







 本文详细介绍MaskRCNN的工作原理,从FasterRCNN出发,引入ResNet-FPN进行特征提取,并加入Mask预测分支实现实例分割。重点讲解了多尺度检测的重要性及ROIAlign如何提升检测精度。
本文详细介绍MaskRCNN的工作原理,从FasterRCNN出发,引入ResNet-FPN进行特征提取,并加入Mask预测分支实现实例分割。重点讲解了多尺度检测的重要性及ROIAlign如何提升检测精度。
文章内容来源于以下两篇文章的整合
Mask RCNN: https://zhuanlan.zhihu.com/p/37998710
Faster RCNN: https://zhuanlan.zhihu.com/p/31426458
https://zhuanlan.zhihu.com/p/63083743 (参考 https://zhuanlan.zhihu.com/p/37998710 https://zhuanlan.zhihu.com/p/40314107)
https://www.huaweicloud.com/articles/402bfeced699b619934c9c7face284c9.html
https://hellozhaozheng.github.io/z_post/PyTorch-MaskrcnnBenchmark-modeling-backbone/#generalized_rcnn
==========================================================================
Mask RCNN沿用了Faster RCNN的思想,特征提取采用ResNet-FPN的架构,另外多加了一个Mask预测分支。可见Mask RCNN综合了很多此前优秀的研究成果。为了更好地讲解Mask RCNN,我会先回顾一下几个部分:
Faster RCNN
ResNet-FPN
ResNet-FPN+Fast RCNN
回顾完之后讲ResNet-FPN+Fast RCNN+Mask,实际上就是Mask RCNN。
我们简单地列举一下用到的缩写称呼:
FPN : Feature Pyramid Network
RPN: Region Proposal Network
RoI: Region of Interest
一、Faster RCNN
Faster RCNN是两阶段的目标检测算法,包括阶段一的Region proposal以及阶段二的bounding box回归和分类。用一张图来直观展示Faster RCNN的整个流程:
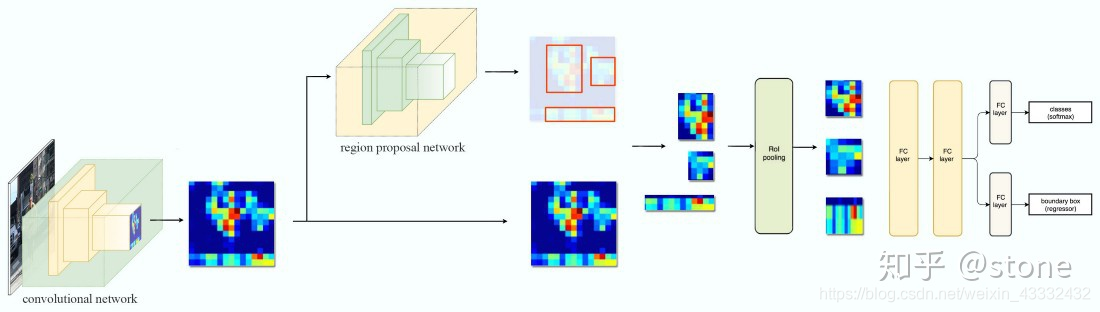
Faster RCNN使用CNN提取图像特征,然后使用region proposal network(RPN)去提取出ROI,然后使用ROI pooling将这些ROI全部变成固定尺寸,再喂给全连接层进行Bounding box回归和分类预测。
二、ResNet-FPN
多尺度检测在目标检测中变得越来越重要,对小目标的检测尤其如此。现在主流的目标检测方法很多都用到了多尺度的方法,包括最新的yolo v3。Feature Pyramid Network (FPN)则是一种精心设计的多尺度检测方法,下面就开始简要介绍FPN。
FPN结构中包括自下而上,自上而下和横向连接三个部分,如下图所示。这种结构可以将各个层级的特征进行融合,使其同时具有强语义信息和强空间信息,在特征学习中算是一把利器了。
FPN实际上是一种通用架构,可以结合各种骨架网络使用,比如VGG,ResNet等。Mask RCNN文章中使用了ResNNet-FPN网络结构。如下图:
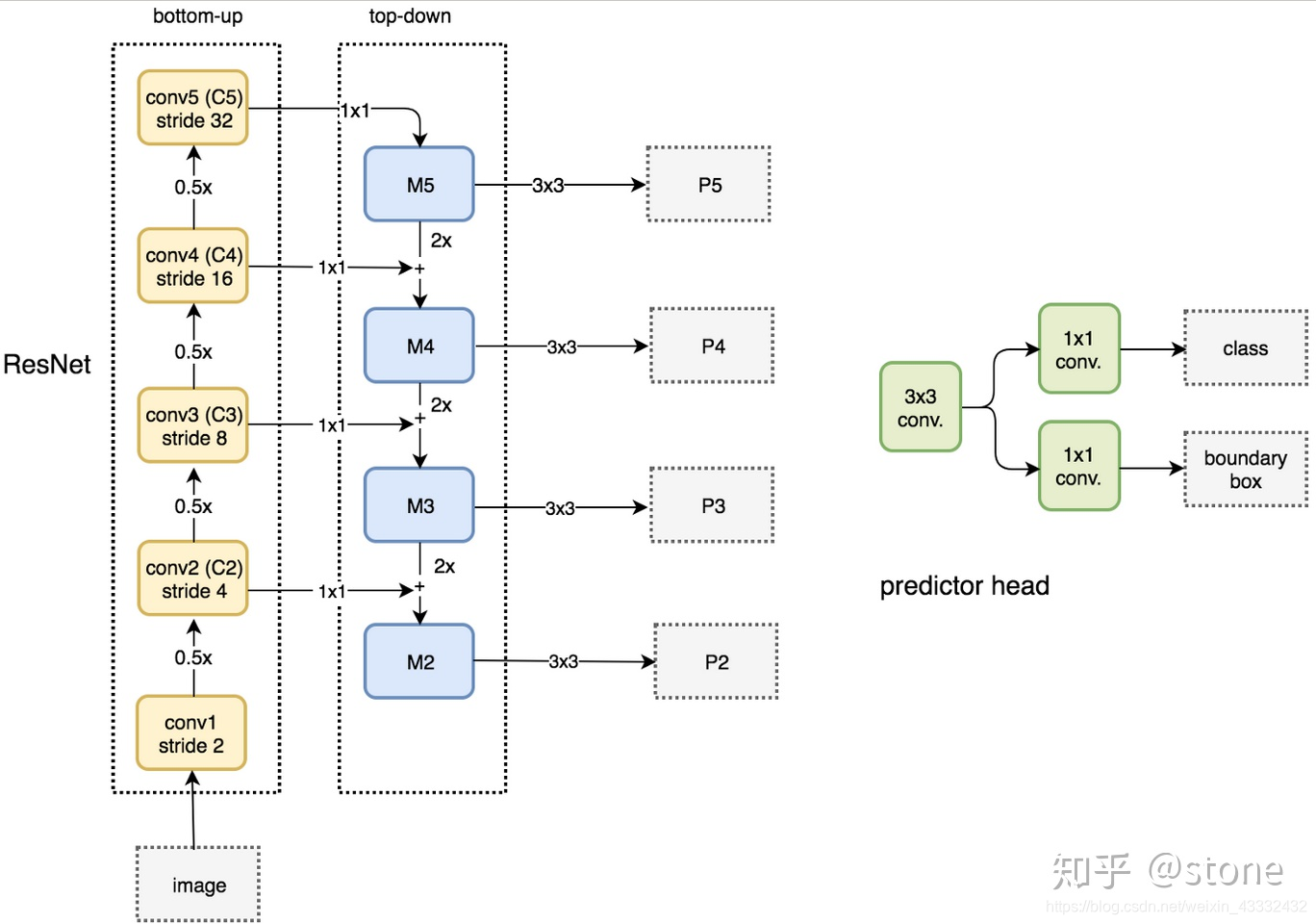
ResNet-FPN包括3个部分,自下而上连接,自上而下连接和横向连接。下面分别介绍。

对FPN的补充介绍:
FPN (Feature Pyramid Network)
https://zhuanlan.zhihu.com/p/110194701
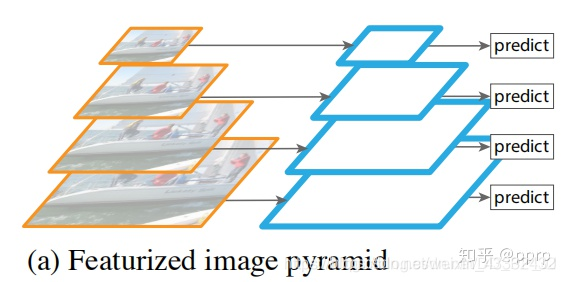
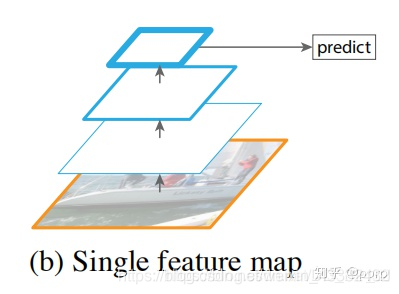
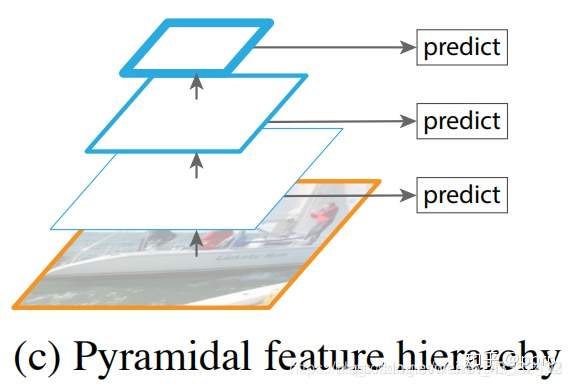
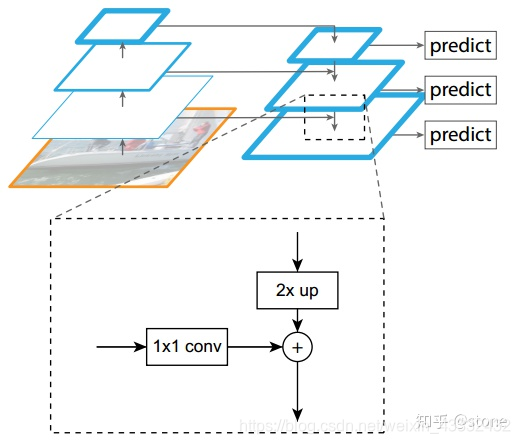
上图进行了在不同大小的feature map上分别进行预测,具有了多尺度预测的能力,但是特征与特征之间没有融合,遵从这种架构的经典的目标检测架构就是SSD, SSD用了非常多的尺度来进行检测。
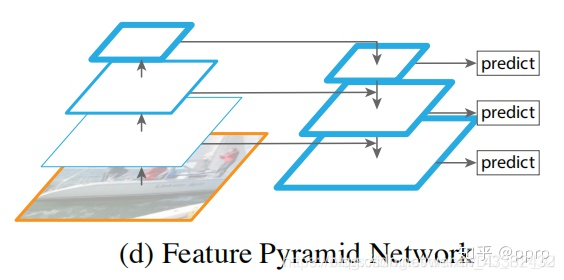
然后就是非常经典的FPN架构
图像backbone部分每个层feature map用 Ci 来标记,图像右侧的top-down结构每个feature map用 Pi 来标记。 比如说 P3 代表对应 C3 大小的feature map. 最终 P3 是通过 P4 上采样结果和 C3 进行element wise add得到的结果。 简单来说就是,FPN结构在特征与特征之间融合的基础上进行多尺度预测。
**那么为什么FPN采用融合以后效果要比使用pyramidal feature hierarchy这种方式要好呢?**有以下几个原因:
卷积虽然能够高效地向上提取语义,但是也存在像素错位问题,通过上采样还原特征图的方式很好地缓解了像素不准的问题。
backbone可以分为浅层网络和深层网络,浅层网络负责提取目标边缘等底层特征,而深层网络可以构建高级的语义信息,通过使用FPN这种方式,让深层网络更高级语义的部分的信息能够融合到稍浅层的网络,指导浅层网络进行识别。
从感受野的角度思考,浅层特征的感受野比较小,深层网络的感受野比较大,浅层网络主要负责小目标的检测,深层的网络负责大目标的检测(比如人脸检测中的SSH就使用到了这个特点)。在之前发了一篇讲感受野和目标检测的文章中提到了理论感受野和实际感受野,如下图所示:

黑色的框是理论感受野,中心呈高斯分布的亮点是实际感受野,FPN中的top-down之路通过融合不同感受野,两个高斯分布的实际感受野进行融合,能够让高层加强低层所对应的感受野。
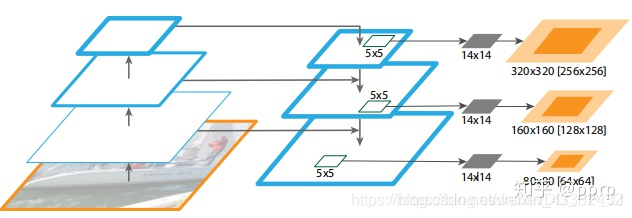
这张图讲的是FPN应用在DeepMask中做实例分割,其中使用了一个5×5的多层感知机来生成一个14×14的分割结果。对应的浅橙色的区域代表的是对应到原图的区域(与理论感受野相似),深橙色区域对应的是典型的目标区域(与实际感受野类似),观察这个图我们可以得到几个结论:
1)网络越深、特征图越小对应到原图的范围也就越大。这也就可以解释为什么加上FPN以后,小目标的效果提升了,比如在上图的 P3 到P5 中,P3 对应的目标区域要小一些,更符合小目标的大小。
2)在同一层中,理论感受野的范围要大于实际感受野
三、ResNet-FPN+Fast RCNN
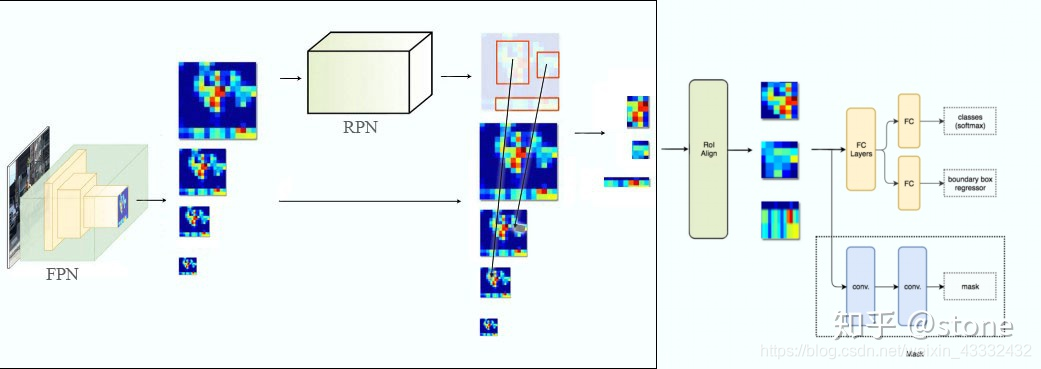

四、ResNet-FPN+Fast RCNN+mask
我们再进一步,将ResNet-FPN+Fast RCNN+mask,则得到了最终的Mask RCNN,如下图:
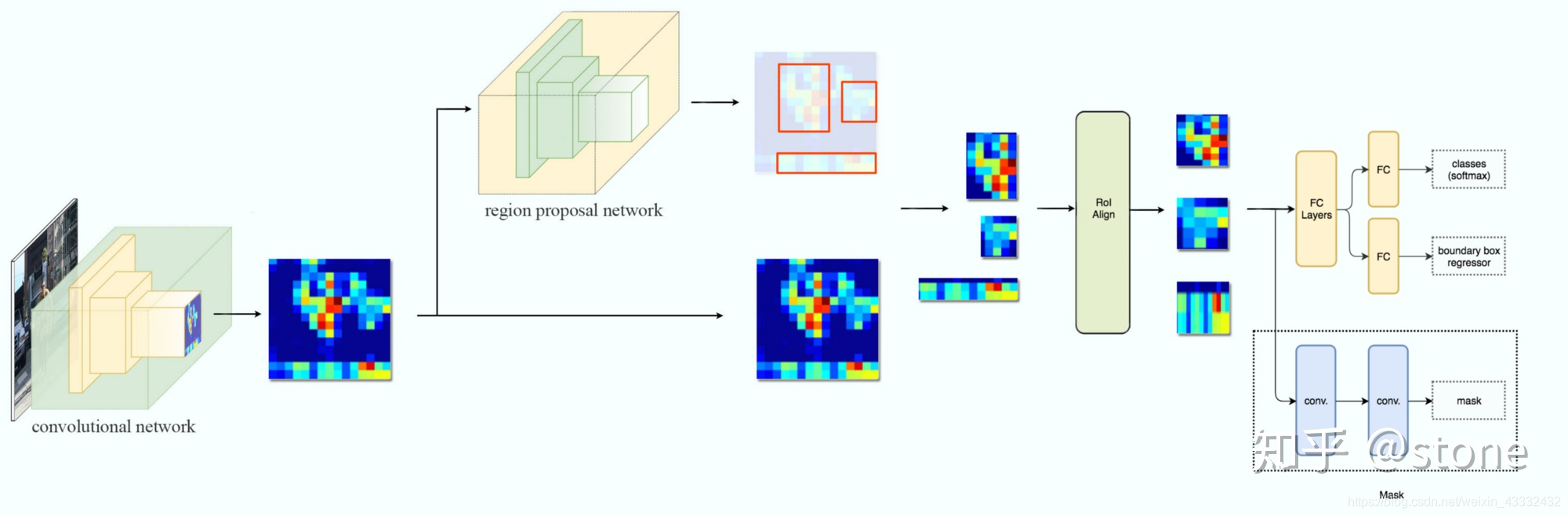
Mask RCNN的构建很简单,只是在ROI pooling(实际上用到的是ROIAlign,后面会讲到)之后添加卷积层,进行mask预测的任务。
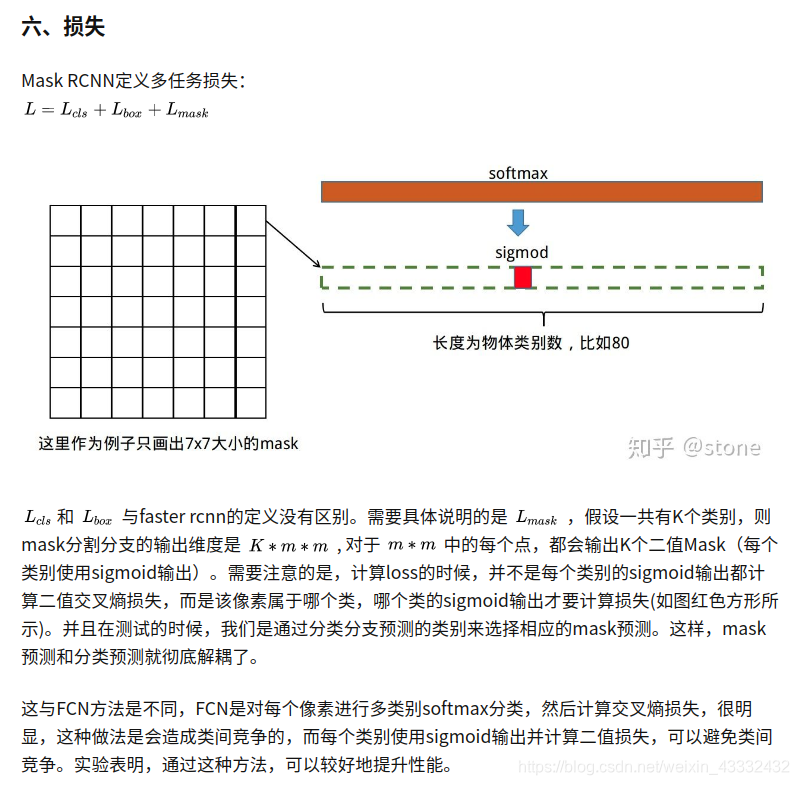
下面总结一下Mask RCNN的网络:
骨干网络ResNet-FPN,用于特征提取,另外,ResNet还可以是:ResNet-50,ResNet-101,ResNeXt-50,ResNeXt-101;
头部网络,包括边界框识别(分类和回归)+mask预测。头部结构见下图:
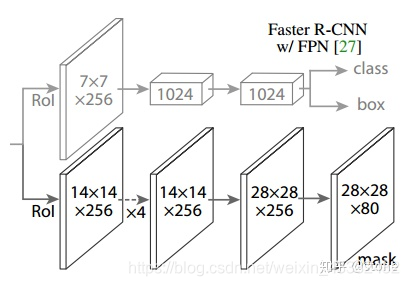
五、ROI Align
实际上,Mask RCNN中还有一个很重要的改进,就是ROIAlign。Faster R-CNN存在的问题是:特征图与原始图像是不对准的(mis-alignment),所以会影响检测精度。而Mask R-CNN提出了RoIAlign的方法来取代ROI pooling,RoIAlign可以保留大致的空间位置。
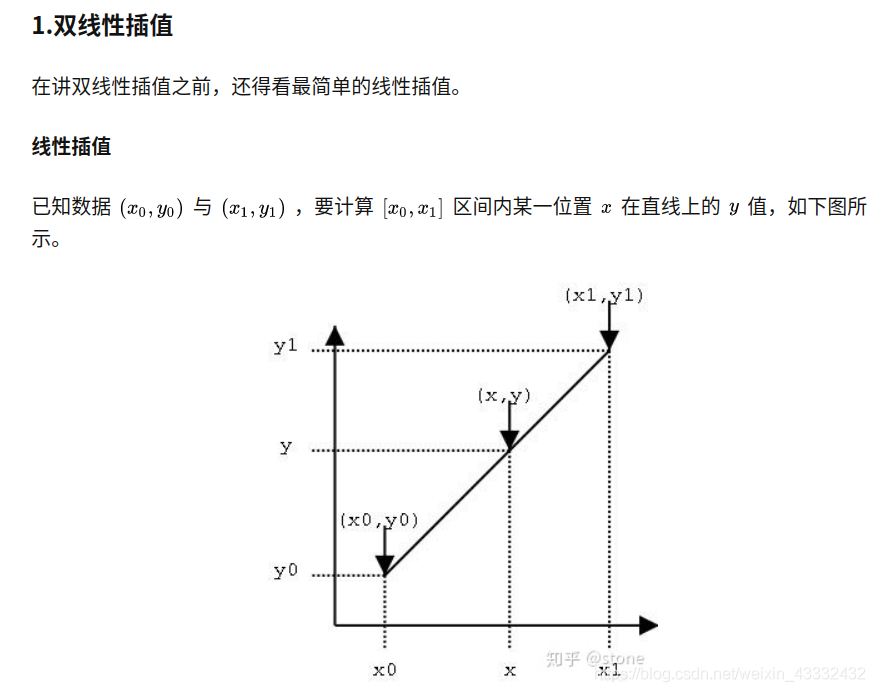
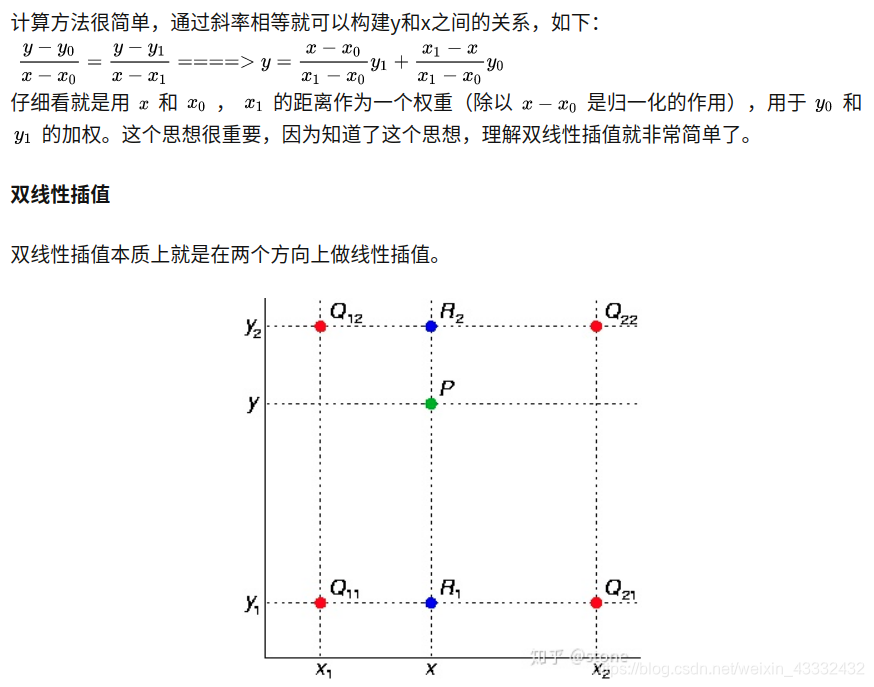
为了讲清楚ROI Align,这里先插入两个知识,双线性插值和ROI pooling。

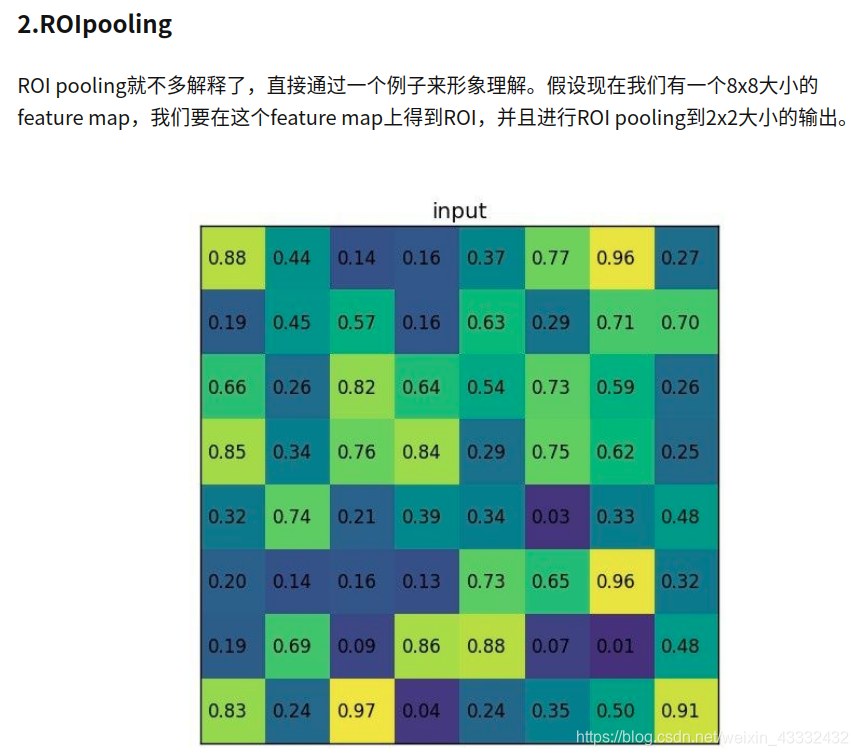
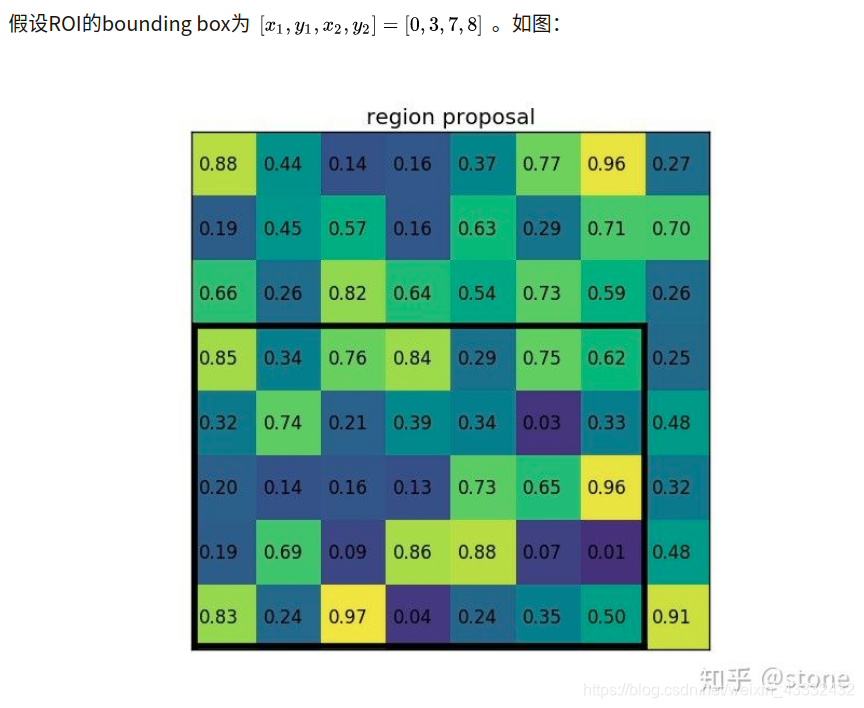
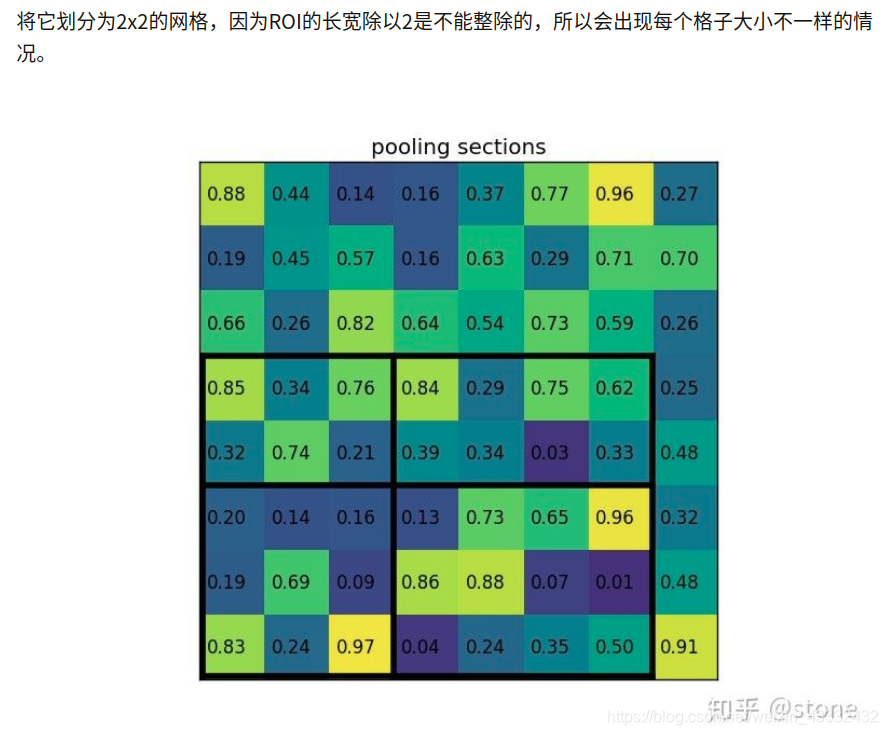
3. ROI Align
在Faster RCNN中,有两次整数化的过程:
region proposal的xywh通常是小数,但是为了方便操作会把它整数化。
将整数化后的边界区域平均分割成 k x k 个单元,对每一个单元的边界进行整数化。
两次整数化的过程如下图所示:
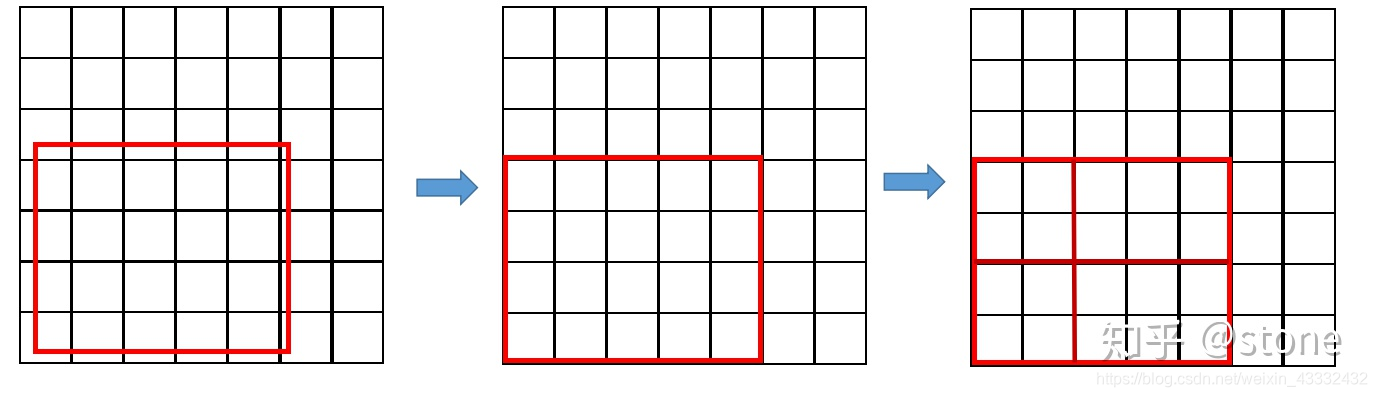
事实上,经过上述两次整数化,此时的候选框已经和最开始回归出来的位置有一定的偏差,这个偏差会影响检测或者分割的准确度。在论文里,作者把它总结为“不匹配问题”(misalignment)。
为了解决这个问题,ROI Align方法取消整数化操作,保留了小数,使用以上介绍的双线性插值的方法获得坐标为浮点数的像素点上的图像数值。但在实际操作中,ROI Align并不是简单地补充出候选区域边界上的坐标点,然后进行池化,而是重新进行设计。
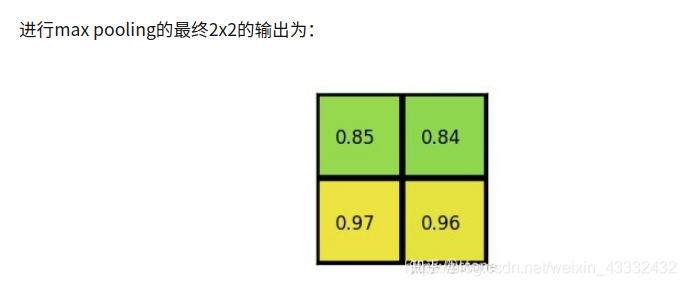
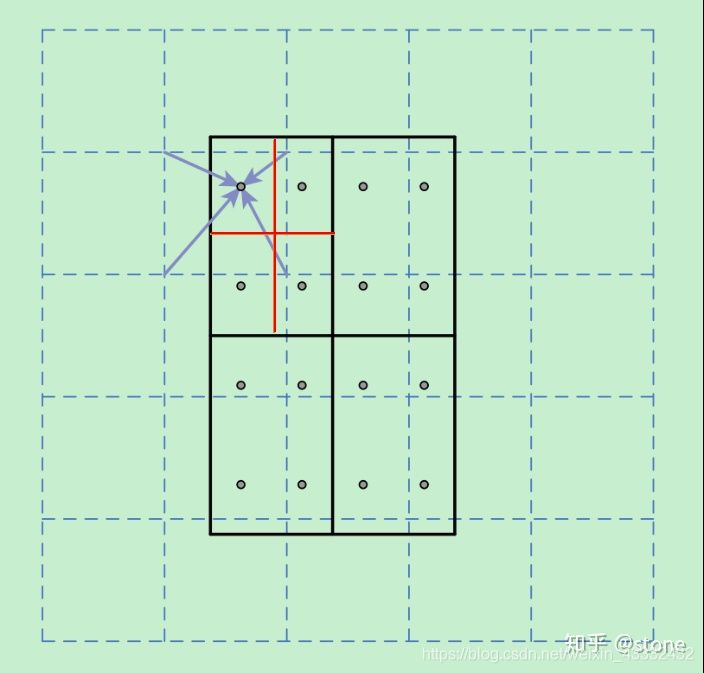
下面通过一个例子来讲解ROI Align操作。如下图所示,虚线部分表示feature map,实线表示ROI,这里将ROI切分成2x2的单元格。如果采样点数是4,那我们首先将每个单元格子均分成四个小方格(如红色线所示),每个小方格中心就是采样点。这些采样点的坐标通常是浮点数,所以需要对采样点像素进行双线性插值(如四个箭头所示),就可以得到该像素点的值了。然后对每个单元格内的四个采样点进行maxpooling,就可以得到最终的ROIAlign的结果。
需要说明的是,在相关实验中,作者发现将采样点设为4会获得最佳性能,甚至直接设为1在性能上也相差无几。事实上,ROI Align 在遍历取样点的数量上没有ROIPooling那么多,但却可以获得更好的性能,这主要归功于解决了misalignment的问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









