




文章目录
前言
记载RabbitMQ的使用
RabbitMQ安装:https://blog.youkuaiyun.com/weixin_43287895/article/details/126464752
RabbitMQ
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。RabbitMQ服务器是用Erlang语言编写的,而集群和故障转移是构建在开放电信平台框架上的。所有主要的编程语言均有与代理接口通讯的客户端库。(百度百科)
RabbitMQ角色分类
一共有5种角色
1、none
不能访问management plugin
2、management 查看自己相关节点信息
列出自己可以通过AMQP登入的虚拟机
查看自己的虚拟机节点virtual hosts 和queues,exchanges和binding信息
查看和关闭自己的channels的connections
查看有关自己的虚拟机节点virtual hosts的统计信息。包括其他用于在这个节点virtual hosts中的活动信息
3、Policymaker 只能看自己的,但是可以创建节点
包含management的所有权限
查看和创建和删除自己的virtual hosts所属的policies和parameters信息
4、Monitoring 可以看别人
包含management所有权限
罗列出所有的virtual hosts,包括不能登录的virtual hosts
查看其他用户的connections和channels信息
查看节点级别的数据如clustering和memory使用情况
5、Administrator 最高
最高权限
可以创建和删除virtual hosts
可以查看、创建和删除users
查看创建permissions
AMQP协议
AMQP协议全称:Advanced Message Queuing Protocal(高级消息队列协议)。应用层协议开发的一个标准,面向消息中间件
AMQP生产者过程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DfluvdDl-1661148906380)(C:\Users\77278\AppData\Roaming\Typora\typora-user-images\image-20220729175503399.png)]](https://i-blog.csdnimg.cn/blog_migrate/7418d1c5a841bfb6d74ee83fac4350e9.png)
AMQP消费者过程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sL3O7jA6-1661148906383)(C:\Users\77278\AppData\Roaming\Typora\typora-user-images\image-20220729180339015.png)]](https://i-blog.csdnimg.cn/blog_migrate/cd1e7f78a556cd9062b595a7b4df69c4.png)
相比于生产者,消费者这边多了一个ack应答,若没有应答则会重发,重发到一定次数或者时间,就会挂起消息队列,若消息队列挂起,生产者就不能再往里发送消息。
RabbitMQ的核心组成部分
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NYXcmYJP-1661148906392)(C:\Users\77278\AppData\Roaming\Typora\typora-user-images\image-20220729194226643.png)]](https://i-blog.csdnimg.cn/blog_migrate/d9e059525a1ba95c14dc5d4a0b8b28d3.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bKhYYJIH-1661148906393)(C:\Users\77278\AppData\Roaming\Typora\typora-user-images\image-20220729194752611.png)]](https://i-blog.csdnimg.cn/blog_migrate/cc19e467d4a37a589fbee7f8632453f4.png)
运行流程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ROqserpa-1661148906396)(C:\Users\77278\AppData\Roaming\Typora\typora-user-images\image-20220729194809810.png)]](https://i-blog.csdnimg.cn/blog_migrate/bcc609376253bce6becbcb9a3f1ae808.png)
支持消息的模式
所有的中间件技术都是基于tcp/ip协议基础之上构建的的新型协议规范,而rabbitmq遵循是的amqp
simple简单模式

生产者
//1、创建连接工程
ConnectionFactory connectionFactory = new ConnectionFactory();
connectionFactory.setHost("47.93.57.13");
connectionFactory.setPort(5672);
connectionFactory.setUsername("admin");
connectionFactory.setPassword("admin");
connectionFactory.setVirtualHost("/");
//2、创建连接Connection
Connection connection = connectionFactory.newConnection("生产者");
//3、通过连接获取通道
Channel channel = connection.createChannel();
//4、通过通道创建交换机,声明队列,绑定消息,路由key,发送消息和接受消息
// 声明队列
//参数:队列名称,是否要持久化,排他性(是否独占独立),是否自动删除(发送给最后一个消费者后是否删除),携带参数
String queuename = "queue1";
channel.queueDeclare(queuename,false,false,false,null);
//5、准备消息
String message = "Hello World";
//6、发送消息给队列
//交换机,队列、路由key,消息状态控制,消息内容
//可以存在没有交换机的队列吗?不可能,虽然没有指定,但一定会存在一个默认的交换机
channel.basicPublish("",queuename,null,message.getBytes());
System.out.println("发送消息成功");
//7、关闭连接
if(channel.isOpen()){
channel.close();
}
//8、关闭通道
if(connection.isOpen()){
connection.close();
}
}
消费者
//1、创建连接工程
ConnectionFactory connectionFactory = new ConnectionFactory();
connectionFactory.setHost("47.93.57.13");
connectionFactory.setPort(5672);
connectionFactory.setUsername("admin");
connectionFactory.setPassword("admin");
connectionFactory.setVirtualHost("/");
//2、创建连接Connection
Connection connection = connectionFactory.newConnection("消费者");
//3、通过连接获取通道
Channel channel = connection.createChannel();
//4、通过通道创建交换机,声明队列,绑定消息,路由key,发送消息和接受消息
// 声明队列
//参数:队列名称,是否要持久化,排他性(是否独占独立),是否自动删除(发送给最后一个消费者后是否删除),携带参数
String queuename = "queue1";
channel.queueDeclare(queuename,false,false,false,null);
//6、接受消息
channel.basicConsume(queuename,true, new DeliverCallback() {
public void handle(String s, Delivery delivery) throws IOException {
System.out.println("收到的消息是"+new String(delivery.getBody(),"UTF-8"));
}
}, new CancelCallback() {
public void handle(String s) throws IOException {
System.out.println("接受失败了");
}
});
//7、关闭连接
if(channel.isOpen()){
channel.close();
}
//8、关闭通道
if(connection.isOpen()){
connection.close();
}
}
work工作模式
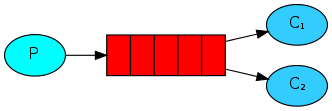
轮询
一个消费者一条,按均分配
代码上,将baseConsume的autoack改成true,自动应答就是轮询分发
fair公平
根据消费者的能力进行公平分发,处理快的处理的多,处理慢的处理的少,按劳分配
代码上,将baseConsume的autoack改成false,手动应答就是公平分发
channel.basicQos(1);
//每次从队列中取出1条进行消费
// 在接受消息的new DeliveryCallback()中加入应答
channel.basicAck(delivery.getEnvelope().getDeliveryTag(),false)
Fanout发布与订阅模式
type=fanout,需要绑定exchange交换机,没有routing Key,设定了也不会生效
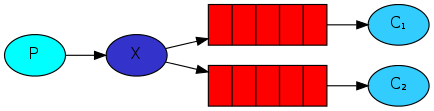
routing路由模式
type=direct,增加了routing Key
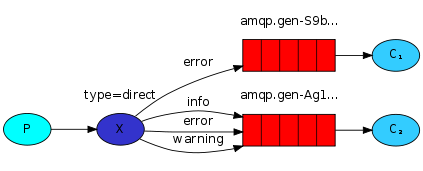
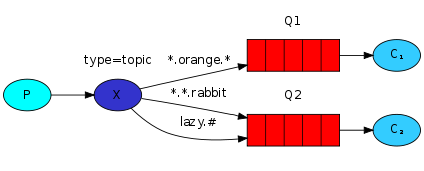
topic主体模式
type=topic,支持模糊匹配的routing Key
# 可以匹配0个或多个,而且是多级
rooting key : com.#
com.xxxx.xxx.xxx
com
com.xxxx
* 可以匹配至少有一个,但是是一级
rooting key: *.a.*
xxx.a.xxx
headers参数模式
type=headers
与routing key 方式差不多,但是是设置arguments参数,通过发送消息时候的参数与设置的参数相同,达到和routing key一样的效果
RabbitMQ使用场景
解耦、削峰、异步
面试:我是在xxx年进入公司,当时公司用的架构比较单一,采用的是单体结构,而单体结构是把所有的业务都堆积在一个里面,但是随着业务的不断发展和推进,公司在第二年的时候我们公司的项目负责人,就把项目开始进行分裂,变成了一个分布式架构,就把系统进行了一个拆分,拆分的过程中就需要考虑的一个问题,比如在拆分过程中xxx模块和xxx模块,他们之间要进行沟通和协同,然后呢我们公司就采用了消息队列,而我们公司采用消息队列的时候呢,就一直在思考采用什么消息队列,后面呢我们决定用了rabbitmq,我自己使用rabbitmq的感受呢,其实就是感觉他最核心的一点就是他是异步的,是一个多线程嘛,是一个分发的机制。是一个多线程机制,而且呢,可以使我们的网站的性能成倍的提升,因为他的异步就能使我们程序处理数据的能力更加的高效
传统情况
同步异步的问题(串行)
串行方式:将订单系统写入数据成功后,发送注册邮件,在发送注册短信,三个任务完成后,返回给客户端
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SMA5ar0w-1661148906405)(C:\Users\77278\AppData\Roaming\Typora\typora-user-images\image-20220730124326458.png)]](https://i-blog.csdnimg.cn/blog_migrate/e908029b191ea842094436174df7b8bd.png)
并行方式 异步线程池
并行方式:将订单信息写入数据库成功后,发送注册邮件的同时,发送注册短信,以上三个任务完成后,返回给客户端,与串行的差别是,并行可以提高处理的时间
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M6erSH84-1661148906408)(C:\Users\77278\AppData\Roaming\Typora\typora-user-images\image-20220730150450405.png)]](https://i-blog.csdnimg.cn/blog_migrate/6398dc14404417c905d72ffc033e785f.png)
缺点:
耦合度高
需要自己写线程池自己维护成本太高
出现了消息可能会丢失,需要自己做消息补偿
如何保证消息的可靠性需要自己写
如果服务器承载不了,需要自己写高可用
异步消息队列
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GaKvQVjn-1661148906409)(C:\Users\77278\AppData\Roaming\Typora\typora-user-images\image-20220730151110230.png)]](https://i-blog.csdnimg.cn/blog_migrate/ca952c6588224f4f36f0c1842dc3d1ed.png)
好处
完全解耦,用MQ建立桥接
有独立的线程池和运行模型
出现了消息可能会丢失,MQ有持久化功能
如何保证消息的可靠性,死信队列和消息转移等
如果服务器承载不了,需要自己去写高可用,HA镜像模型高可用
高内聚低耦合
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oiceycfT-1661148906411)(C:\Users\77278\AppData\Roaming\Typora\typora-user-images\image-20220730151558429.png)]](https://i-blog.csdnimg.cn/blog_migrate/0be81e193d6f7cfb02f1cfe6832cf693.png)
流量的削峰
分布式事务的可靠消费和可靠生产
索引、缓存、静态化处理的同步数据
流量监控
日志监控ELK
下单、订单分发、抢票
总结
RabbitMQ最大的使用就是他的线程池概念,在以往的程序中,如果要实现一连串的业务,需要串行方式去进行,也就是一个一个的,如果想要提高速度和效率,可以采用线程池的概念来进行异步发送,但是在程序中添加线程池又会造成JVM内存的削减和使用,使JVM内存在业务上的使用更少了,得不偿失,并且在程序中加入线程池后,造成了耦合问题,使维护起来很麻烦。这些消息发送失败要进行回滚,回滚可能会造成资源浪费,而且如果自己写消息中间件,可靠传输和高可用问题也需要自己来考虑。所以,使用rabbitmq,在使用线程池的同时,将线程池与程序分割开来,形成独立的一层,这就形成了解耦。因为异步,将处理时间缩短,所以有 了削峰。一切的基础都是异步。
Springboot整合RabbitMQ
Fanout模式
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BwmZ9beM-1661148906414)(C:\Users\77278\AppData\Roaming\Typora\typora-user-images\image-20220730154223561.png)]](https://i-blog.csdnimg.cn/blog_migrate/9e3c574b99adfddf7aed395b9f58ace8.png)
生产者
@Service
public class OrderService {
@Autowired
private RabbitTemplate rabbitTemplate;
public void makeOrder(String userid, String productid, int num) {
//1、根据商品id查询内存库数是否充足
//2、保存订单
String orderid = UUID.randomUUID().toString();
System.out.println("订单生成成功:" + orderid);
//3、通过MQ,消息分发
//交换机名字,key/queue队列名称,消息内容呢
String exchangename = "fanout_order_exchange";
String routingKey = "";
rabbitTemplate.convertAndSend(exchangename, routingKey, orderid);
}
}
配置文件
@Configuration
public class RabbitMQConfig {
//1、fanout模式交换机
@Bean
public FanoutExchange fanoutExchange() {
return new FanoutExchange("fanout_order_exchange", true, false);
}
//2、声明队列sms.fanout.queue,email.fanout.queue,duanxin.fanout.queue
@Bean
public Queue smsQueue() {
return new Queue("sms.fanout.queue", true, false, false);
}
@Bean
public Queue emailQueue() {
return new Queue("email.fanout.queue", true, false, false);
}
@Bean
public Queue duanxinQueue() {
return new Queue("duanxin.fanout.queue", true, false, false);
}
//3、绑定关系
@Bean
public Binding smsBinding() {
return BindingBuilder.bind(smsQueue()).to(fanoutExchange());
}
@Bean
public Binding emailBinding() {
return BindingBuilder.bind(emailQueue()).to(fanoutExchange());
}
@Bean
public Binding duanxinBinding() {
return BindingBuilder.bind(duanxinQueue()).to(fanoutExchange());
}
}
消费者
@RabbitListener(queues = {"duanxin.fanout.queue"})
@Service
public class DuanXinConsumer {
@RabbitHandler
public void reviceMessage(String message){
System.out.println("duanxin 接受到消息"+message);
}
}
@RabbitListener(queues = {"email.fanout.queue"})
@Service
public class EmailConsumer {
@RabbitHandler
public void reviceMessage(String message){
System.out.println("email 接受到消息"+message);
}
}
@RabbitListener(queues = {"sms.fanout.queue"})
@Service
public class SMSConsumer {
@RabbitHandler
public void reviceMessage(String message){
System.out.println("sms 接受到消息"+message);
}
}
Direct模式
与Fanout差不多,只需要修改config
配置文件
@Configuration
public class DirectConfig {
//1、fanout模式交换机
@Bean
public DirectExchange directExchange() {
return new DirectExchange("direct_order_exchange", true, false);
}
//2、声明队列sms.fanout.queue,email.fanout.queue,duanxin.fanout.queue
@Bean
public Queue smsQueue() {
return new Queue("sms.direct.queue", true, false, false);
}
@Bean
public Queue emailQueue() {
return new Queue("email.direct.queue", true, false, false);
}
@Bean
public Queue duanxinQueue() {
return new Queue("duanxin.direct.queue", true, false, false);
}
//3、绑定关系
@Bean
public Binding smsBinding() {
return BindingBuilder.bind(smsQueue()).to(directExchange()).with("sms");
}
@Bean
public Binding emailBinding() {
return BindingBuilder.bind(emailQueue()).to(directExchange()).with("email");
}
@Bean
public Binding duanxinBinding() {
return BindingBuilder.bind(duanxinQueue()).to(directExchange()).with("duanxin");
}
}
生产者
@Service
public class DirctService {
@Autowired
private RabbitTemplate rabbitTemplate;
public void makeOrder(String userid, String productid, int num) {
//1、根据商品id查询内存库数是否充足
//2、保存订单
String orderid = UUID.randomUUID().toString();
System.out.println("订单生成成功:" + orderid);
//3、通过MQ,消息分发
//交换机名字,key/queue队列名称,消息内容呢
String exchangename = "fanout_order_exchange";
String routingKey = "";
rabbitTemplate.convertAndSend(exchangename, "email", orderid);
rabbitTemplate.convertAndSend(exchangename, "sms", orderid);
rabbitTemplate.convertAndSend(exchangename, "duanxin", orderid);
}
}
Topics模式
注解方式,与上边不一样
@Service
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "duanxin.topic.queue",durable = "true",autoDelete = "false"),
exchange = @Exchange(value = "topic_order_exchange",type = ExchangeTypes.TOPIC),
key = "#.duanxin.#"
))
public class DuanXinConsumer {
@RabbitHandler
public void reviceMessage(String message){
System.out.println("duanxin 接受到消息"+message);
}
}
TTL队列过期时间
过期时间TTL表示可以对消息设置预期的时间,在这个时间里都可以被消费者接受获取,过了之后消息将自动被删除,RabbitMQ可以对消息和队列设置TTL,目前有两种方法可以设置
第一种:通过队列属性设置,队列中所有消息都有相同的过期时间
第二种:对消息进行单独设置,每条消息的TTL可以不同
如果两种方法同时使用,则消息的过期时间以TTL最小的为准。
如果消息一旦超过设置的TTL值,就成为dead message被投递到死信队列,消费者再也无法收到该消息。
如果设置了死信队列就会放到死信队列,如果没有就删除了
队列设置TTL
@Configuration
public class TTLConfig {
//1、fanout模式交换机
@Bean
public FanoutExchange fanoutExchange() {
return new FanoutExchange("ttl_fanout_exchange", true, false);
}
//2、声明队列sms.fanout.queue,email.fanout.queue,duanxin.fanout.queue
@Bean
public Queue smsQueue() {
Map<String,Object> map = new HashMap<>();
//map中的值,可以从web界面点击获取,v一定得是int
map.put("x-message-ttl",5000);
//设置的map需要放到queue中
return new Queue("ttl.fanout.queue", true, false, false,map);
}
//3、绑定关系
@Bean
public Binding smsBinding() {
return BindingBuilder.bind(smsQueue()).to(fanoutExchange());
}
}
消息设置TTL
通过新建对象MessagePostProcessor来给消息设置属性
@Service
public class OrderService {
@Autowired
private RabbitTemplate rabbitTemplate;
public void makeOrder(String userid, String productid, int num) {
//1、根据商品id查询内存库数是否充足
//2、保存订单
String orderid = UUID.randomUUID().toString();
System.out.println("订单生成成功:" + orderid);
//3、通过MQ,消息分发
//交换机名字,key/queue队列名称,消息内容呢
String exchangename = "ttl_message_exchange";
String routingKey = "";
MessagePostProcessor messagePostProcessor = new MessagePostProcessor() {
@Override
public Message postProcessMessage(Message message) throws AmqpException {
message.getMessageProperties().setExpiration("5000");
message.getMessageProperties().setContentEncoding("UTF-8");
return message;
}
};
rabbitTemplate.convertAndSend(exchangename, routingKey, orderid,messagePostProcessor);
}
}
死信队列
DLX,全称Dead-Letter-Exchange,叫死信交换机,当消息在队列中变成死信,他能被重新发送到另一个交换机中,这个交换机就是DLX,绑定DLX的队列被称为死信队列。
消息变成死信,有以下原因
消息被拒绝
消息过期
队列达到最大长度
DLX也是一个正常的交换机,和一般的交换机没有区别,他能在任何的队列上被指定,实际上就是设置某一个队列的属性。当这个队列存在死信时候,RabbitMQ就会自动地将这个消息重新发布到设置的DLX中,然后被路由发送到另一个队列,也就是死信队列
要想使用死信队列,只需要在定义队列的时候设置队列参数,然后指定交换机就可以了
x-dead-letter-exchange
//与正常的交换机一样创建,并不会有什么不同
唯一的不同就是,需要在想要加入死信队列的队列中,加入map,设置参数x-dead-letter-exchange,指定死信交换机
还可以设置routing key
如TTL的交换机
public Queue ttlQueue() {
Map<String,Object> map = new HashMap<>();
map.put("x-message-ttl",5000);
//设置死信队列
map.put("x-dead-letter-exchange","dead-routing-exchange");
//设置死信队列的routing key
map.put("x-dead-letter-routing-key","dead")
return new Queue("ttl.fanout.queue", true, false, false,map);
}
队列的长度x-max-length
//和死信队列一样,只要设置参数即可
map.put("x-max-length",5)
内存监控
参考文档:https://www.rabbitmq.com/configure.html
内存默认的极限大小是0.4,也就是说8G内存的内存默认极限大小为3.2G
命令方式修改
rabbitmqctl set_vm_memory_high_watermark <fraction>
rabbitmqctl set_vm_memory_high_watermark relative 0.6
rabbitmqctl set_vm_memory_high_watermark absolute 50MB
# 建议 relative 0.4~0.7
# fraction为内存阈值
当RabbitMQ的内存超过40%时,就会产生警告,并且阻塞所有生产者的连接。通过命令修改的内存阈值在重启后会失效,而配置文件修改的再重启后不会失效。
内存换页
在某个Broker节点以及内存阻塞生产者之前,他会尝试将队列中的消息换页到磁盘以释放内存空间,持久化和非持久化消息都会写入磁盘中,其中持久化的消息本身就在磁盘中有一个副本,所以在转移的过程中持久化的消息会先从内存中消除掉
默认情况下,内存到达的阈值是50%时候就会换页处理
也就是说,默认的阈值为0.4,到50%,0.4*0.5=0.2,在内存到0.2的时候会换页处理
vm_memory_high_watermark.relative=0.4
vm_memory_high_watermark_paging_ratio =0.7(设置值小于1)
磁盘预警
rabbitmqctl set_disk_free_limit <disk_limit>
# 小于多少磁盘大小,会爆红
rabbitmqctl set_disk_free_memory_limit <fraction>
disk_limit: 固定单位
fraction: 相对阈值,1.0-2.0之间
disk_free_limit.relative= 3.0
disk_free_limit.absolute = 50mb
集群搭建
参考文档:https://www.rabbitmq.com/clustering.html
由目前来看,如果主节点挂了,从节点也不能使用
一台电脑的多实例情况
# 启动第一个节点
sudo RABBITMQ_NODE_PORT=5672 RABBITMQ_NODENAME=rabbit-1 rabbitmq-server start &
# 启动第二个节点
sudo RABBITMQ_NODE_PORT=5673 RABBIMTQ_SERVER_START_ARGS="-rabbitmq_management listener [{port,15673}]" RABBITMQ_NODENAME=rabbit-2 rabbitmq-server start &
# 验证启动
ps aux|grep rabbitmq
# rabbit-1操作作为主节点
# 停止应用
sudo rabbitmqctl -n rabbit-1 stop_app
# 清楚节点上的历史记录(如果不清除,可能会无法将节点加入集群)
sudo rabbitmqctl -n rabbit-1 reset
# 启动应用
sudo rabbitmqctl -n rabbit-1 start_app
# rabbit-2操作作为从节点
# 停止应用
sudo rabbitmqctl -n rabbit-2 stop_app
# 清楚节点上的历史记录(如果不清除,可能会无法将节点加入集群)
sudo rabbitmqctl -n rabbit-2 reset
# 将rabbit2节点加入到rabbit1集群中,Server-node为主机名
sudo rabbitmqctl -n rabbit-2 join_cluster rabbit-1@'Server-node'
# 启动应用
sudo rabbitmqctl -n rabbit-2 start_app
# 验证集群状态
sudo rabbitmqctl cluster_status -n rabbit-1
web 监控台
rabbitmq-plugins enable rabbitmq_management
rabbitmqctl -n rabbit-1 add_user admin admin
rabbitmqctl -n rabbit-1 set_user_tags admin administrator
rabbitmqctl -n rabbit-1 set_permissions -p / admin ".*" ".*" ".*"
rabbitmqctl -n rabbit-2 add_user admin admin
rabbitmqctl -n rabbit-2 set_user_tags admin administrator
rabbitmqctl -n rabbit-2 set_permissions -p / admin ".*" ".*" ".*"
docker 集群搭建
# docker 集群搭建,简略
# hostname=myrabbit01,镜像名=rabbit01
docker run -d --restart=always \
--hostname myrabbit01 --name rabbit01 \
-e RABBITMQ_DEFAULT_USER=user -e RABBITMQ_DEFAULT_PASS=password \
-e RABBITMQ_ERLANG_COOKIE='rabbitmqCookie' \
-p 15672:15672 -p 5672:5672 -p 5671:5671 -p 4369:4369 -p 25672:25672 \
-v /home/soft/rabbitmq/data:/var/lib/rabbitmq \
--add-host myrabbit02:192.168.45.130 \
--add-host myrabbit03:192.168.45.131 \
rabbitmq:3-management
# cookie保证多机的连接
# cookie放在/var/lib/rabbitmq/.erlang.cookie
#---------------------------------------
# 建立多个节点后
# 进入从节点
docker exec -it rabbit01 bash
# 停止应用
rabbitmqctl -n stop_app
# 清楚节点上的历史记录(如果不清除,可能会无法将节点加入集群)
rabbitmqctl -n reset
# 加入节点
rabbitmqctl -n join_cluster --ram rabbit@主机名也可以是ip
# 启动应用
rabbitmqctl -n start_app
如果想主集群和从集群,需要LVS和KeepAlived,HA
集群方式在springboot中需要设置addresses

















 1395
1395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









