




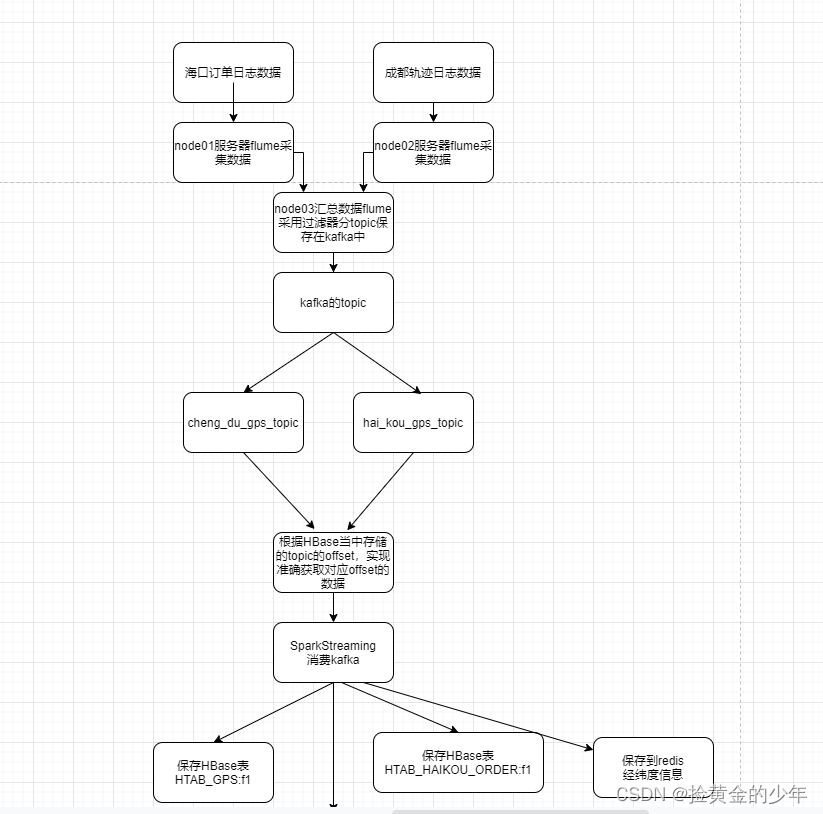
 本文详细描述了一个使用Flume采集日志数据,通过Kafka作为中间件,再由SparkStreaming进行实时处理的架构。Flume配置了多个节点,分别处理海口和成都的数据,并通过静态拦截器设置不同topic。SparkStreaming连接Kafka,消费数据并保存到HBase和Redis,同时管理消费的offset。整个流程实现了数据的实时监控和历史轨迹回放功能。
本文详细描述了一个使用Flume采集日志数据,通过Kafka作为中间件,再由SparkStreaming进行实时处理的架构。Flume配置了多个节点,分别处理海口和成都的数据,并通过静态拦截器设置不同topic。SparkStreaming连接Kafka,消费数据并保存到HBase和Redis,同时管理消费的offset。整个流程实现了数据的实时监控和历史轨迹回放功能。
目录
2、第二步从kafka中获取数据信息,写了一个自定义方法getStreamingContextFromHBase
3、第三步、消费数据,解析数据并将数据存入hbase不同的表中和redis中
4、第四步提交消费的kafka的偏移量到 hbase的表中进行管理
使用flume采集我们的日志数据,然后将数据放入到kafka当中去,通过sparkStreaming消费我们的kafka当中的数据,然后将数据保存到hbase,并且将海口数据保存到redis当中去,实现实时轨迹监控以及历史轨迹回放的功能
为了模拟数据的实时生成,我们可以通过数据回放程序来实现订单数据的回放功能
1、模拟数据生成
1、海口订单数据上传
将海口数据上传到node01服务器的/kkb/datas/sourcefile这个路径下,node01执行以下命令创建文件夹,然后上传数据
mkdir -p /kkb/datas/sourcefile
2、成都轨迹日志数据
将成都数据上传到node02服务器的/kkb/datas/sourcefile这个路径下node02执行以下命令创建文件夹,然后上传数据
mkdir -p /kkb/datas/sourcefile
3、因为没有实际应用,所以写一个脚本,对数据不断复制追加
在node01服务器的/home/hadoop/bin路径下创建shell脚本,用于数据的回放
cd /home/hadoop/bin
vim start_stop_generate_data.sh
#!/bin/bash
scp /home/hadoop/FileOperate-1.0-SNAPSHOT-jar-with-dependencies.jar node02:/home/hadoop/
#休眠时间控制
sleepTime=1000
if [ ! -n "$2" ];then
echo ""
else
sleepTime=$2
fi
case $1 in
"start" ){
for i in node01 node02
do
echo "-----------$i启动数据回放--------------"
ssh $i "source /etc/profile;nohup java -jar /home/hadoop/FileOperate-1.0-SNAPSHOT-jar-with-dependencies.jar /kkb/datas/sourcefile /kkb/datas/destfile $2 > /dev/null 2>&1 & "
done
};;
"stop"){
for i in node02 node01
do
echo "-----------停止 $i 数据回放-------------"
ssh $i "source /etc/profile; ps -ef | grep FileOperate-1.0-SNAPSHOT-jar | grep -v grep |awk '{print \$2}' | xargs kill"
done
};;
esac
脚本赋权
cd /home/hadoop/bin
chmod 777 start_stop_generate_data.sh
启动脚本
sh start_stop_generate_data.sh start 3000
停止脚本
sh start_stop_generate_data.sh stop
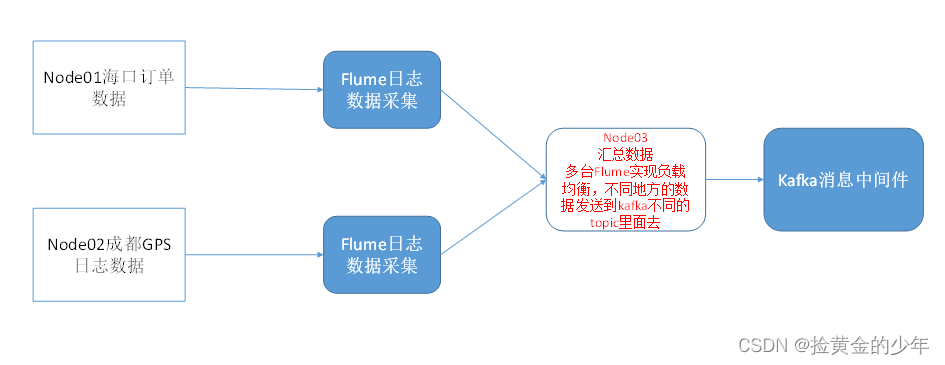
2、flume采集数据
逻辑机构如下
1、node01配置flume的conf文件
cd /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf/
vim flume_client.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
#配置source
a1.sources.r1.type = taildir
a1.sources.r1.positionFile = /kkb/datas/flume_temp/flume_posit/haikou.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /kkb/datas/destfile/part.+
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
## static拦截器的功能就是往采集到的数据的header中插入自己定## 义的key-value对
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = hai_kou_gps_topic
#flume监听轨迹文件内容的变化 tuch gps
#配置sink
#a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#flume监听的文件数据发送到此kafka的主题当中
#a1.sinks.k1.topic = hai_kou_gps_topic
#a1.sinks.k1.brokerList= node01:9092,node02:9092,node03:9092
#a1.sinks.k1.batchSize = 20
#a1.sinks.k1.requiredAcks = 1
#a1.sinks.k1.producer.linger.ms = 1
#配置sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node03
a1.sinks.k1.port = 41414
#配置channel
a1.channels.c1.type = file
#检查点文件目录
a1.channels.c1.checkpointDir=/kkb/datas/flume_temp/flume_check
#缓存数据文件夹
a1.channels.c1.dataDirs=/kkb/datas/flume_temp/flume_cache
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
sources:文件数据来源
channels: 文件数据通道
sinks :文件数据输出
其中关键的就是在sources配置过滤器,方便node03数据集中处理的时候将不同的数据,分配给不同的kafka的topic
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
## static拦截器的功能就是往采集到的数据的header中插入自己定## 义的key-value对
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = hai_kou_gps_topic
2、node02开发flume的配置文件
cd /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf/
vim flume_client.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
#配置source
a1.sources.r1.type = taildir
a1.sources.r1.positionFile = /kkb/datas/flume_temp/flume_posit/chengdu.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /kkb/datas/destfile/part.+
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
## static拦截器的功能就是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5741
5741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









