
心得体会
 关注
关注
 分享
分享
文章平均质量分 73
宝宝不哭^_^
这个作者很懒,什么都没留下…
展开
专栏收录文章
- 默认排序
- 最新发布
- 最早发布
- 最多阅读
- 最少阅读
-
大数据人的好帮手StreamX
Flink 流批一体利器,大数据开发平台,大数据开源项目!原创 2022-04-11 11:14:28 · 2620 阅读 · 0 评论 -
2021-11-12
Flink yarn-application怪异显示: run-application -t yarn-application insert-into_default_catalog.default_database.XXXID:00000000000000000000000000000000Flink yarn-application模式 JobId很怪异ID:00000000000000000000000000000000问题分析小记搞技术难,坚持把一件事做好难,能坚持写文章记录踩坑生活更是难上加原创 2021-11-12 15:03:05 · 1919 阅读 · 0 评论 -
awk打印第n个参数到最后一个技巧/将n行组成一列
打印第n参数到最后一个参数文本的NF不等,即字段长度不固定,想截取从3到3到3到NF第一反应是使用循环[root@localhost ~]# echo “1 2 3 4 5” | awk ‘{for(i=1;i<3;i++)$i="";print}’3 4 5但其实可以使用CU帽神给的技巧[root@localhost ~]#echo “1 2 3 4 5” | awk ‘{$1=$2="";print}’3 4 5如果分隔符比较标准的话(即使用的是统一的标准分隔符),建议还是用cut原创 2020-12-03 14:56:36 · 2458 阅读 · 0 评论 -
HBase Shell命令大全
一:简介HBase的名字的来源于Hadoop database,即hadoop数据库,不同于一般的关系数据库,它是非结构化数据存储的数据库,而且它是基于列的而不是基于行的模式。HBase是一个分布式的、面向列的、基于Google Bigtable的开源实现。利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为协同服务。二:HBase重要概念HBase的表结构HBase以表的形式存储数据。表有行和列组成。列划原创 2020-09-02 20:13:43 · 755 阅读 · 0 评论 -
Hive最常用近百个函数详解
背景Apache Hive是一个建立在Apache Hadoop之上的数据仓库软件项目,用于提供数据查询和分析,现支持引擎有MapReduce、Tez、Spark等等。Hive像传统的关系型数据库一样含有大量内置函数,但也可支持UDF、UDAF等用户自定义函数编写。Hive自身支持函数的隐式转换,方便用户使用。但是这些隐式转换出现问题可能不会报错,但是也会给用户带来非期望的结果。建议大家函数按照规范来使用。内置函数现在分门别类地整理了日期、数值、集合、条件、字符串、聚合等内置函数的详解与举例说明等原创 2020-07-31 19:25:41 · 1698 阅读 · 0 评论 -
Flink1.10新特性探究之Hive整合以及实时数据处理实例(上)
最近工作比较忙,一直想写一篇Flink1.10.0与Hive的整合博文,上周末进行的整合探究,现将心得和实践实例呈上,希望给正在探索的小伙伴提供一些帮助,顺带将Flink新特性在数据实时处理上的心得一并呈上,口水话不多说了,咱们直接开干!!!!!!!!!==============》文章目录开发环境版本说明开发环境版本说明...原创 2020-05-19 22:29:26 · 1357 阅读 · 11 评论 -
Flink on yarn 启动报错:缺jar包(Error: A JNI error has occurred, please check your installation and try ag)
很久以前遇到的问题,突然回顾了,今天做下总结,供大家参考===============》启动yarn模式具体报错如下: bin]$ ./yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -dError: A JNI error has occurred, please check your installation and try ag...原创 2020-04-29 19:33:19 · 2634 阅读 · 1 评论 -
ELK之Logstash(将mysql数据同步到ES6.6.0(全量+增量))
下载安装包时注意下载到指定文件夹 这里我放在OPT文件夹下一:安装logstash进入到opt文件夹打开终端 执行以下命令wget -c https://artifacts.elastic.co/downloads/logstash/logstash-6.6.0.zip加上-c支持断点续传二:解压logstashunzip logstash-6.6.0.zip三:进入到logstas...原创 2020-01-20 10:26:24 · 1044 阅读 · 0 评论 -
mysql之浅谈主外键
主键在一个数据表中只能有唯一的一个,约束当前字段的值不能重复,且非空保证数据的完整性,也可以当做当前数据表的标识符用来查询(当做索引,唯一性索引的一种)创建带主键的表/*带主键*/CREATE TABLE T( id int(11) not null primary key, name char(20) ); /*带复合主键*/CREATE TABLE T...原创 2019-12-19 10:01:06 · 190 阅读 · 0 评论 -
Spark Streaming offset的管理那些事!
Spark Streaming offset的管理那些事!1.Kafka 消息的管理办法(1) topictopic中包含多个分区,建议分区是Kafka broker的整数倍,或者是磁盘的整数倍分区数是Kafka存储的主要概念,key的Hash&numPartition,在分区里存储的时候,offset-msg消费者 消费消息 首先会自己确定offset的范围,然后使用该范围去k...原创 2019-12-05 22:49:14 · 417 阅读 · 0 评论 -
运行Spark SQL报The specified datastore driver ("com.mysql.jdbc.Driver") was not found in the CLASSPATH.
想启动spark-sql,结果报了Caused by: org.datanucleus.store.rdbms.connectionpool.DatastoreDriverNotFoundException: The specified datastore driver (“com.mysql.jdbc.Driver”) was not found in the CLASSPATH. Pleas...原创 2019-12-03 14:38:08 · 585 阅读 · 0 评论 -
运行hbase报错(因为配置了Phoenix后)
运行HBase应用开发程序产生异常,提示信息包含org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory的解决办法Using Spark's default log4j profile: org/apache/spark/log4j-defaults.propertiesException in thread "main...原创 2019-11-13 17:28:29 · 909 阅读 · 0 评论 -
手机号、身份证号类似脱敏处理(ETL)
先上代码:========》 //测试消费 /* inputDstream.map(_.value()).foreachRDD(rdd => println(rdd.collect().mkString("\n")) )*/ val orderInfoDstrearm: DStream[OrderInfo] = inputDstream.map {...原创 2019-11-08 15:05:37 · 1969 阅读 · 0 评论 -
IDEA编写Scala代码时自动显示变量类型
IDEA作为最智能的编辑器,功能真的是强大无比,在编写Scala程序时,如果显示变量类型,编写程序时会方便的多。下面就介绍如何在idea上设置显示Scala变量类型。问题如果你在编写的Scala程序的时候,不知道变量的数据类型,有可能会给你到来一下不便,如果显示变量类型,不仅知道自己编写的代码是不是有问题,或者知道自己应该如何使用变量。如果你没有设置显示类型,比如下面的数组,就不知道这个数组中...原创 2019-11-08 11:36:49 · 5354 阅读 · 5 评论 -
Canal 问题排查(不抓取数据)
问题一:ERROR c.a.otter.canal.parse.inbound.mysql.MysqlEventParser - dump address /192.168.1.50:3306 has an error, retrying. caused bycom.alibaba.otter.canal.parse.exception.CanalParseException: can’t f...原创 2019-11-07 14:56:20 · 5093 阅读 · 0 评论 -
CDH 5.1.5(parcels)集群中hive1.1.0升级到hive-1.2.1步骤全,升级hive元数据库,数据不丢失(亲测可用)
1.下载hive-1.2.1安装包 http://archive.apache.org/dist/hive/hive-1.2.1/apache-hive-1.2.1-bin.tar.gz2.将安装包传到集群所有节点上3.所有节点root用户下cd /opt/cloudera/parcels/CDH/lib/hivemkdir lib1214.所有节点解压 apache-hive-1.2...原创 2019-08-14 14:55:55 · 976 阅读 · 8 评论 -
HBase:HMaster启动后自动关闭
好久没有来写博客了,总算是忙完了,今天回到阔别已久的CU。一早来到单位,就开始着手调试新测试镜像。但是一启动就出了问题,原先调试好的分布式平台却提示了错误:Zookeeper available but no active master location found直观的感觉是HMaster的问题,果然,JPS查看发现没有了HMaster进程,进入到hbase-master日志中查看,发现了以...原创 2019-08-15 21:33:55 · 2182 阅读 · 0 评论 -
HBase启动RegionServer自动关闭
HBase启动RegionServer自动关闭HBase 1.2.8,采用伪分布式部署,zookeeper使用HBase自带启动后 HMaster 、 HQuorumPeer、HRegionServer 三个进程都启动了。过几秒钟后,再看,HRegionServer 消失了查看log。已经搞定了。自己回复一下,方便后来的同学遇到此类问题时。通过hbase hbck 进行检查执行...原创 2019-08-15 23:12:29 · 2065 阅读 · 0 评论 -
踩坑之路之(ssh执行程序时 环境变量丢失)
以下是脚本启动后报错情况:====================》》》》》例子:程序启动脚本#!/bin/bashJAVA_BIN=/bigdata/jdk1.8.0_152/bin/javaPROJECT=gmall0823APPNAME=dw-logger-0.0.1-SNAPSHOT.jarSERVER_PORT=8080 case $1 in "start") ...原创 2019-08-28 09:27:09 · 886 阅读 · 0 评论 -
atlas修改源码 配置免密登录
免密测试地址:http://hadoop102:21000/index.html#!/detailPage/48c21a12-018a-41f9-a5cb-be82a388db7d修改spring security 替换 jar包 地址:/opt/module/atlas/distro/target/apache-atlas-0.8.4-bin/apache-atlas-0.8....原创 2019-08-28 09:31:20 · 585 阅读 · 4 评论 -
solr cloud模式踩坑之路(Atlas)
**主要解决两个Bug(bug糊里糊涂产生的===========> 创建索引核心失误后的教训!!!)**1.bug的由来:目的:部署Atlas2.0创建集合 --》索引建立创建命令: $SOLR_BIN/solr create -c vertex_index -d SOLR_CONF -shards #numShards -replicationFactor #replicati...原创 2019-09-11 22:38:23 · 1665 阅读 · 0 评论 -
Class org.openx.data.jsonserde.JsonSerDe not found (json数据聚合运算时无法识别)
首先建立基础表的时候:对于数仓中:ods层========》ods层:drop table if exists ods_startup_log;create external table ods_startup_log ( `mid` string COMMENT '设备唯一标识', `uid` string COMMENT '用户标识', `os` string COM...原创 2019-09-24 16:14:16 · 2644 阅读 · 0 评论 -
解决hive建表报错 character ' ' not supported here
好好的建个表hive都给我报错,疯狂一顿baidu、google。解决用有道云markdown打开(需要下载有道云笔记,没有自行官网下载),发现前面多了若干点,如红框里面标红的。只需要删除这些点即可前面,后面多的小点点都去掉。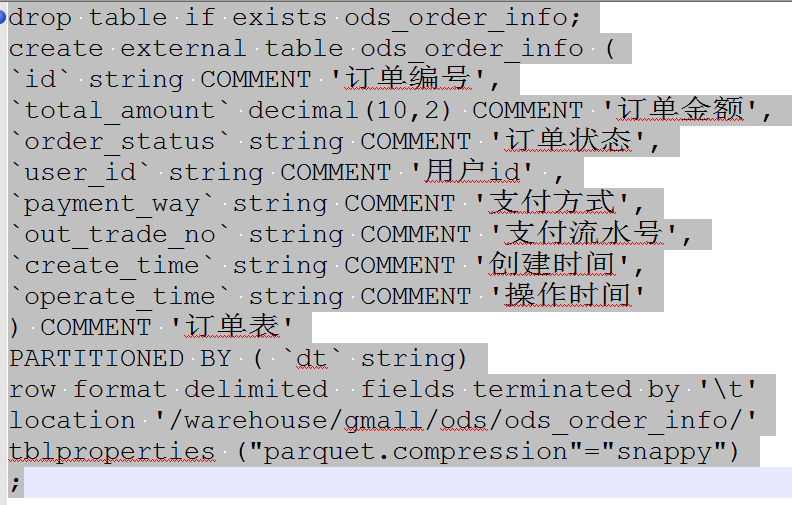和Map Join(Map阶段完成join)。一、Hive Common Join如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join.整个过程包含Map、Shuffle、Re...原创 2019-04-01 23:18:50 · 864 阅读 · 0 评论 -
SQL语句中:UNION与UNION ALL的区别
UNION用的比较多union all是直接连接,取到得是所有值,记录可能有重复union 是取唯一值,记录没有重复1、UNION 的语法如下:[SQL 语句 1]UNION[SQL 语句 2]2、UNION ALL 的语法如下:[SQL 语句 1]UNION ALL[SQL 语句 2]效率:UNION和UNION ALL关键字都是将两个结果集合并为一个,但这两者从使用和效...原创 2019-04-01 21:10:45 · 256 阅读 · 0 评论 -
kafka怎么做到不丢失数据,不重复数据
kafka怎么做到不丢失数据,不重复数据,以及kafka中的数据是存储在什么地方的?被问到kafka怎么做到对于数据的不丢失,不重复。首先怎么做到不重复消费呢?在kafka的消费中,我们一般使用zookeeper充当kafka的消费者,去消费kafka中的数据。那么怎么做到不重复消费呢?假如消费了一段时间之后,kafka挂掉了,这时候需要将sparkstreaming拉起来,然后继续进行消费...原创 2019-03-29 23:51:34 · 894 阅读 · 0 评论 -
Spark 性能调优与数据倾斜故障处理()
**Spark 性能调优**1.1常规性能调优1.1.1常规性能调优一:最优资源配置 —>(Spark性能调优的第一步,就是为任务分配更多的资源, 在一定范围内,增加资源的分配与性能的提升是成正比的)1.1.2常规性能调优二:RDD优化1.2.1 R...原创 2019-03-25 18:29:06 · 719 阅读 · 0 评论 -
大数据之Kafka(心得)
什么是Kafka?(1) 在流式计算中,Kafka一般用来缓存数据,Spark通过消费Kafka的数据进行计算。(2)Kafka是一个分布式消息队列。(3)Kafka对消息保存是根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。为什么需要消息队列1)解耦:...原创 2018-12-16 23:30:07 · 999 阅读 · 3 评论 -
大数据之Hbase(心得)
什么是HBase(1)HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储。(2)HBase是一个高可靠性、高性能、面向列、可伸缩(可扩展)的分布式存储系统,利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群。(3)HBase的目标是存储并处理大型的数据,更具体来说是仅需使用普...原创 2018-12-21 01:38:18 · 3976 阅读 · 1 评论 -
大数据之免密登录小结
今天突然再次用到免密登录,那就再做一波总结:一、免密登录最简洁配置方法公钥私钥的免密登录:以hadoop102、hadoop103、hadoop104 三个节点为例:1.查看ssh文件命令:ls -al执行命令:cd /home/一般用户名cd .sshssh -keygen -t rsa (rsa: 加密算法)三次回车 , 生成公钥和私钥目的:使其从102~104 ...原创 2018-12-08 01:04:53 · 586 阅读 · 0 评论 -
如何用SQL做留存率分析
背景APP分析中经常用到AARRR模型(海盗模型)用来分析APP的现状,其中一个重要节点就是提高留存(Acquisition),而留存率这个指标在这个阶段可以说是核心指标也不为过。那如何用SQL计算留存率呢?留存率计算方法假如今天新增了100名用户,第二天登陆了50名,则次日留存率为50/100=50%,第三天登录了30名,则第二日留存率为30/100=30%,以此类推。用SQL的计算思路...原创 2019-03-28 20:19:17 · 4462 阅读 · 2 评论 -
Java调用Shell项目实战总结
刚刚的项目中,有大量的场景需要Java 进程调用 Linux的bash shell 脚本实现相关功能。从之前的项目中拷贝的相关模块和网上的例子来看,有个别的“陷阱”造成调用shell 脚本在某些特殊的场景下,有一些奇奇怪怪的bug。大家且听我一一道来。先看看网上搜索到的例子:package someTest;import java.io.BufferedReader;import ja...原创 2019-05-30 19:18:47 · 477 阅读 · 0 评论 -
Hbase建表压缩(snappy)和phoenix映射关系建立
修改表压缩格式步骤:1.disable 相关表disable ‘hbase_dev_pi_b_2015’ 未压缩前 占空间大小 3.2T2.修改表的压缩格式需要一个列族一个列族修改 (如果有多个列族的话)写错,则新添加了列族,可以将其删除alter ‘hbase_dev_pi_b_2015’,{NAME=>‘f’,METHOD=>‘delete’}<“pi”....原创 2019-05-31 22:58:53 · 2401 阅读 · 2 评论 -
Cloudera Manager(CDH5)内部结构、功能包括配置文件、目录位置等
Cloudera Manager(CDH5)内部结构、功能包括配置文件、目录位置等相关目录 /var/log/cloudera-scm-installer : 安装日志目录。/var/log/* : 相关日志文件(相关服务的及CM的)。/usr/share/cmf/ : 程序安装目录。/usr/lib64/cmf/ : Agent程序代码。/var/lib/cloudera-scm-...原创 2019-07-04 12:29:32 · 313 阅读 · 0 评论 -
CDH集群异常关闭导致zookeeper启动失败
集群异常关闭后,有个zookeeper节点始终无法启动,CM上的日志没有明显的报错解决思路:1.尝试通过命令行启动zkServer.sh start,查看zookeeper.out,发现报如下错误Unexpected exception, exiting abnormallyjava.io.EOFException at java.io.DataInputStream.r...原创 2019-07-09 17:08:07 · 3063 阅读 · 4 评论 -
mysql、mariadb解决无法远程客户端连接
mysql、mariadb解决无法远程客户端连接1。 改表法。可能是你的帐号不允许从远程登陆,只能在localhost。这个时候只要在localhost的那台电脑,登入mysql后,更改 “mysql” 数据库里的 “user” 表里的 “host” 项,从"localhost"改称"%"mysql -u root -pvmwaremysql>use mysql;mysql>up...原创 2019-07-02 14:23:18 · 2856 阅读 · 0 评论 -
服务器Centos 安装详细图解(亲测)
一、安装环境,Centos7.5.双子星、刀片机服务器服务器开机,在开机后快速多次按发F11,如下图所示:按F11,进入BIOS模式。稍等片刻后,出现如下图所示按照上图选择下一步(其中需要等待不定时间)两者选一,我选择1接下来会出现以下画面等一段时间后,进入Centos 安装正式界面打开以太网络磁盘分区按照下图所示开始添...原创 2019-07-01 23:27:05 · 2890 阅读 · 0 评论 -
CentOS 7 安装 MariaDB 替代了默认的 MySQL
CentOS 6 或早期的版本中提供的是 MySQL 的服务器/客户端安装包,但 CentOS 7 已使用了 MariaDB 替代了默认的 MySQL。MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可 MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MySQL的代替品。Linux下安装MariaDB官方文档参见:官网地址全...原创 2019-06-25 18:24:50 · 538 阅读 · 0 评论