




数据清洗与预处理的必要性
在实际数据挖掘过程中,我们拿到的初始数据,往往存在缺失值、重复值、异常值或者错误值,通常这类数据被称为“脏数据”,需要对其进行清洗。另外有时数据的原始变量不满足分析的要求,我们需要先对数据进行一定的处理,也就是数据的预处理。数据清洗和预处理的主要目的是提高数据质量,从而提高挖掘结果的可靠度,这是数据挖掘过程中非常必要的一个步骤。
具体内容
数据集:Chipotle 快餐数据,具有5列数据,分别为:order_id,quantity,item_name,choice_description和item_price
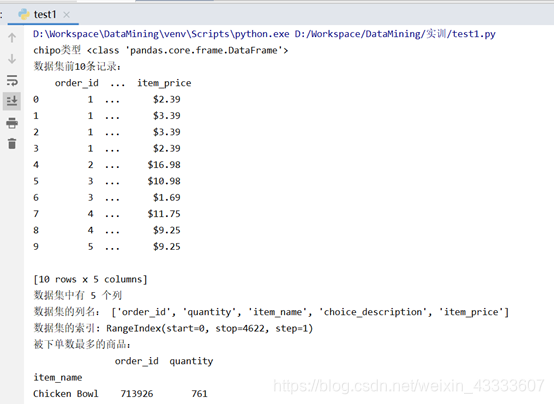
1. 将数据集存入一个名为 chipo 的数据框内。
2. 查看前 10 行内容。
3. 数据集中有多少个列(columns)?
4. 打印出全部的列名称。
5. 数据集的索引是怎样的?
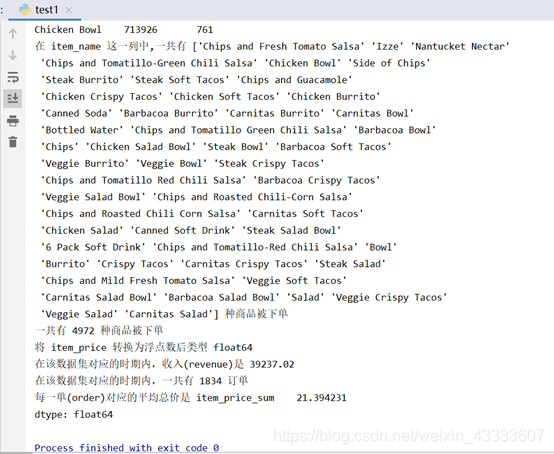
6. 被下单数最多商品(item)是什么?
7. 在 item_name 这一列中,一共有多少种商品被下单?
8. 一共有多少个商品被下单?
9. 将 item_price 转换为浮点数。
10. 在该数据集对应的时期内,收入(revenue)是多少?
11. 在该数据集对应的时期内,一共有多少订单?
12. 每一单(order)对应的平均总价是多少?
import pandas as pd
iris_filename = 'chipotle.csv'
chipo = pd.read_csv(iris_filename, sep=',', decimal='.')
print("chipo类型",type(chipo))
print("数据集前10条记录:\n",chipo.head(10))
print("数据集中有",chipo.shape[1],"个列")
print("数据集的列名:",list(chipo))
print("数据集的索引:",chipo.index)
c = chipo.groupby('item_name')
c = c.sum()
# print(c)
c = c.sort_values(['quantity'],ascending = False)
print("被下单数最多的商品:\n",c.head(1))
print("在 item_name 这一列中,一共有",chipo['item_name'].unique(),"种商品被下单")
print("一共有",chipo['quantity'].sum(),"种商品被下单")
chipo['item_price'] = chipo['item_price'].apply(lambda x: float(x[1:]))
#打印一下类型是否成功转化
print("将 item_price 转换为浮点数后类型",chipo.item_price.dtype)
print("在该数据集对应的时期内,收入(revenue)是",(chipo['quantity'] * chipo['item_price']).sum())
print("在该数据集对应的时期内,一共有",chipo['order_id'].nunique(),"订单")
chipo['item_price_sum'] = chipo['quantity'] * chipo['item_price']
print("每一单(order)对应的平均总价是",(chipo[['order_id','item_price_sum']].groupby(by=['order_id']).sum()).mean())
 实验结果分析:
实验结果分析:
首先将数据集转化为数据框格式,type(chipo)可查看chipo的数据格式,chipo.head(10)可查出数据的前10条记录,chipo.shape查看数据的形状,第一个参数表示行的个数,第二个参数表示列的个数,list(chipo)查看列名集合,chipo.index查看数据的索引,另外,结合具体数据得出其他结果,例如总金额等于总数量与单价的乘积等。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











