from bs4 import BeautifulSoup
import openpyxl
from openpyxl.styles import Alignment
from faker import Faker
import openpyxl
import requests
import bs4
import re
import pandas as pd
import re
workbook = openpyxl.Workbook()
# 创建第一个工作表
worksheet = workbook.active
worksheet.title = "豆瓣电影排行榜"
worksheet.merge_cells('A1:D1')
# 设置合并后的单元格居中对齐
merged_cell = worksheet['A1']
merged_cell.alignment = Alignment(horizontal='center')
# 第一行:某某乡(镇、街道)城镇独生子女父母年老奖励扶助对象年审花名册
title_cell = worksheet.cell(row=1, column=1, value="豆瓣电影排行榜")
title_cell.alignment = Alignment(horizontal='center') # 居中对齐
# 写入表头数据
header = [
"序号", "电影名称", "地址", "评价"
]
worksheet.append(header)
url="https://movie.douban.com/top250?start=150"
headers ={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'}
resp=requests.get(url,headers=headers).text
# 解析HTML文档
soup = BeautifulSoup(resp, 'html.parser')
inq_tags = soup.find_all('span', class_='inq')
# 获取每个标签的文本内容
tag_dict=[]
alt_dict=[]
src_dict=[]
for tag in inq_tags:
tag_dict.append(tag.get_text())
img_tags = soup.find_all('img')
for img in img_tags:
alt_dict.append(img.get('alt'))
src_dict.append(img.get('src'))
# 写入具体数据
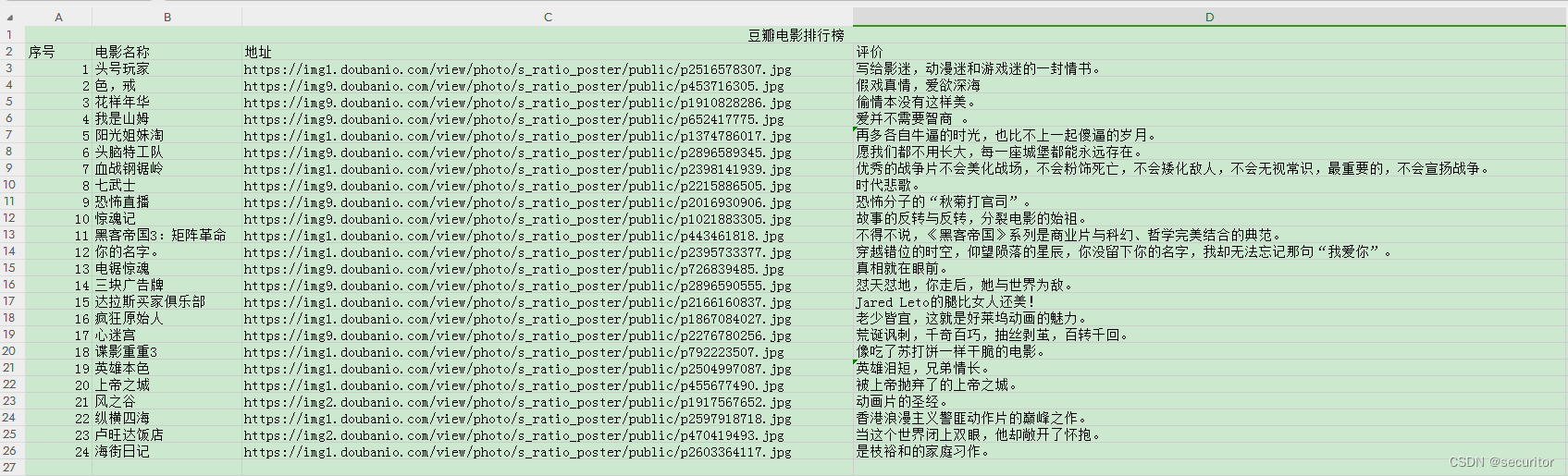
for i in range(1, 25):
data_row = [i, alt_dict[i], src_dict[i], tag_dict[i] ]
worksheet.append(data_row)
# 保存工作簿到文件
workbook.save("top_24.xlsx")








 本文介绍了如何使用Python库如BeautifulSoup和openpyxl爬取豆瓣电影排行榜数据,包括HTML解析、数据抓取和Excel文件的保存过程。
本文介绍了如何使用Python库如BeautifulSoup和openpyxl爬取豆瓣电影排行榜数据,包括HTML解析、数据抓取和Excel文件的保存过程。

















 2111
2111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









