



最近公司要读取飞书表格信息 并上传到jira自动生成任务 所以有了这个
一 创建dify
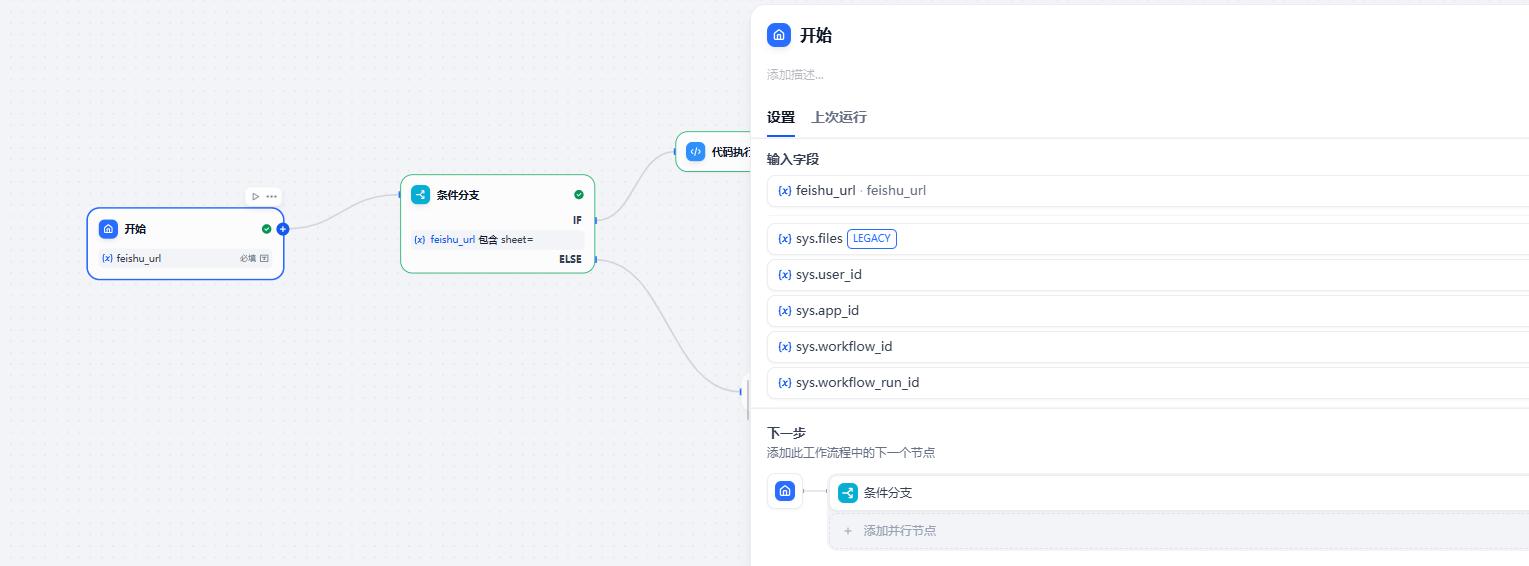
二 调用飞书(有三个变量需要自己定义 )
app_id,app_secret,url
import os
import json
import requests
import sys
import urllib.parse
from typing import Dict, Any, Tuple, List, Optional
import time
def get_tenant_access_token(app_id: str, app_secret: str) -> Tuple[str, Exception]:
"""获取 tenant_access_token
Args:
app_id: 应用ID
app_secret: 应用密钥
Returns:
Tuple[str, Exception]: (access_token, error)
"""
url = "https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal"
payload = {
"app_id": app_id,
"app_secret": app_secret
}
headers = {
"Content-Type": "application/json; charset=utf-8"
}
try:
print(f"POST: {url}")
print(f"Request body: {json.dumps(payload)}")
response = requests.post(url, json=payload, headers=headers)
response.raise_for_status()
result = response.json()
print(f"Response: {json.dumps(result)}")
if result.get("code", 0) != 0:
print(f"ERROR: failed to get tenant_access_token: {result.get('msg', 'unknown error')}", file=sys.stderr)
return "", Exception(f"failed to get tenant_access_token: {response.text}")
return result["tenant_access_token"], None
except Exception as e:
print(f"ERROR: getting tenant_access_token: {e}", file=sys.stderr)
if hasattr(e, 'response') and e.response is not None:
print(f"ERROR: Response: {e.response.text}", file=sys.stderr)
return "", e
def get_wiki_node_info(tenant_access_token: str, node_token: str) -> Dict[str, Any]:
"""获取知识空间节点信息
Args:
tenant_access_token: 租户访问令牌
node_token: 节点令牌
Returns:
Dict[str, Any]: 节点信息对象
"""
url = f"https://open.feishu.cn/open-apis/wiki/v2/spaces/get_node?token={urllib.parse.quote(node_token)}"
headers = {
"Authorization": f"Bearer {tenant_access_token}",
"Content-Type": "application/json; charset=utf-8"
}
try:
print(f"GET: {url}")
response = requests.get(url, headers=headers)
response.raise_for_status()
result = response.json()
print(f"Response: {json.dumps(result)}")
if result.get("code", 0) != 0:
print(f"ERROR: 获取知识空间节点信息失败 {result}", file=sys.stderr)
raise Exception(f"failed to get wiki node info: {result.get('msg', 'unknown error')}")
if not result.get("data") or not result["data"].get("node"):
raise Exception("未获取到节点信息")
node_info = result["data"]["node"]
print("节点信息获取成功:", {
"node_token": node_info.get("node_token"),
"obj_type": node_info.get("obj_type"),
"obj_token": node_info.get("obj_token"),
"title": node_info.get("title")
})
return node_info
except Exception as e:
print(f"ERROR: getting wiki node info: {e}", file=sys.stderr)
raise
def get_spreadsheet_info(tenant_access_token: str, spreadsheet_token: str) -> Dict[str, Any]:
"""获取电子表格信息
Args:
tenant_access_token: 租户访问令牌
spreadsheet_token: 电子表格token
Returns:
Dict[str, Any]: 电子表格信息
"""
url = f"https://open.feishu.cn/open-apis/sheets/v3/spreadsheets/{spreadsheet_token}"
headers = {
"Authorization": f"Bearer {tenant_access_token}",
"Content-Type": "application/json; charset=utf-8"
}
try:
print(f"GET: {url}")
response = requests.get(url, headers=headers)
response.raise_for_status()
result = response.json()
print(f"Response: {json.dumps(result)}")
if result.get("code", 0) != 0:
print(f"ERROR: 获取电子表格信息失败 {result}", file=sys.stderr)
raise Exception(f"failed to get spreadsheet info: {result.get('msg', 'unknown error')}")
if not result.get("data") or not result["data"].get("spreadsheet"):
raise Exception("未获取到电子表格信息")
spreadsheet_info = result["data"]["spreadsheet"]
print("电子表格信息获取成功:", {
"title": spreadsheet_info.get("title"),
"owner_id": spreadsheet_info.get("owner_id"),
"token": spreadsheet_info.get("token"),
"url": spreadsheet_info.get("url")
})
return spreadsheet_info
except Exception as e:
print(f"ERROR: getting spreadsheet info: {e}", file=sys.stderr)
raise
def get_spreadsheet_sheets(tenant_access_token: str, spreadsheet_token: str) -> List[Dict[str, Any]]:
"""获取电子表格中的所有工作表
Args:
tenant_access_token: 租户访问令牌
spreadsheet_token: 电子表格token
Returns:
List[Dict[str, Any]]: 工作表列表
"""
url = f"https://open.feishu.cn/open-apis/sheets/v3/spreadsheets/{spreadsheet_token}/sheets/query"
headers = {
"Authorization": f"Bearer {tenant_access_token}",
"Content-Type": "application/json; charset=utf-8"
}
try:
print(f"GET: {url}")
response = requests.get(url, headers=headers)
response.raise_for_status()
result = response.json()
print(f"Response: {json.dumps(result)}")
if result.get("code", 0) != 0:
print(f"ERROR: 获取工作表列表失败 {result}", file=sys.stderr)
raise Exception(f"failed to get sheets: {result.get('msg', 'unknown error')}")
if not result.get("data") or not result["data"].get("sheets"):
raise Exception("未获取到工作表列表")
sheets = result["data"]["sheets"]
print(f"获取到 {len(sheets)} 个工作表:")
for i, sheet in enumerate(sheets):
print(f" {i+1}. 标题: {sheet.get('title')}, ID: {sheet.get('sheet_id')}, 索引: {sheet.get('index')}, 隐藏: {sheet.get('hidden')}")
return sheets
except Exception as e:
print(f"ERROR: getting sheets: {e}", file=sys.stderr)
raise
def read_sheet_range(tenant_access_token: str, spreadsheet_token: str, sheet_id: str, range_str: str) -> Dict[str, Any]:
"""读取电子表格中单个范围的数据
Args:
tenant_access_token: 租户访问令牌
spreadsheet_token: 电子表格token
sheet_id: 工作表ID
range_str: 查询范围
Returns:
Dict[str, Any]: 读取的数据
"""
full_range = f"{sheet_id}!{range_str}"
url = f"https://open.feishu.cn/open-apis/sheets/v2/spreadsheets/{spreadsheet_token}/values/{urllib.parse.quote(full_range)}"
url += "?valueRenderOption=ToString&dateTimeRenderOption=FormattedString&user_id_type=open_id"
headers = {
"Authorization": f"Bearer {tenant_access_token}",
"Content-Type": "application/json; charset=utf-8"
}
try:
print(f"GET: {url}")
response = requests.get(url, headers=headers)
response.raise_for_status()
result = response.json()
print(f"Response: {json.dumps(result)}")
if result.get("code", 0) != 0:
print(f"ERROR: 读取表格范围失败 {result}", file=sys.stderr)
raise Exception(f"failed to read sheet range: {result.get('msg', 'unknown error')}")
if not result.get("data") or not result["data"].get("valueRange"):
raise Exception("未获取到表格数据")
value_range = result["data"]["valueRange"]
print(f"读取范围 {full_range} 成功,数据行数: {len(value_range.get('values', []))}")
# 打印前5行数据作为示例
values = value_range.get("values", [])
for i, row in enumerate(values[:5]):
print(f" 行{i+1}: {row}")
if len(values) > 5:
print(f" ... 还有 {len(values) - 5} 行数据")
return value_range
except Exception as e:
print(f"ERROR: reading sheet range: {e}", file=sys.stderr)
raise
def read_sheet_ranges(tenant_access_token: str, spreadsheet_token: str, ranges: List[str]) -> Dict[str, Any]:
"""读取电子表格中多个范围的数据
Args:
tenant_access_token: 租户访问令牌
spreadsheet_token: 电子表格token
ranges: 查询范围列表
Returns:
Dict[str, Any]: 读取的数据
"""
ranges_param = ",".join([urllib.parse.quote(r) for r in ranges])
url = f"https://open.feishu.cn/open-apis/sheets/v2/spreadsheets/{spreadsheet_token}/values_batch_get?ranges={ranges_param}"
url += "&valueRenderOption=ToString&dateTimeRenderOption=FormattedString&user_id_type=open_id"
headers = {
"Authorization": f"Bearer {tenant_access_token}",
"Content-Type": "application/json; charset=utf-8"
}
try:
print(f"GET: {url}")
response = requests.get(url, headers=headers)
response.raise_for_status()
result = response.json()
print(f"Response: {json.dumps(result)}")
if result.get("code", 0) != 0:
print(f"ERROR: 读取多个表格范围失败 {result}", file=sys.stderr)
raise Exception(f"failed to read sheet ranges: {result.get('msg', 'unknown error')}")
if not result.get("data") or not result["data"].get("valueRanges"):
raise Exception("未获取到表格数据")
value_ranges = result["data"]["valueRanges"]
print(f"读取 {len(value_ranges)} 个范围成功:")
for i, vr in enumerate(value_ranges):
range_name = vr.get("range", "")
values = vr.get("values", [])
print(f" 范围{i+1}: {range_name}, 数据行数: {len(values)}")
# 打印前3行数据作为示例
for j, row in enumerate(values[:3]):
print(f" 行{j+1}: {row}")
if len(values) > 3:
print(f" ... 还有 {len(values) - 3} 行数据")
return result["data"]
except Exception as e:
print(f"ERROR: reading sheet ranges: {e}", file=sys.stderr)
raise
def extract_node_token_from_url(url: str) -> str:
"""从知识库URL中提取节点token
Args:
url: 知识库URL
Returns:
str: 节点token
"""
try:
parsed_url = urllib.parse.urlparse(url)
path_parts = parsed_url.path.split("/")
for part in path_parts:
if part.startswith("wiki/"):
return part.replace("wiki/", "")
# 如果没有找到wiki/,尝试直接从路径中获取
if len(path_parts) >= 3:
return path_parts[2].split("?")[0]
raise Exception("无法从URL中提取节点token")
except Exception as e:
print(f"ERROR: extracting node token from URL: {e}", file=sys.stderr)
raise
三 因为我们公司的dify包太多 而且dify调用python生成文件没权限 所以调用第三方服务器api 下面是第三方api生成的jira代码
from jira import JIRA
import os
class JiraTaskManager:
def __init__(self, server_url, username, api_token):
"""
初始化JIRA连接
:param server_url: JIRA服务器地址
:param username: 用户名或邮箱
:param api_token: API令牌
"""
self.server_url = server_url
self.username = username
self.api_token = api_token
self.jira = None
self._connect()
def _connect(self):
"""建立JIRA连接"""
try:
self.jira = JIRA(
server=self.server_url,
basic_auth=(self.username, self.api_token)
)
print("✅ JIRA连接成功")
#print(self.jira.projects())
except Exception as e:
print(f"❌ JIRA连接失败: {e}")
raise
def create_issue(self, project_key, summary, description, issue_type='Task',
priority='Medium', assignee=None, parent_key=None, attachments=None):
"""
创建JIRA任务并上传附件
:param project_key: 项目键
:param summary: 任务标题
:param description: 任务描述
:param issue_type: 任务类型
:param priority: 优先级
:param assignee: 负责人用户名
:param parent_key: 父任务键
:param attachments: 附件文件路径列表
:return: 创建的任务对象
"""
issue_dict = {
'project': {'key': project_key},
'issuetype': {'name': issue_type},
'summary': summary,
'description': description,
'priority': {'name': priority},
'customfield_10405': {'value': 'Coding'},
'components': [{'name': 'test'}]
}
if assignee:
issue_dict['assignee'] = {'name': assignee}
if issue_type == 'Sub-task' and parent_key:
issue_dict['parent'] = {'key': parent_key}
try:
issue = self.jira.create_issue(fields=issue_dict)
print(f"✅ 任务创建成功: {issue.key}")
# 上传附件
if attachments:
self.upload_attachments(issue.key, attachments)
return issue.key
except Exception as e:
print(f"❌ 任务创建失败: {e}")
return None
def upload_attachments(self, issue_key, file_paths):
"""
为指定任务上传多个附件
:param issue_key: 任务键
:param file_paths: 文件路径列表
"""
try:
issue = self.jira.issue(issue_key)
uploaded_files = []
for file_path in file_paths:
if os.path.exists(file_path):
self.jira.add_attachment(issue=issue, attachment=file_path)
file_name = os.path.basename(file_path)
uploaded_files.append(file_name)
print(f"📎 附件上传成功: {file_name}")
else:
print(f"❌ 文件不存在: {file_path}")
if uploaded_files:
print(f"✅ 共上传 {len(uploaded_files)} 个附件到任务 {issue_key}")
return uploaded_files
except Exception as e:
print(f"❌ 附件上传失败: {e}")
return []
def upload_single_attachment(self, issue_key, file_path):
"""
为指定任务上传单个附件
:param issue_key: 任务键
:param file_path: 文件路径
"""
return self.upload_attachments(issue_key, [file_path])
def create_issue_with_attachment(self, project_key, summary, description,
attachment_path, issue_type='Task', priority='Medium'):
"""
创建任务并上传单个附件的便捷方法
"""
attachments = [attachment_path] if attachment_path else None
return self.create_issue(
project_key=project_key,
summary=summary,
description=description,
issue_type=issue_type,
priority=priority,
attachments=attachments
)
def list_attachments(self, issue_key):
"""
列出任务的所有附件
:param issue_key: 任务键
:return: 附件列表
"""
try:
issue = self.jira.issue(issue_key)
attachments = issue.fields.attachment
if attachments:
print(f"📎 任务 {issue_key} 的附件列表:")
for attachment in attachments:
print(f" - {attachment.filename} ({attachment.size} bytes)")
else:
print(f"ℹ️ 任务 {issue_key} 没有附件")
return attachments
except Exception as e:
print(f"❌ 获取附件列表失败: {e}")
return []
def download_attachment(self, attachment, download_dir='./downloads'):
"""
下载附件到指定目录
:param attachment: 附件对象
:param download_dir: 下载目录
"""
try:
if not os.path.exists(download_dir):
os.makedirs(download_dir)
download_path = os.path.join(download_dir, attachment.filename)
with open(download_path, 'wb') as f:
f.write(attachment.get())
print(f"📥 附件下载成功: {download_path}")
return download_path
except Exception as e:
print(f"❌ 附件下载失败: {e}")
return None
def main():
"""主函数示例"""
# 配置信息 - 请替换为实际的值
JIRA_SERVER = ''
USERNAME = ''
API_TOKEN = ''
# 创建JIRA连接实例
manager = JiraTaskManager(JIRA_SERVER, USERNAME, API_TOKEN)
#exit()
# 示例1: 创建任务并上传多个附件
print("\n--- 创建任务并上传多个附件 ---")
attachments = [
'./public/log.txt',
]
issue = manager.create_issue(
project_key='LIN',
summary='congcong-dify带附件的测试任务-请忽略',
description='这个任务包含了多个相关附件文件',
issue_type='Task',
priority='Low',
attachments=attachments
)
print(issue)
#exit()
# if issue:
# # 示例2: 为现有任务上传新附件
# print("\n--- 为现有任务上传新附件 ---")
# new_attachment = './public/1.txt'
# manager.upload_single_attachment(issue.key, new_attachment)
# # 示例3: 列出任务的所有附件
# print("\n--- 列出任务附件 ---")
# manager.list_attachments(issue.key)
if __name__ == "__main__":
main()
大功告成 本文档只为记录dify开发中的实际应用


















 545
545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









