




 本文探讨了RabbitMQ在不同机房间网络不稳定时的网络分区现象,详细介绍了四种网络分区处理策略:ignore、pause_minority、pause_if_all_down、autoheal,并通过测试验证了pause_minority策略的有效性。
本文探讨了RabbitMQ在不同机房间网络不稳定时的网络分区现象,详细介绍了四种网络分区处理策略:ignore、pause_minority、pause_if_all_down、autoheal,并通过测试验证了pause_minority策略的有效性。
一、背景
目前生产环境RabbitMQ集群分布在铜牛机房和马驹桥机房,其中铜牛机房两个节点,马驹桥机房两个节点;
当铜牛和马驹桥机房之间网络中断或者有较大波动时,RabbitMQ集群会发生网络分区(脑裂),分成两个分区,当网络恢复时,网络分区的状态还是会保持,除非采取一些措施去解决,造成消息消费异常等问题。
二、网络分区处理方式
处理网络分区的方式有两种:
1.手动处理网络分区:挑选一个信任的分区,重启其他分区的节点;
2.自动处理网络分区
RabbitMQ提供了4种处理网络分区的方式,在rabbitmq.config中配置cluster_partition_handling参数即可,分别为:ignore、pause_minority、pause_if_all_down、autoheal
- ignore:默认是ignore,ignore的配置是当网络分区的时候,RabbitMQ不会自动做任何处理,即需要手动处理。
- pause_minority:当发生网络分区时,集群中的节点在观察到某些节点down掉时,会自动检测其自身是否处于少数派(小于或者等于集群中一半的节点数)。少数派中的节点在分区发生时会自动关闭(类似于执行了rabbitmqctl stop_app命令),当分区结束时又会启动。处于关闭的节点会每秒检测一次是否可连通到剩余集群中,如果可以则启动自身的应用,相当于执行rabbitmqctl start_app命令。这种处理方式适合集群节点数大于2个且最好为奇数的情况。
- pause_if_all_down:在pause_if_all_down模式下,RabbitMQ会自动关闭不能和list中节点通信的节点。语法为{pause_if_all_down, [nodes], ignore|autoheal},其中[nodes]即为前面所说的list。如果一个节点与list中的所有节点都无法通信时,自关闭其自身。如果list中的所有节点都down时,其余节点如果是ok的话,也会根据这个规则去关闭其自身,此时集群中所有的节点会关闭。如果某节点能够与list中的节点恢复通信,那么会启动其自身的RabbitMQ应用,慢慢的集群可以恢复。为什么这里会有ignore和autoheal两种不同的配置,考虑这样一种情况:有两个节点node1和node2在机架A上,node3和node4在机架B上,此时机架A和机架B的通信出现异常,如果此时使用pause-minority的话会关闭所有的节点,如果此时采用pause-if-all-down,list中配置成[‘node1’,’node3’]的话,集群中的4个节点都不会关闭,但是会形成两个分区,此时就需要ignore或者autoheal来指引如何处理此种分区的情形。
- autoheal:在autoheal模式下,当认为发生网络分区时,RabbitMQ会自动决定一个获胜的(winning)分区,然后重启不在这个分区中的节点以恢复网络分区。一个获胜的分区是指客户端连接最多的一个分区。如果产生一个平局,既有两个或者多个分区的客户端连接数一样多,那么节点数最多的一个分区就是获胜的分区。如果此时节点数也一样多,将会以参数输入的顺序来挑选获胜分区。
三、方案分析
- ignore:适用于网络很可靠或者只有两个节点的集群;
- pause_minority:适用于三机房,每个机房有一个节点或一个以上的集群;
- pause_if_all_down:适用于三机房,每个机房节点数不一样的集群(比如四个节点);
- autoheal:适用于网络不可靠,只关心服务的连续性而不是数据的完整性。适合有两个节点的集群;
经过对比,采用pause_minority方式比较符合当前场景,以下使用这种方案进行测试。
四、方案测试
1、未加策略前,集群状态正常;
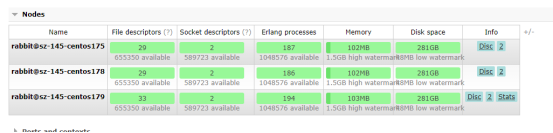
2、添加iptables策略,模拟网络中断;
网络中断后RabbitMQ服务端口还存在(同机房还可以进行读写);
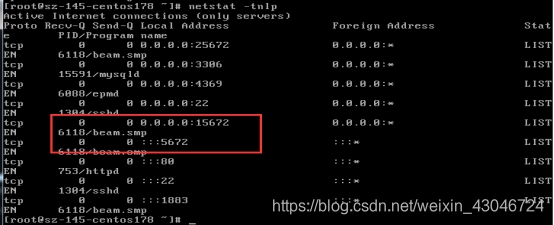
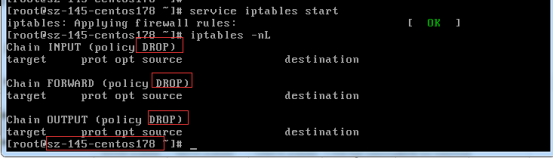
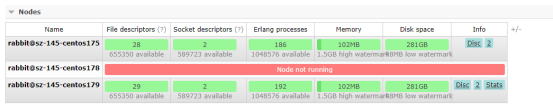
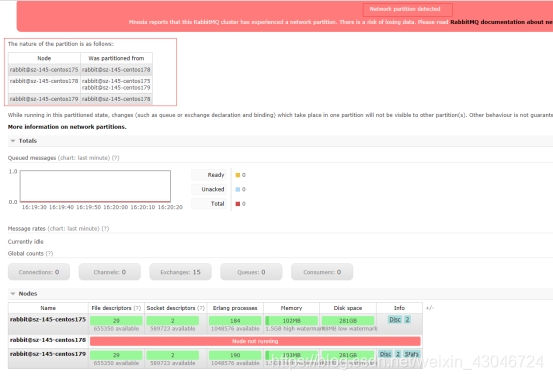
3、关闭iptables策略,检查集群状态,发现集群已经分成两个分区;
重启节点rabbit@sz-145-centos178后集群状态恢复正常。
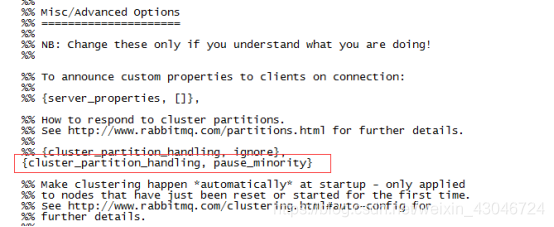
4、修改/etc/rabbitmq/rabbitmq.config配置文件,添加pause_minority策略;
5、逐一重启所有节点,重启过程中集群状态正常;
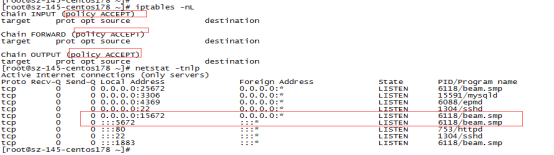
重启完成后再次添加iptables策略,模拟网络中断;可以发现添加策略后网络中断时MQ节点检测到自身属于少数节点,所以关闭自身节点,不提供服务;
6、关闭iptables策略,可以看到该节点RabbitMQ服务自动启动,集群状态也正常;
五、变更步骤
- 太和桥机房新增一台虚拟机,安装RabbitMQ后将节点加入集群;
- 修改/etc/rabbitmq/rabbitmq.config配置文件,添加pause_minority策略;
- 逐一重启所有节点,同时将铜牛机房的一个节点剔除集群,保持每个机房一个节点。


















 1297
1297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









