 决策树学习精要
决策树学习精要








决策树的剪枝:
将过于细分的叶结点剪去,使其回退到父结点甚至更高结点,然后将父结点或更高结点变为新的叶结点,将树变得简单,具有更好的泛化能力
决策树的学习算法包括特征选择、决策树的生成、决策树的剪枝过程;其中决策树的生成对应于模型的局部选择,决策树的剪枝对应于模型的全局选择;即决策树的生成考虑局部最优,决策树的剪枝考虑全局最优
特征选择:
特征选择是选取对训练数据具有分类能力的特征(如果某一特征对分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的)
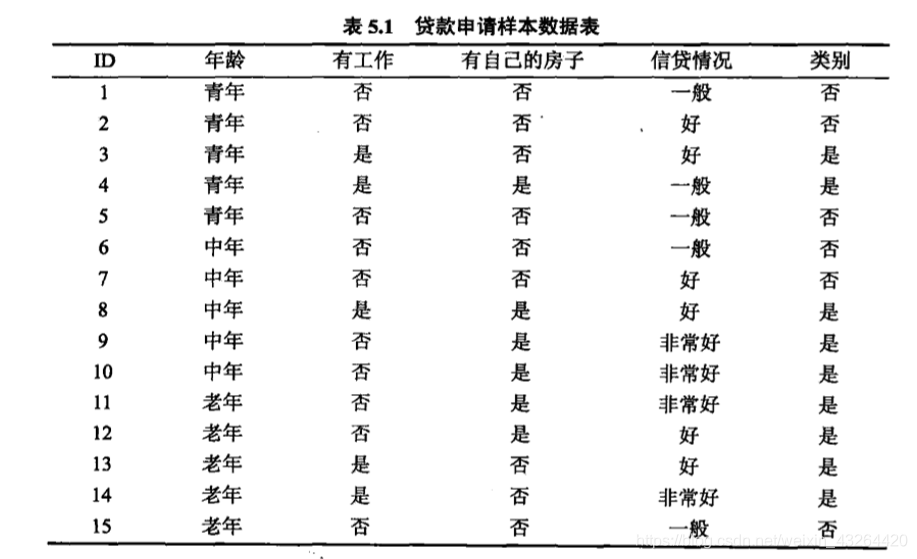
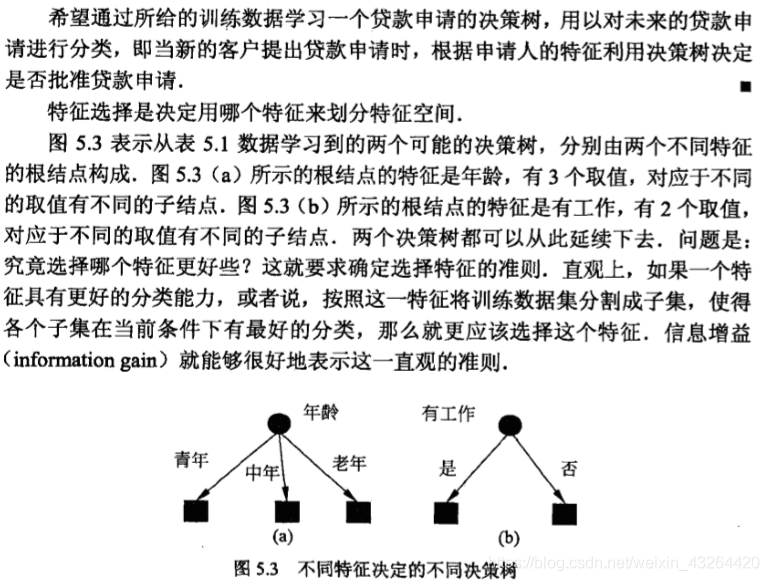
下面引入一个例子:

信息增益:
首先我们来看一下熵与条件熵的概念:


当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到时,相应的称为经验熵与经验条件熵
信息增益:“增”即是增加特征值X的信息,“益”即是得到特征值信息后使得类Y的信息的不确定性减少的程度


显然,对于数据集D而言,信息增益依赖于特征,不同的特征往往具有不同的信息增益;信息增益越大,则该特征的分类能力越强


















 4656
4656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











