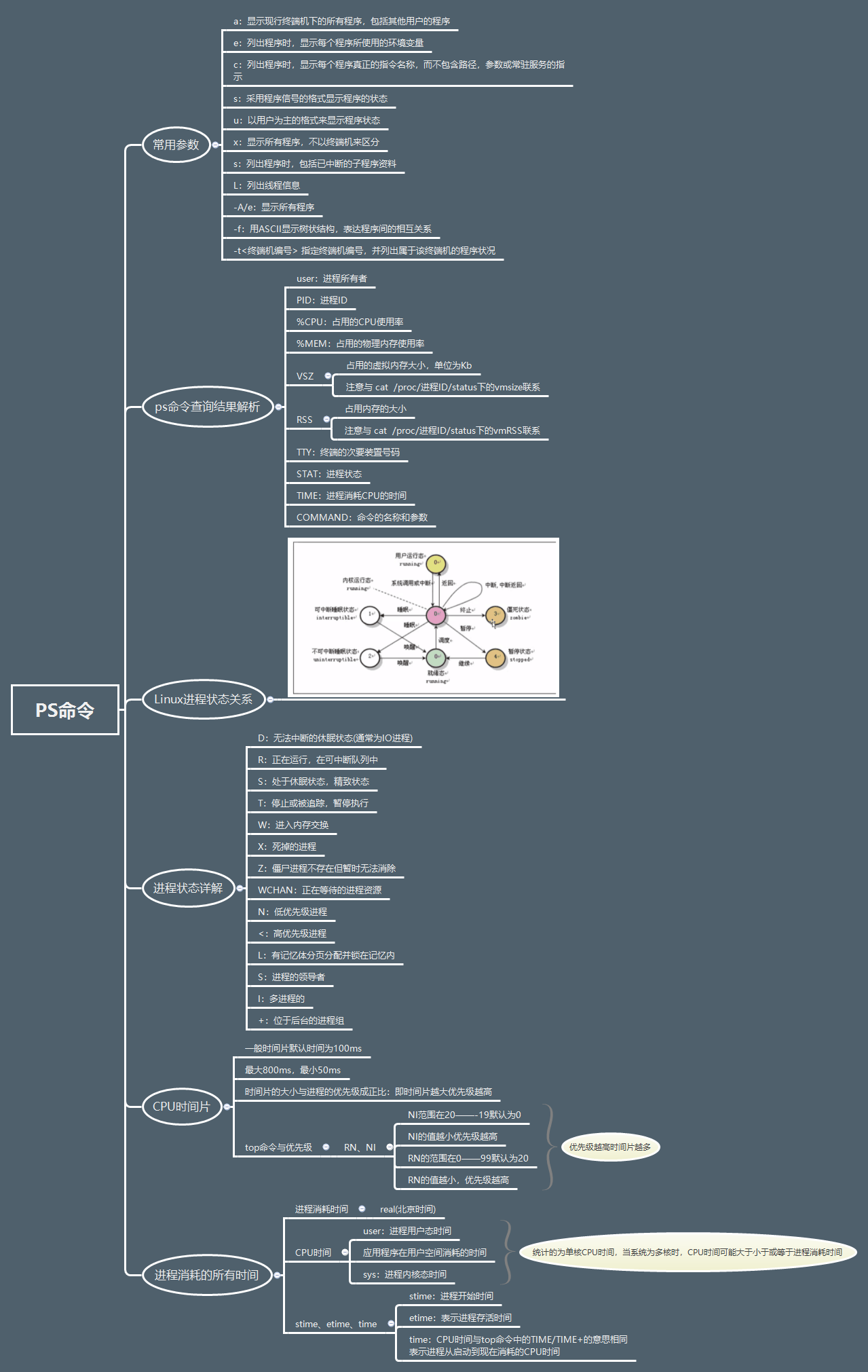
ps命令详解
六、常用调优手段
1、空间换时间,内存、缓存就是典型的空间换时间的例子。利用内存缓存从磁盘上取出的数据,cpu请求数据直接从内存中获取,从而获取比从磁盘读取数据更高的效率
2、时间换空间,当空间成为瓶颈时,切分数据分批次处理,用更少的空间完成任务处理。上传大附件时经常用这种方式
3、分而治之,把任务切分,分开执行,也方便并行执行来提高效率,Hadoop中的HDFS、mapreduce都是这个原理
4、异步处理,业务链路上有任务时间消耗较长,可以拆分业务,减少阻塞影响。常见的异步处理机制有消息队列、消费队列等,目前在互联网应用中大量使用
5、并行,用多个进程或者线程同时处理业务,缩短业务处理时间,比如我们在银行办业务,如果排队任务较多时,银行会加开柜台
6、离用户更近一点,比如CDN技术,把用户请求的静态资源放在离用户更近的地方
7、一切可扩展,业务模块化、服务化、良好的水平扩展能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









