




首先查看源码
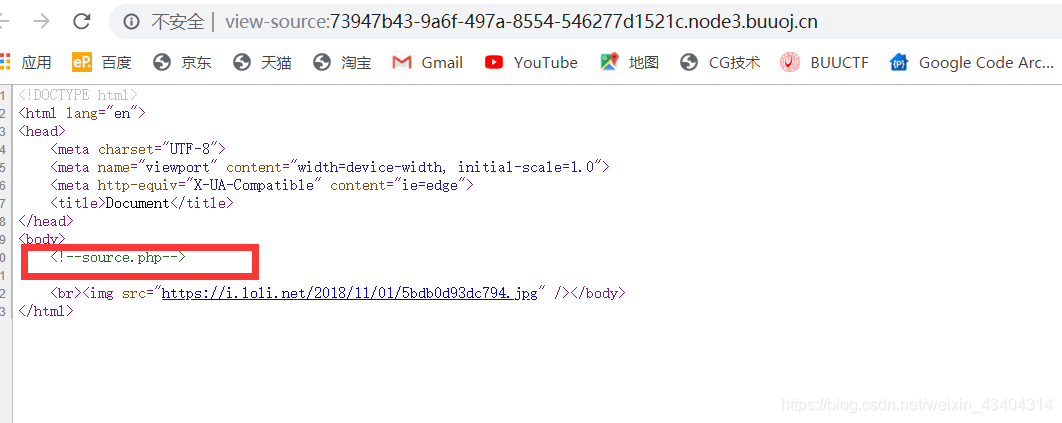
返回到图片页面打开source.php文件
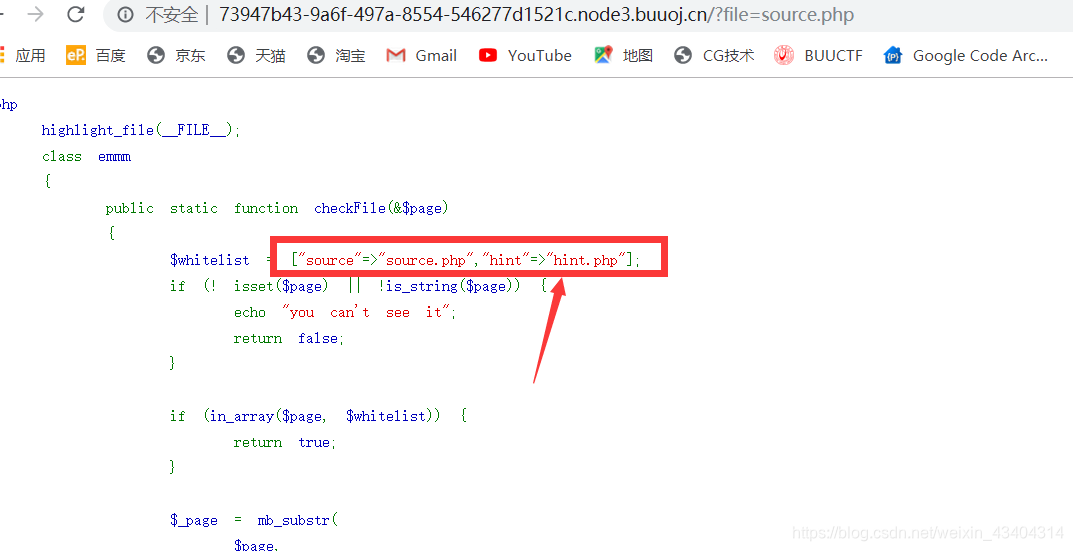
发现还包含的有一个文件,于是再次返回图片页面打开hint.php
得到
%253F绕过
![]()
即可得flag.
第一次写,不喜勿喷
 本文介绍了一种通过查看图片页面源码来发现隐藏信息的方法。首先,通过检查source.php文件,发现了另一个hint.php文件的存在。进一步分析后,利用'%253F'绕过技巧,成功获取了flag。这是初次尝试分享此类技巧,希望对读者有所启发。
本文介绍了一种通过查看图片页面源码来发现隐藏信息的方法。首先,通过检查source.php文件,发现了另一个hint.php文件的存在。进一步分析后,利用'%253F'绕过技巧,成功获取了flag。这是初次尝试分享此类技巧,希望对读者有所启发。
首先查看源码
返回到图片页面打开source.php文件
发现还包含的有一个文件,于是再次返回图片页面打开hint.php
得到
%253F绕过
![]()
即可得flag.
第一次写,不喜勿喷

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 5843
5843





