




目录
broker
节点,多个broker搭建出kafka集群
Controller
Kafka集群中有一个broker会被选举为Controller,负责管理集群broker的上下线,所有topic的分区副本分配和leader选举等工作。Controller的管理工作都是依赖于Zookeeper的。
topic
主题,一个主题放的是一种业务类型的数据(也可以理解为一种结构的数据),要不然,这个topic数据都不一致,消费出来后怎么处理
Kafka中消息是以topic进行分类的,生产者生产消息,消费者消费消息,都是面向topic的
Kafka 0.9版本之前,consumer默认将offset保存在Zookeeper中,从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该topic为__consumer_offsets
topic注意事项
kafka需要打开配置

否则
当执行删除命令之后, topic不是物理別除,而是一个标记删刚除的操作。只有重启kafka才会删除
mytopic4 -marked for deletion
标记删除之后的主题可以继续,不会影响
partition
topic有多个分区,每条消息都有一个offset,每个分区内的数据是有序的,但做不到多分区有序,除非你只一个分区
topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是producer生产的数据
Producer生产的数据会被不断追加到该log文件末端,且每条数据都有自己的offset。消费者组中的每个消费者,都会实时记录自己消费到了哪个offset,以便出错恢复时,从上次的位置继续消费
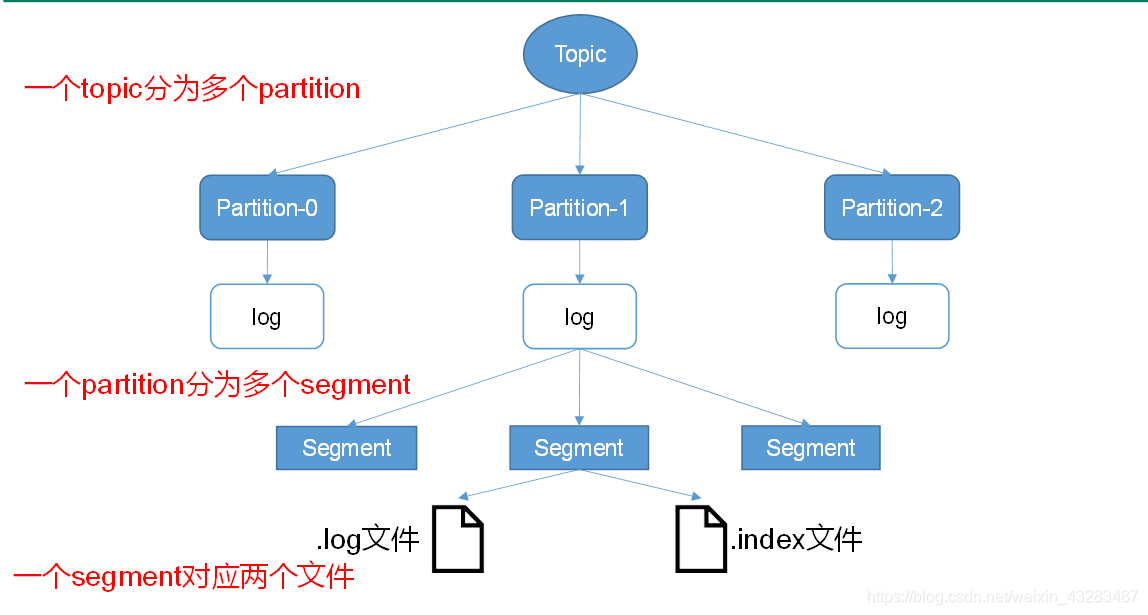
segment
生产者生产的消息会不断追加到log文件末尾,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment
每个segment对应两个文件".index"文件和".log"文件
“.index"文件存储大量的索引信息,”.log"文件存储大量的数据,索引文件中的元数据指向对应数据文件中message的物理偏移地址
日志目录结构
每个segment对应两个文件".index”文件和".log"文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号。例如,first这个topic有三个分区,则其对应的文件夹为first-0,first-1,first-2。
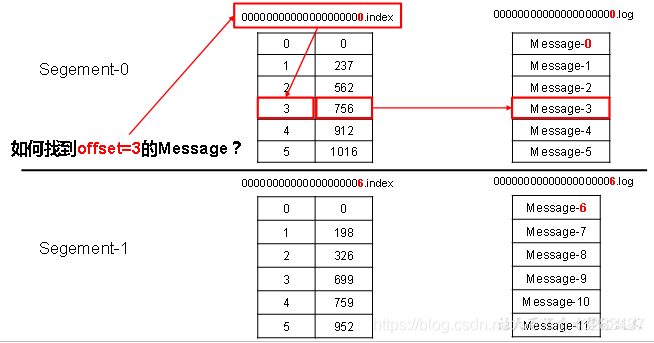
index和log文件以当前segment的第一条消息的offset命名。下图为index文件和log文件的结构示意图
那么如果我指定了一个offset,Kafka Controller怎么查找到对应的消息?
Partition的作用
- 每个topic都有多个partition,每个partition都可以分布在不同机器上,整个集群就可以适应任意大小的数据,而且方便扩展
- 可以提高并发,因为可以以Partition为单位读写
kafka分区数怎么设置,和consumer数目关系
- kafka集群中越多的partition会带来越高的吞吐量。但是,我们必须意识到集群的partition总量过大或者单个broker节点partition过多,都会对系统的可用性和消息延迟带来潜在的影响
- kafka的一个partition上是不允许并发的,也就是一个分区不能被多个consumer消费
- 最好partiton数目是consumer数目的整数倍
- kafka只保证在一个partition上数据是有序的,如果consumer从多个partition读到数据,不保证数据间的顺序性
- 增减consumer,broker,partition会导致rebalance,所以rebalance后consumer对应的partition会发生变化
- topic 数据量比较大时,可以考虑设置多个分区,并配备多个consumer做并发
- 消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据
副本
每个partition都有副本机制保证数据的安全



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











