



 本文深入探讨RHCS高可用集群的三大核心功能:高可用性、负载均衡和存储集群,详细介绍了RHCS的组件、架构和运行原理,包括CMAN、DLM、CCS、FENCE等关键机制,以及如何通过LUCI配置和管理集群,实现服务故障转移和资源共享。
本文深入探讨RHCS高可用集群的三大核心功能:高可用性、负载均衡和存储集群,详细介绍了RHCS的组件、架构和运行原理,包括CMAN、DLM、CCS、FENCE等关键机制,以及如何通过LUCI配置和管理集群,实现服务故障转移和资源共享。
RHCS高可用套件
1、RHCS提供的三个核心功能
高可用集群是RHCS的核心功能。当应用程序出现故障,或者系统硬件、网络出现故障时,应用可以通过RHCS提供的高可用性服务管理组件自动、快速从一个节点切换到另一个节点,节点故障转移功能对客户端来说是透明的,从而保证应用持续、不间断的对外提供服务,这就是RHCS高可用集群实现的功能。
RHCS通过LVS(Linux Virtual Server)来提供负载均衡集群,而LVS是一个开源的、功能强大的基于IP的负载均衡技术,LVS由负载调度器和服务访问节点组成,通过LVS的负载调度功能,可以将客户端请求平均的分配到各个服务节点,同时,还可以定义多种负载分配策略,当一个请求进来时,集群系统根据调度算法来判断应该将请求分配到哪个服务节点,然后,由分配到的节点响应客户端请求,同时,LVS还提供了服务节点故障转移功能,也就是当某个服务节点不能提供服务时,LVS会自动屏蔽这个故障节点,接着将失败节点从集群中剔除,同时将新来此节点的请求平滑的转移到其它正常节点上来;而当此故障节点恢复正常后,LVS又会自动将此节点加入到集群中去。而这一系列切换动作,对用户来说,都是透明的,通过故障转移功能,保证了服务的不间断、稳定运行。
RHCS通过GFS文件系统来提供存储集群功能,GFS是Global FileSystem的缩写,它允许多个服务同时去读写一个单一的共享文件系统,存储集群通过将共享数据放到一个共享文件系统中从而消除了在应用程序间同步数据的麻烦,GFS是一个分布式文件系统,它通过锁管理机制,来协调和管理多个服务节点对同一个文件系统的读写操作。 现在用的最多的是gfs2版本,GFS文件系统必须运行在集群上。
2、RHCS集群组成
RHCS是一个集群工具的集合,主要有下面几大部分组成:
- 集群构架管理器
RHCS集群的一个基础套件,提供一个集群的基本功能,使各个节点组成集群在一起工作,具体包含分布式集群管理器(CMAN)、成员关系管理、锁管理(DLM)、配置文件管理(CCS)、栅设备(FENCE)。
- 高可用服务管理器
提供节点服务监控和服务故障转移功能,当一个节点服务出现故障时,将服务转移到另一个健康节点。
- 集群配置管理工具
RHCS最新版本通过LUCI来配置和管理RHCS集群,LUCI是一个基于web的集群配置方式,通过LUCI可以轻松的搭建一个功能强大的集群系统。 节点主机可以使用RICCI来和LUCI管理端进行通信。
- Linux Virtual Server
LVS是一个开源的负载均衡软件,利用LVS可以将客户端的请求根据指定的负载策略和算法合理的分配到各个服务节点,实现动态、智能的负载分担。
RHCS除上面的几个核心构成,还可以通过下面组件来补充RHCS集群功能。
- RedHatGFS(Global FileSystem)
GFS是Redhat公司开发的一款集群文件系统,目前的最新版本是GFS2,GFS文件系统允许多个服务同时读写一个磁盘分区,通过GFS可以实现数据的集中管理,免去了数据同步和拷贝的麻烦,但GFS并不能孤立的存在,安装GFS需要RHCS的底层组件支持。
- Cluster Logical Volume Manager
Cluster逻辑卷管理,即CLVM,是LVM的扩展,这种扩展允许cluster中的机器使用LVM来管理共享存储。
- ISCSI
ISCSI是一种在Internet协议上,特别是以太网上进行数据块传输的标准,它是一种基于IPStorage理论的新型存储技术,RHCS可以通过ISCSI技术来导出和分配共享存储的使用。
RHCS集群结构
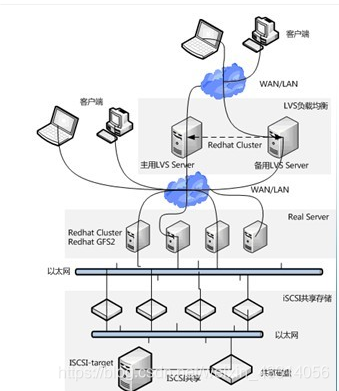
最上层是LVS负载均衡层,中间一层是RealServer层,就是服务节点部分,最后一层是共享存储层,主要用于给GFS文件系统提供共享存储空间。
RHCS集群运行原理及功能介绍
- 分布式集群管理器(CMAN)
Cluster Manager,简称CMAN,是一个分布式集群管理工具,它运行在集群的各个节点上,为RHCS提供集群管理任务。CMAN用于管理集群成员、消息和通知。它通过监控每个节点的运行状态来了解节点成员之间的关系,当集群中某个节点出现故障,节点成员关系将发生改变,CMAN及时将这种改变通知底层,进而做出相应的调整。
- 锁管理(DLM)
Distributed Lock Manager,简称DLM,表示一个分布式锁管理器,它是RHCS的一个底层基础构件,同时也为集群提供了一个公用的锁运行机制,在RHCS集群系统中,DLM运行在集群的每个节点上,GFS通过锁管理器的锁机制来同步访问文件系统元数据。CLVM通过锁管理器来同步更新数据到LVM卷和卷组。 DLM不需要设定锁管理服务器,它采用对等的锁管理方式,大大的提高了处理性能。同时,DLM避免了当单个节点失败需要整体恢复的性能瓶颈,另外,DLM的请求都是本地的,不需要网络请求,因而请求会立即生效。最后,DLM通过分层机制,可以实现多个锁空间的并行锁模式。
- 配置文件管理(CCS)
Cluster Configuration System,简称CCS,主要用于集群配置文件管理和配置文件在节点之间的同步。有时候,LUCI管理界面可能由于网络等方面的以素并不是那么畅快,CCS就显得很必要了。CCS运行在集群的每个节点上,监控每个集群节点上的单一配置文件/etc/cluster/cluster.conf的状态,当这个文件发生任何变化时,都将此变化更新到集群中的每个节点,时刻保持每个节点的配置文件同步。例如,管理员在节点A上更新了集群配置文件,CCS发现A节点的配置文件发生变化后,马上将此变化传播到其它节点上去rhcs的配置文件是cluster.conf,它是一个xml文件,具体包含集群名称、集群节点信息、集群资源和服务信息、fence设备等。
- 栅设备(FENCE)
FENCE设备是RHCS集群中必不可少的一个组成部分,通过FENCE设备可以避免因出现不可预知的情况而造成的“脑裂”现象,FENCE设备的出现,就是为了解决类似这些问题,Fence设备主要就是通过服务器或存储本身的硬件管理接口,或者外部电源管理设备,来对服务器或存储直接发出硬件管理指令,将服务器重启或关机,或者与网络断开连接。 FENCE的工作原理是:当意外原因导致主机异常或者宕机时,备机会首先调用FENCE设备,然后通过FENCE设备将异常主机重启或者从网络隔离,当FENCE操作成功执行后,返回信息给备机,备机在接到FENCE成功的信息后,开始接管主机的服务和资源。这样通过FENCE设备,将异常节点占据的资源进行了释放,保证了资源和服务始终运行在一个节点上。 RHCS的FENCE设备可以分为两种:内部FENCE和外部FENCE,常用的内部FENCE有IBMRSAII卡,HP的ILO卡,还有IPMI的设备等,外部fence设备有UPS、SANSWITCH、NETWORKSWITCH等
- 高可用服务管理器
高可用性服务管理主要用来监督、启动和停止集群的应用、服务和资源。它提供了一种对集群服务的管理能力,当一个节点的服务失败时,高可用性集群服务管理进程可以将服务从这个失败节点转移到其它健康节点上来,并且这种服务转移能力是自动、透明的。RHCS通过rgmanager来管理集群服务,rgmanager运行在每个集群节点,进程为clurgmgrd。
在一个RHCS集群中,高可用性服务包含集群服务和集群资源两个方面,集群服务其实就是应用服务,例如apache、mysql等,集群资源有很多种,例如一个IP地址、一个运行脚本、ext4/GFS文件系统等。
在RHCS集群中,高可用性服务是和一个失败转移域结合在一起的
所谓失败转移域是一个运行特定服务的集群节点的集合。在失败转移域中,可以给每个节点设置相应的优先级,通过优先级的高低来决定节点失败时服务转移的先后顺序,如果没有给节点指定优先级,那么集群高可用服务将在任意节点间转移。因此,通过创建失败转移域不但可以设定服务在节点间转移的顺序,而且可以限制某个服务仅在失败转移域指定的节点内进行切换。
- 集群配置管理工具
Conga是一种新的基于网络的集群配置工具,Conga是通过web方式来配置和管理集群节点的。Conga有两部分组成,分别是luci和ricci,luci安装在一台独立的计算机上,用于配置和管理集群,ricci安装在每个集群节点上,luci通过ricci和集群中的每个节点进行通信。
RHCS也提供了一些功能强大的集群命令行管理工具,常用的有clustat、cman_tool、ccs_tool、fence_tool、clusvcadm等
- RedhatGFS
GFS是RHCS为集群系统提供的一个存储解决方案,它允许集群多个节点在块级别上共享存储,每个节点通过共享一个存储空间,保证了访问数据的一致性,更切实的说,GFS是RHCS提供的一个集群文件系统,多个节点同时挂载一个文件系统分区,而文件系统数据不受破坏,这是单一的文件系统不能实现的。为了实现多个节点对于一个文件系统同时读写操作,GFS使用锁管理器来管理I/O操作,当一个写进程操作一个文件时,这个文件就被锁定,此时不允许其它进程进行读写操作,直到这个写进程正常完成才释放锁,只有当锁被释放后,其它读写进程才能对这个文件进行操作,另外,当一个节点在GFS文件系统上修改数据后,这种修改操作会通过RHCS底层通信机制立即在其它节点上可见。 在搭建RHCS集群时,GFS一般作为共享存储,运行在每个节点上,并且可以通过RHCS管理工具对GFS进行配置和管理。这些需要说明的是RHCS和GFS之间的关系,一般初学者很容易混淆这个概念:运行RHCS,GFS不是必须的,只有在需要共享存储时,才需要GFS支持,而搭建GFS集群文件系统,必须要有RHCS的底层支持,所以安装GFS文件系统的节点,必须安装RHCS组件。
RHCS集群部署
三台主机,一台作为luci的web管理,两台ricci计算节点做HA,一台作为iscsi服务端,共享设备。(集群中ricci作为计算节点性必须做时间同步)
| host | node |
|---|---|
| 172.25.254.8 | ricci/luci |
| 172.25.254.9 | ricci web mysql |
| 172.25.254.10 | iscsi web mysql |
实验环境:Rhel6.5 关闭iptables selinux设置为disabled, Yum源:
[rhel-source]
name=Red Hat Enterprise Linux $releasever - $basearch - Source
baseurl=http://172.25.254.55/rhel6.5/
enabled=1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.254.55/rhel6.5/HighAvailability
gpgcheck=0
[LoadBalancer]
name=HighAvailability
baseurl=http://172.25.254.55/rhel6.5/LoadBalancer
gpgcheck=0
[ResilientStorage]
name=ResilientStorage
baseurl=http://172.25.254.55/rhel6.5/ResilientStorage
gpgcheck=0
[ScalableFileSystem]
name=ScalableFileSystem
baseurl=http://172.25.254.55/rhel6.5/ScalableFileSystem
gpgcheck=0
- ricci计算节点(集群之间每个主机都必须有解析)
[root@server8 ~]# yum install -y ricci luci
[root@server9 ~]# yum install -y ricci
[root@server8 ~]# /etc/init.d/ricci start
[root@server8 ~]# /etc/init.d/luci start
[root@server9 ~]# /etc/init.d/ricci start
- 登陆lcui(https://172.25.254.8:8084)端进行创建集群,并添加节点
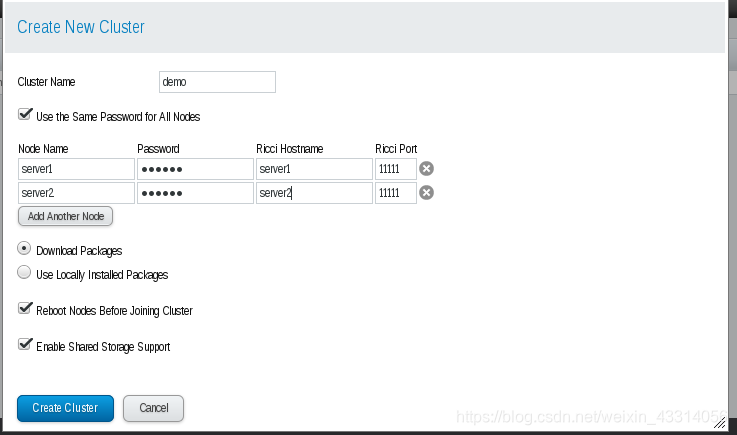
- 登陆后创建集群添加节点:
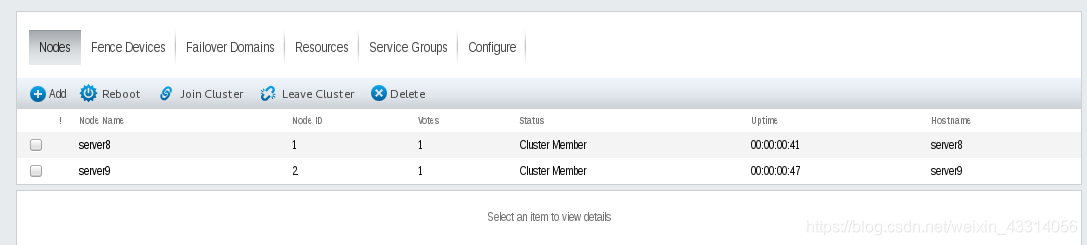
查看节点信息,下面五个进程都为running时表示集群创建成功,若其中有进程为not 如running,则重启对应的进程
clustat命令
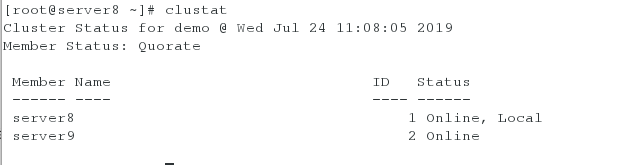
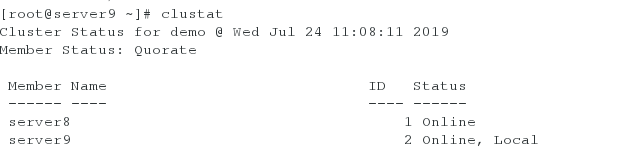
- 安装fence
解决多个节点间因为互相争夺资源而产生的脑裂问题,当某节点出现问题,会将节点立即拔电重启)
使用fence_virtd工具来生成fence的key
yum install -y fence-virtd-0.3.2-2.el7.x86_64
[root@foundation55 images]# fence_virtd -c ###交互配置fence文件
libvirt 0.1
Interface [br0]: br0 ###选择接口时选择br0,其他都默认
Replace /etc/fence_virt.conf with the above [y/N]? y
mkdir /etc/cluster默认不存在cluster目录来存放key文件,自己建立
dd if=/dev/random of=/etc/cluster/fence_xvm.key bs=128 count=1
将该文件传给集群的各个节点,用来通信
scp fence_xvm.key root@172.25.254.8:/etc/cluster/
scp fence_xvm.key root@172.25.254.9:/etc/cluster/
- 启动fence设备
netstat -anupl | grep :1229
udp 0 0 0.0.0.0:1229 0.0.0.0:* 28227/fence_virtd
- 在luci网页配置
6.1、选择多波模式
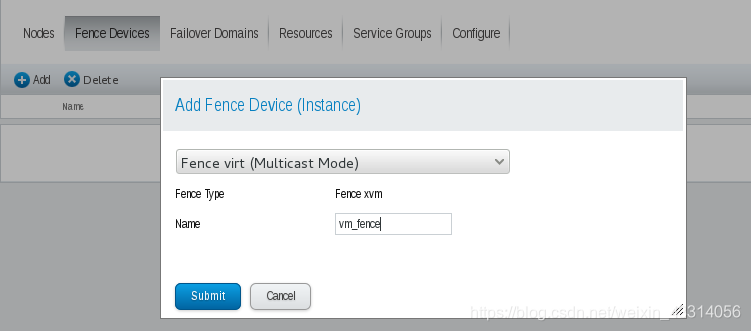
6.2、在每个node节点添加fence配置
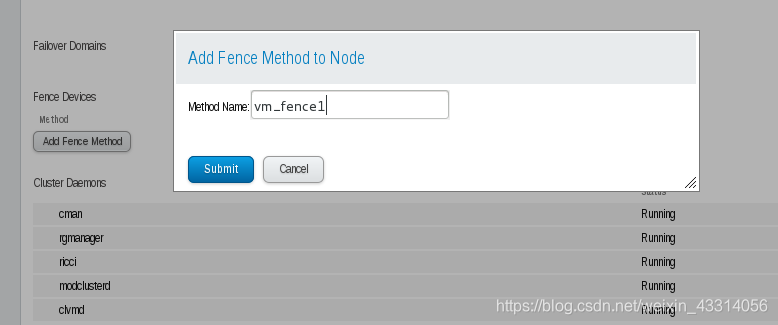
6.3、、添加fence设备,Domain这里建议使用UUID,或者也可以使用主机名
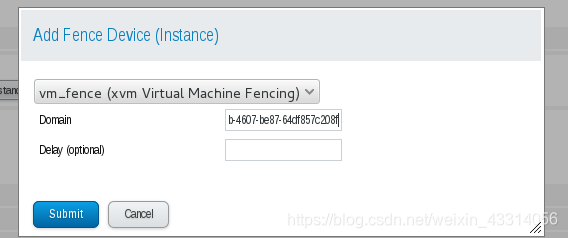
配置完成后,在主机上查看cluster.conf文件,fence设备已经成功添加
<fencedevices>
<fencedevice agent="fence_xvm" name="vm_fence"/>
</fencedevices>
测试:使用一个节点去fence另一个节点:
server8 fence_node server9,server9断电重启
7. 配置故障转换域:这里以apache为测试
故障切换域是一个命名的集群节点子集,它可在节点失败事件中运行集群服务 在由几个成员组成的集群中,使用限制故障切换域可最大程度降低设置集群以便运行集群服务的工作(比如 httpd),它要求您在运行该集群服务的所有成员中进行完全一致的配置。您不需要将整个集群设置为运行 该集群服务,只要设置与该集群服务关联的限制故障切换域中的成员即可。 故障转移域,权值越低,优先级越高
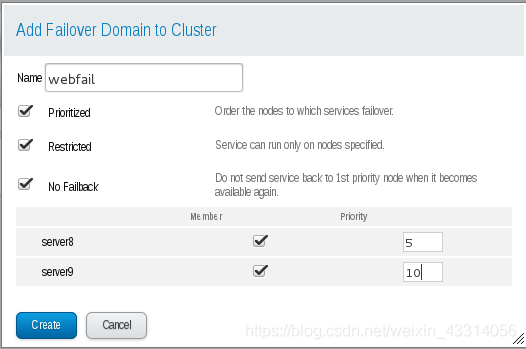
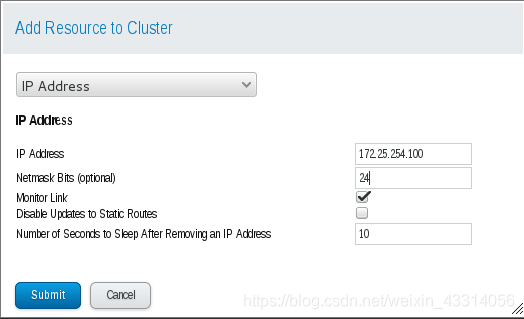
8.配置集群资源
- 添加虚拟IP
- 添加启动脚本
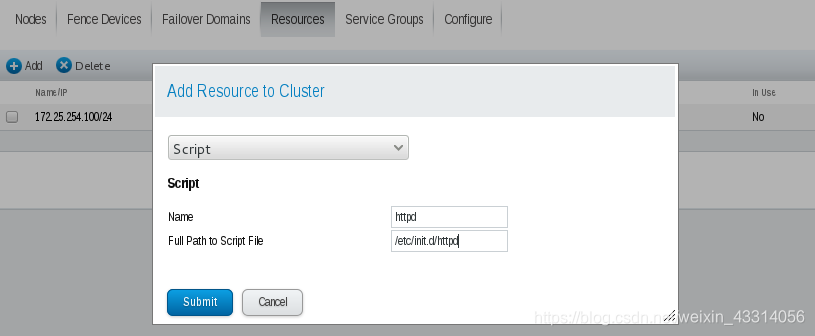
9.配置资源组:
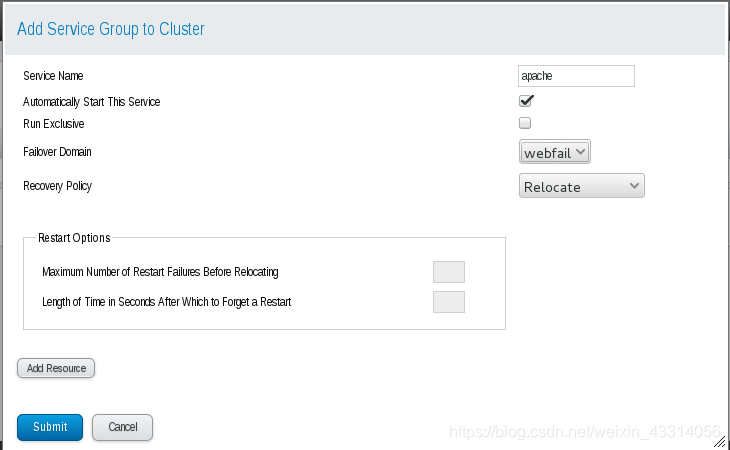
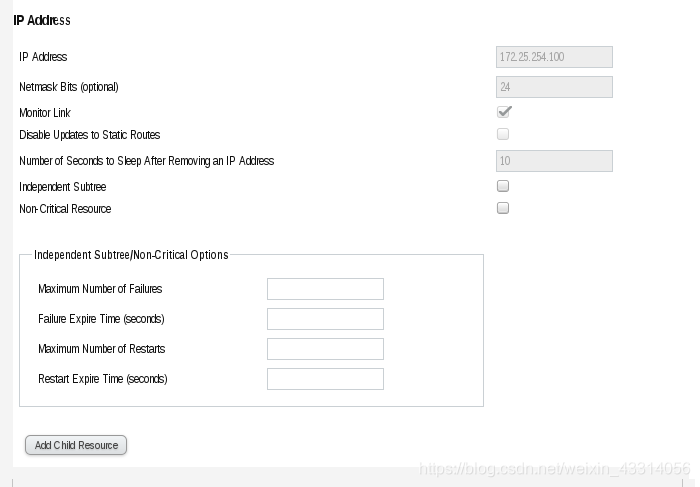
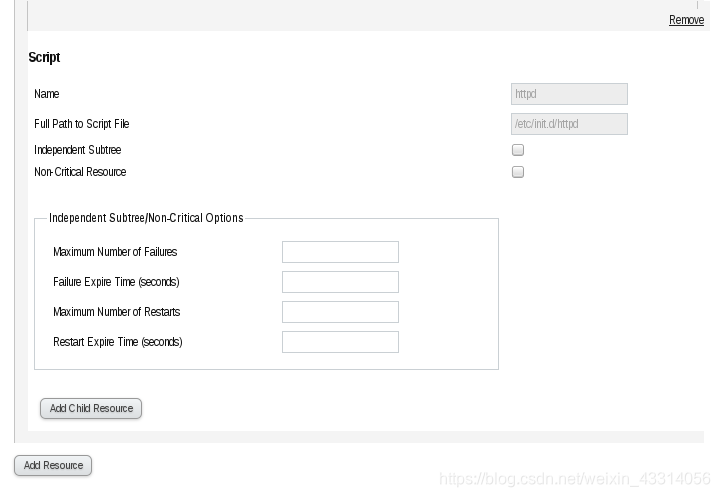
测试:
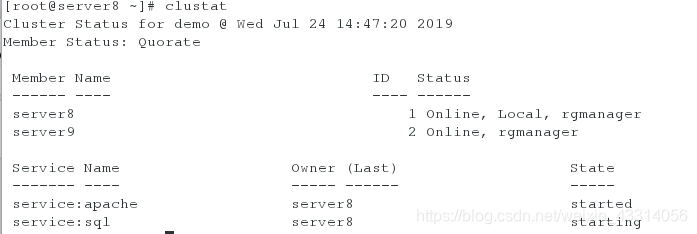
[root@server8 ~]# clustat
Cluster Status for demo @ Wed Jul 24 13:55:07 2019
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
server8 1 Online, Local, rgmanager
server9 2 Online, rgmanager
Service Name Owner (Last) State
------- ---- ----- ------ -----
service:apache server8 started
可以看到httpd已经被自动启动,而且VIP在主机1上,因为我们设置的优先级为1主机高于2主机
[root@server8 ~]# ip addr | grep eth0 | grep 172.25.254.100
inet 172.25.254.100/24 scope global secondary eth0
现在将主机1上的httpd停掉,现在2主机接管httpd服务,运行正常
[root@server9 ~]# clustat
Cluster Status for demo @ Wed Jul 24 14:00:38 2019
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
server8 1 Online, rgmanager
server9 2 Online, Local, rgmanager
Service Name Owner (Last) State
------- ---- ----- ------ -----
service:apache server9 started
而且VIP已经飘到2主机上
[root@server9 ~]# ip addr | grep eth0 | grep 172.25.254.100
inet 172.25.254.100/24 scope global secondary eth0
如果将1主机的httpd重新开启,并不会回切回去,这样做会消耗更多的资源,而且服务在不断切换可能会不稳定,造成数据丢失。
10. 数据库+iscsi共享设备:
- 在存储服务器主机上添加共享磁盘,格式化
[root@server10 ~]# yum install scsi-* -y
修改/etc/tgt/targets.conf第38行
<target iqn.2019-07.com.example:server.target1>
backing-store /dev/sdb
</target>
[root@server10 ~]# /etc/init.d/tgtd start
- 在数据库服务器安装iscsi客户端,登陆并发现设备:
root@server8 ~]# iscsiadm -m discovery -t st -p 172.25.254.10
[root@server8 ~]# iscsiadm -m node -l
- 使用前格式化磁盘:
[root@server8 ~]# mkfs.ext4 /dev/sdb
chown mysql.mysql /var/lib/mysql
- 在luci页面配置mysql管理
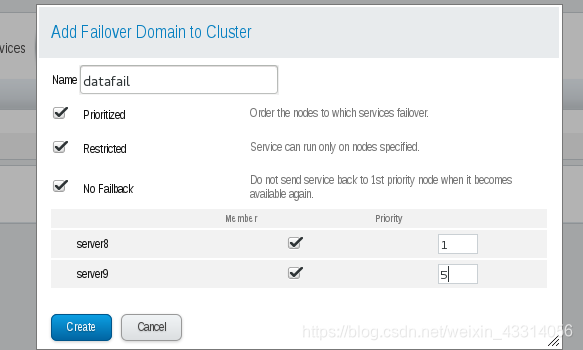
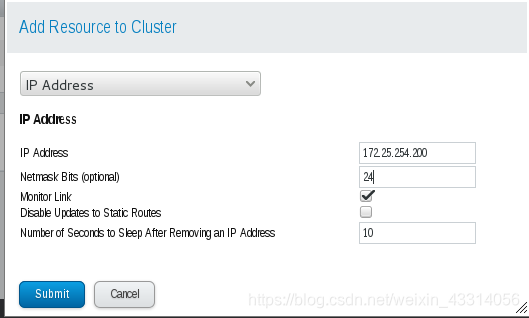
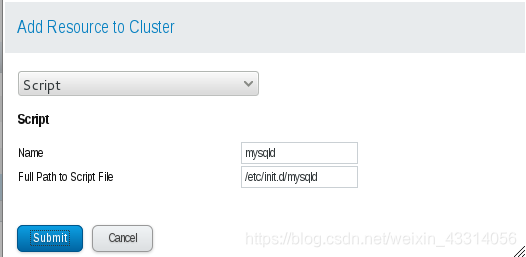
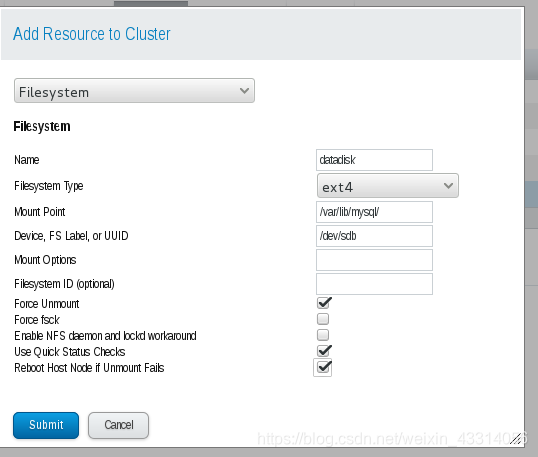
- 使用df命令也可以查看,磁盘已经挂载
11.GFS2逻辑卷组集群共享
- 创建逻辑卷组
pvcreate /dev/sdb
vgcreate clustervg /dev/sdb
lvcreate -L 3G -n clusterlv clustervg
- 格式化文件系统
mkfs.gfs2 -t demo:mygfs2 -p lock_dlm -j 2 /dev/clustervg/clusterlv
chown mysql.mysql /var/lib/mysql
- 在管理页面添加资源
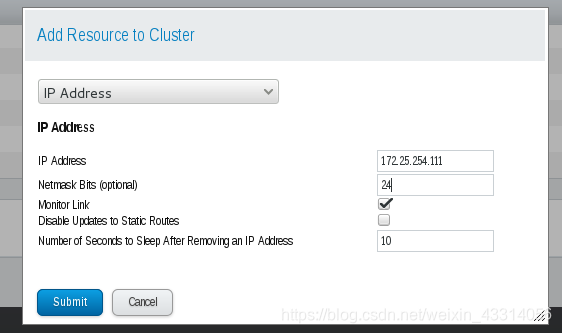
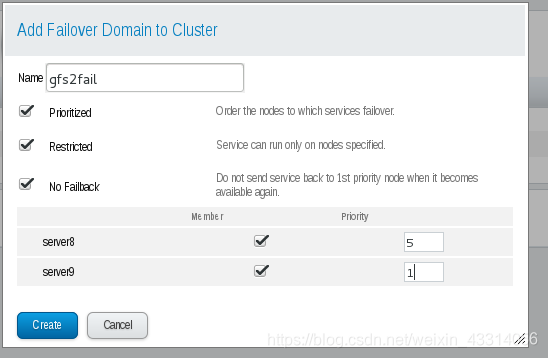
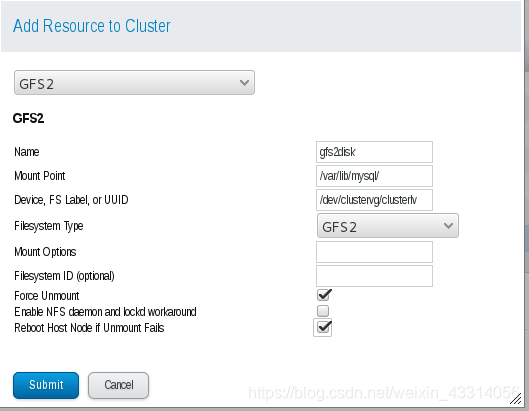
[root@server9 ~]# clustat
Cluster Status for demo @ Wed Jul 24 15:11:16 2019
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
server8 1 Online, rgmanager
server9 2 Online, Local, rgmanager
Service Name Owner (Last) State
------- ---- ----- ------ -----
service:apache server8 started
service:gfs2sql server9
clusvcadm -e sql :启动
clusvcadm -r apache -m server9:将apache转移到server9
gfs2:同时读写同一个磁盘,不能独立存在
/etc/lvm/lcm.conf
locking_type=3:支持集群,集群锁
lvmconf --enable-cluster:激活集群锁
分区表没了:备份/不分区
dd if-/dev/sdb of=mbr bs=512 count=1
dd if=/dev/zero of=/dev/sdb bs=512 count=1:删除分区表
恢复:
dd if=mbr of=/dev/sdb
##删除设备
iscsiadm -m node -T iqn.2019-07.com.example:server.target1 -p 172.25.254.22 -u
iscsiadm -m node -T iqn.2019-07.com.example:server.target1 -p 172.25.254.22 -o delete
发现设备
iscsiadm -m discovery -t st -p 172.25.254.22
iscsiadm -m node -l
测试:破坏内核
echo c > /proc/sysrq-trigger

















 956
956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









