




 本文详细阐述了大型网站架构的演进过程,从单机交易网站到分布式系统的构建,包括应用与数据库分离、读写分离、数据垂直与水平拆分、引入分布式存储系统等关键技术。同时,探讨了分布式系统的设计难点,如全局时钟缺乏、故障独立性及单点故障问题。
本文详细阐述了大型网站架构的演进过程,从单机交易网站到分布式系统的构建,包括应用与数据库分离、读写分离、数据垂直与水平拆分、引入分布式存储系统等关键技术。同时,探讨了分布式系统的设计难点,如全局时钟缺乏、故障独立性及单点故障问题。
一、分布式系统
分布式系统是一组分布在网络上通过消息传递进行协作的计算机组成系统。
分布式系统的意义:
- 升级单机处理能力的性价比越来越低
- 单机处理能力存在瓶颈
- 出于稳定性和可用性的考虑
摩尔定律:当价格不变时,每隔18个月,集成电路上可容纳的晶体管数目会增加一倍,性能也将提升一倍。
组成计算机的基本要素:输入设备、输出设备、运算器、控制器和存储器。
阿姆达尔定律:s(N)=1/((1-p)+p/N)
其中P指的是程序中可并行的部分的程序在单核上执行的时间的占比,N表示处理器的个数(核心数)。
S(N)是指程序在N个处理器相对单个处理器的提升速度比。
单进程多线程和多进程的区别:
- 线程是属于进程的,一个进程内的多个线程共享进程的内存空间。
- 多个进程之间的内存空间是相对独立的。
- 多个进程间通过内存共享、交换数据的方式与多个线程间的方式有所不同。
- 多进程相对于单进程多线程的方式来说,资源控制更容易实现。
- 多进程中单个进程出现问题不会造成整体不可用。
分布式系统的难点:
- 缺乏全局时钟。每个节点都有自己的时钟,再通过相互发送消息进行协调时,如果仍然依赖时序,就会相对难处理。
- 面对故障的独立性。在分布式系统,整个系统的一部分有问题而其它部分正常是经常出现的情况,我们称之为故障的独立性。
- 单点故障。在整个分布式系统中,如果某个角色或者功能只有单台机器在支撑,那个这个节点称为单点,发生的故障称为单点故障。在分布式系统中要尽量避免出现单点。
如果不能把单机实现变为集群实现,那么一般还有两种选择:
- 给这个单点做好备份,能够在出现问题是进行恢复,并且尽量做到自动恢复,降低恢复所需要使用的时间。
- 降低单点故障的影响范围。
- 事务的挑战。
二、大型网站及其架构演进过程
大型网站:拥有海量数据和高并发的访问量,二者缺一不可。
1. 单机交易网站
所有的功能模块和数据在单台服务器上,通过各个模块之间通过JVM内部的方法调用来进行交互,而应用和数据库之间是通过JDBC进行访问的。
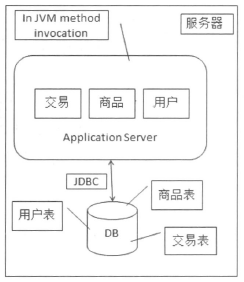
2. 单机负载警告,数据库与应用分离
随着访问量的增加,服务器负载持续升高,考虑将应用服务器和数据库服务器分离。
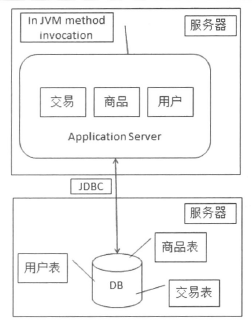
3. 应用服务器负载告警,如何让应用服务器走向集群
应用服务器压力变大时,根据对应用服务器的监测结果,可以考虑将服务器从一台变为两台,增加服务器后急需解决如下连个问题:
- 用户对于应用服务器的选择问题,可以通过在应用服务器前增加负载均衡设备来解决。
- Session问题。
3.1 引入负载均衡设备
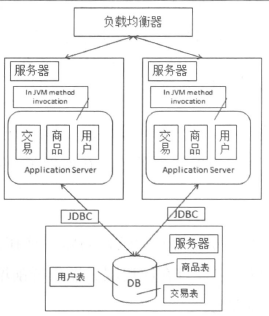
3.2 解决应用服务器的Session问题
用户使用网站服务,需要浏览器与web服务器的多次交互。
HTTP协议本身是无状态的,需要基于HTTP协议支持会话状态(Session State)的机制。
具体实现方式:会话开始时,分配一个唯一会话标识(SessionId),通过Cookie告知给浏览器,若遇禁用Cookie的情况,就将表示放到URL的参数中。
在web服务器上,各个会话有独立的存储,保存不同的会话信息。
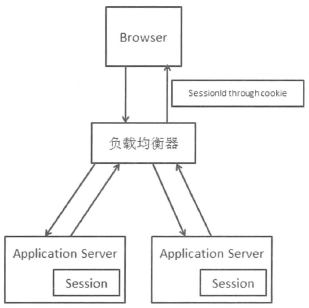
如上图所示,如果第一次网站请求在左边的服务器,那么Session保存在左边的服务器上,如果不做处理,就不能保证每次请求都落在同一台服务器上,这就是Session问题。
解决方式:
- Session Sticky
保证同一个回话的请求都落在同意Web服务器上,称为Session Stickey。
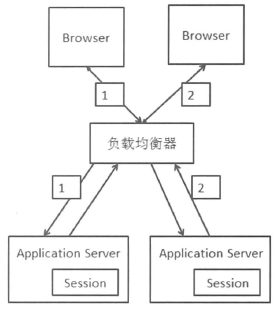
这种方案可以让同样的Session请求每次都发送到同一个服务器进行处理,非常利于对Session进行服务器端本地缓存。
不过带来以下问题:
- 如果服务器宕机或者重启,那个这台服务器上的会话数据会丢失。
- 会话是应用层信息,那么负载均衡要将同一个会话请求都保存到同一个Web服务器上的话,就需要进行应用层的解析,这个开销比第四层的交换要大。
- 负载均衡器会变为一个有状态节点,要将会话到具体Web服务器的映射保存。和无状态的几点相比,内存消耗更大,容灾方面会更麻烦。
- Session Replication(不适合集群机器数多的场景
Session Replication在Web 服务器之间增加了会话数据同步机制,通过保证不同Web服务之间的Session数据的一致,来解决Session问题。
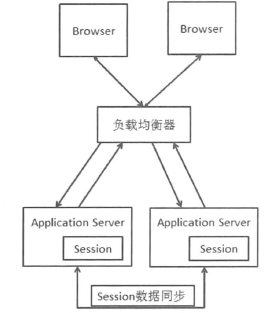
一般的应用容器都支持Session Replication。和Session Replication相比,它对负载均衡设备没有要求,但是其本生也存在一些缺点。
- 同步Session数据造成了网络带宽的开销。机器越多开销越大。
- 每台服务器都要保存保存所有的Session数据,如果整个集群的Session数很多,每台机器用户保存Session的数据占据内存严重。
- Session数据集中存储
把Session数据集中存储起来,不同web服务器从同样的地方来获取Session。
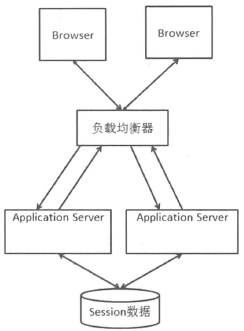
该方案存在的问题:
- 读写Session数据引入了网络操作,这相对于本地数据读取来说,问题就在于存在时延和不稳定性。
- 如果集中的Session服务器或者集群有问题,会对应用产生严重影响。
相对于Session Replication,当web服务器数量比较大、Session数比较多的时候,优势明显。
- Cookie Based
该方案通过Cookie来传递Session数据,将Session数据存放在Cookie中,然后在Web服务器上从Cookie中生成对应的Session数据。相对于Session 集中存储,这个方案不会依赖一个外部存储系统,也就不存在从外部系统获取、写入Session数据的网络时延。
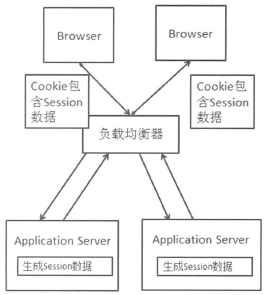
该方案存在的不足:
- Cookie长度的限制。Cookie是有长度限制的,这也会限制Session数据的长度。
- 安全性。Session属于服务端数据,到了外部网络及客户端存在安全性问题,可以加密,但物理上不能接触才是安全的。
- 带宽消耗。指数据中心的整体外部宽带消耗。
- 性能影响。每次Http请求和响应都带有Session数据,对于Web服务器来说,在同样的处理情况下,响应的结果会减少,支持的并发数就越多。
小结:对于大型网站来说,Session Sticky和Session数据集中存储是比较好的方案,各有优劣,需在具体场景中作出选择和权衡。
4. 数据读压力变大,读写分离
4.1采用数据库作为读库
在前面的结构上增加了一个读库,这个库不承担写的工作,只提供读服务。
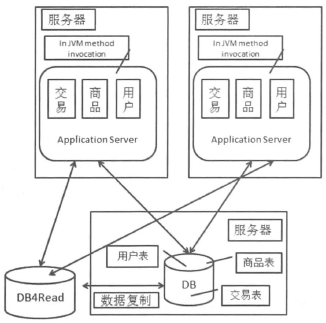
这个结构的变化会带来两个问题:
- 数据复制问题
- 应用对数据源的选择问题
数据库系统一般都提供了数据复制功能,但是对于数据复制还需要考虑数据复制的时延问题。数据复制延迟会带来数据短期不一致问题。
于此同时,对于写操作主要走主库,事务中的读也要走主库,也要考虑到备库相对于主库的延迟。
4.2搜索引擎其实是一个读库
搜索引擎的倒排表方式能够大大提升检索速度。
搜索引擎要工作,首要一点是需要根据被搜索的数据来创建索引。(索引的是真实数据不是镜像关系。
构建搜索用的索引的过程就是数据复制的过程,只不过不是简单复制对应的数据。
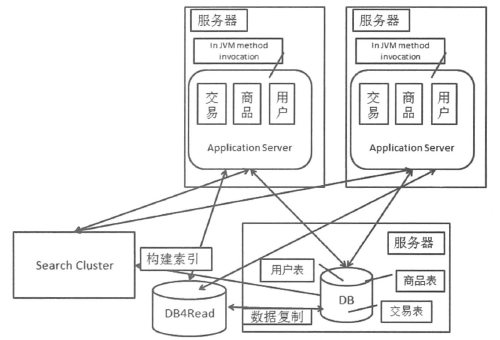
搜索集群的使用方式和读库的使用方式是一样的。只是构建索引的过程基本都是需要我们自己来实现的。
可以从两个维度对搜索系统构建索引的方式进行划分:
- 一种是按照全量/增量划分(全量方式用于第一次建立索引,可能是新建也可能是重建;增量方式用于在全量的基础上持续更新索引。
- 另一种是按照实时/非实时划分(主要体现在索引更新时间上,更倾向于实时方式,非实时方式主要是考虑到对数据源头的保护。
搜索引擎的技术解决了站内搜索时某些场景下的读的问题,提供更好的查询效率。
4.3加速数据读取的利器——缓存
1)数据缓存
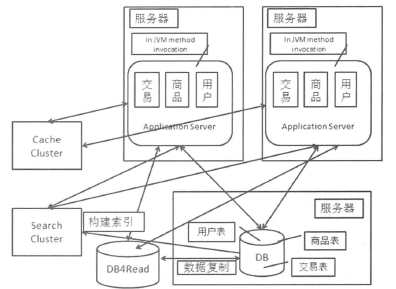
缓存系统一般是用来保存和查询键值(Key-Value)对的。
一般在缓存中存放的是“热”数据而不是全部数据,填充方式通过应用完成:应用访问缓存,如果数据不存在则从数据库读出数据后放入缓存。
当缓存容量不够,最近不被访问的数据就被清除了。
在数据库的数据发生变化后,主动把数据放入缓存系统中。这样做的好处是,数据变化时能够及时更新缓存中数据,不会造成读取失败。
这种方式一般会应用于全数据缓存情况。使用这种方式有一个要求,即根据数据库记录的变化去更新缓存的代码要能够理解业务逻辑。
2)页面缓存
数据缓存可以加速应用在响应请求时的数据读取速度,但是最终应用返回给用户的主要还是页面,有些动态产生的页面或页面的一部分特别热,我们就可以对这些内容进行缓存。
具体实现:
- ESI或类似思路。
- 把页面缓存与页面渲染放在一起处理。
ESI:一种数据缓冲/缓存服务器,它提供将Web网页的部分(页面片段)进行缓冲/缓存的技术及服务。
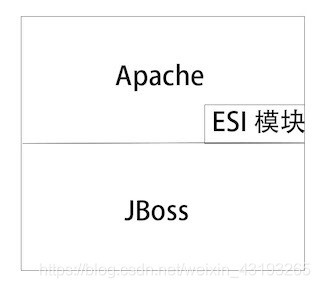
上图表示,对于ESI的处理是在Apache中进行。
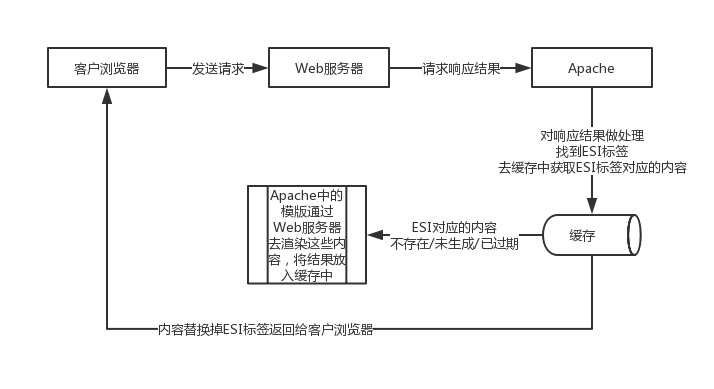
这种方式的职责分工比较明确。
不过Apache的ESI模块总要对响应结果进行分析,然后进行ESI相关操作。
如果在Web服务器处理时就能够直接把ESI相关的工作做完会是一个更好的选择。如下图:

Apache中不再有ESI相关功能,而是在Web服务器中完成渲染及缓存工作。更高效,只是分工没有前一种方式清晰。
对于使用缓存来加速数据的读取情况,一个很关键的指标是缓存命中率,因此缓存命中率较低,意味着还有不少的请求回到数据库中。
同时数据的分布于更新策略也要结合具体的场景来考虑。在分布上,要考虑的问题是需要避免局部热点,并且缓存服务器扩展或者缩容要尽量平滑(一致性hash会是不错的选择)。
而在缓存的更新上,会有定时失效、数据变更时失效和数据变更时更新等策略。
5.弥补关系型数据库的不足,引入分布式存储系统
常见的分布式存储系统有:分布式文件系统、分布式Key-Value系统和分布式数据库。
分布式存储系统起到存储的作用,也就是提供读写支持。相对于读写分离中“读”源,分布式存储系统更多是直接替代主库。分布式存储系统通过集群提供了一个高容量、高并发访问、数据冗余容灾的支持。
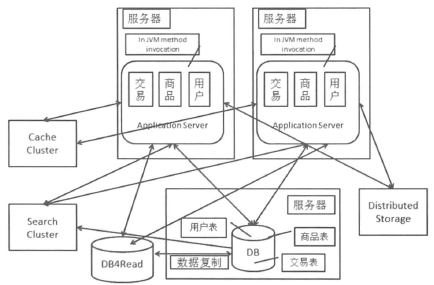
6.读写分离后,数据库又遇到瓶颈
所有的数据都放在一个库里,数据库的压力还在持续增加。
1)专库专用,数据垂直拆分
垂直拆分就是把数据库中不同业务数据拆分到不同的数据库中。
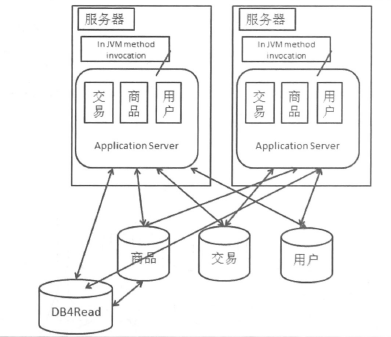
不同业务的数据从原来的一个数据库中拆分到多个数据库中,就需要考虑如何处理原来单机中跨业务的事务。
- 一种办法是使用分布式事务,其性能明显要低于单机事务
- 另一种办法就是去掉事务或者不去追求强事务支持。
对数据库进行垂直拆分之后,解决了把所有业务数据放在一个数据库的压力问题。并且也可以根据不同的业务特点进行优化。
2)垂直拆分后的单机遇到瓶颈,数据水瓶拆分
数据库的水平拆分就是把同一个表中的数据拆分到两个数据库中。
产生数据水平拆分的原因是某个业务的数据表的数据量或者更新量达到了单个数据库的瓶颈,这是就可以把这个表拆分到两个或者多个数据库中。
数据库水平拆分会给业务带来一些影响:
- 首先,要解决SQL路由的问题;
- 其次主键的处理也会变得不同;
- 最后由于同一个业务数据被拆分到了不同的数据库中,因此一些数据查询需要从两个数据库中读取数据,如果数据量较大需要分页就会比较难以处理。

6.数据库问题解决后,应用面对的新挑战
1)拆分应用
前面讲的读写分离,分布式存储,数据垂直拆分和数据水平拆分,都是解决了数据方面的问题。应用也需要拆分。
随着业务的发展,应用的功能越来越多,应用也会越来越大,这是需要把应用拆开,从一个应用变为两个甚至多个应用。

2)走服务化的路
业务之间的访问不仅是单机内部的方法调用了,还引入了远程的服务调用;其次共享的代码不再是散落在不同的应用中了,这些实现被放在各个服务中心。
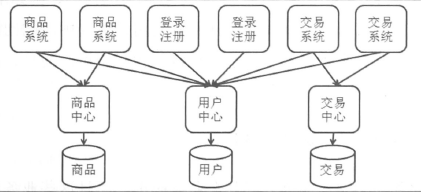
总结

参考:https://www.cnblogs.com/wxgblogs/p/6748608.html
https://blog.youkuaiyun.com/qq_39843374/article/details/81559988

















 2280
2280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









